标签:
上讲,讲述了大概九种的技术种类以及他们的领域。那么既然有吃饭的,那就必须有做饭的。因此大数据技术结构的选型,必须有的组成部分至少三种(来源、计算、存储)
最简单的数据处理架构:
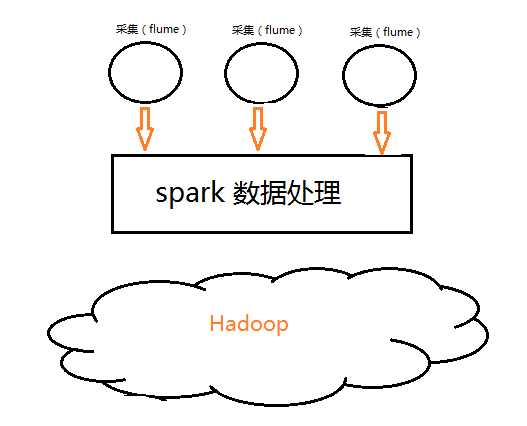
最少单元的数据处理方案,当然这个不是最好的,为什么呢,问题:
1.流式处理数据(Streaming)时,数据量小时,数据存储到HDFS中,20M或者100K,这种情况是有的。这种计算结果的存储极大浪费了存储空间。HDFS不适用于大批量小文件的存储,(只是不适用,不是不能)
2.数据量大时,数据处理不过来(receiver数据接收不过来,崩了,那行我起上几个receiver不就行了,那万一数据量忽大忽小咋办,就挑战你程序极限,咋办?receiver多了浪费,少了不行,没有最优解)
鉴于上面两种问题,怎么办?(这说明上述技术结构不行,那就改),我们学习IO时,有封装管道,大管套小管,相当于有了个缓冲池,效率就高了,鉴于此,我们给技术分块中间加个缓存层(哪个技术能满足要求呢?那当然是消息队列了)
为了提高数据的大小不一,我们需要kafka做数据缓存层
其数据处理结构如下图:
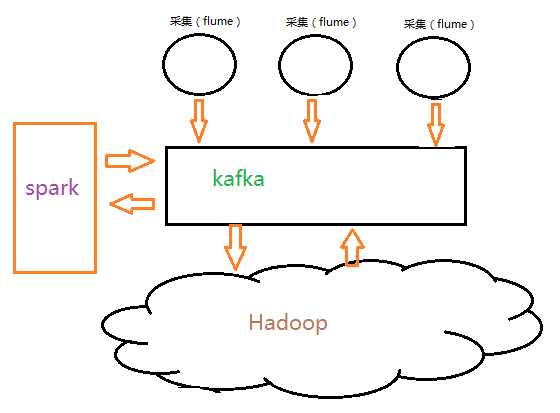
技术结构成为这种形式,这样控制数据流速,交流kafka管理,合理增加receiver(streaming数据接收点)
配置kafka配置文件,认为干预默认配置,可以解决数据倾斜。保证spark集群数据数据接收衡量。将处理后的数据结果,送到kafka中,缓存我们的结果数据,数据量有了积累,持久化到HDFS中,来解决小文件造成存储空间的浪费。
这样就最优了吗?如果是流式计算的话,这样确实不错了,但是也只是不错而已,为什么呢,这样只是对数据处理而已,(数据处理?)当然是,一般而言的数据处理是广义上的,实际中,数据处理是指数据从数据源到数据数据可以分析之前的过程称之为数据处理。数据加工到图表展示是数据分析阶段,这个过程中数据的多维度分析、对比,提取价值曲线,呈现。这在大数据运算中占一半比重,数据挖掘来需要合理的分析才能提取到价值东西,呈现给客户。这样似乎和数据选型没有太明显的关系?
乍一看,是没关系,细想,我们没有大数据这些新生技术时,传统的数据分析都是基于mysql和oracle这种关系型数据库分析的。在实际生产中项目构建时,都是逐步替换的,数据交互的耦合,后台与前端的联系,还是数据库形式数据与数据库形式数据好整合,是故,假若我们要替代传统数据库的大数据内存 分布式可扩展的数据库可以排上用场了。这样的数据处理结构又在会发生改变,如下图:
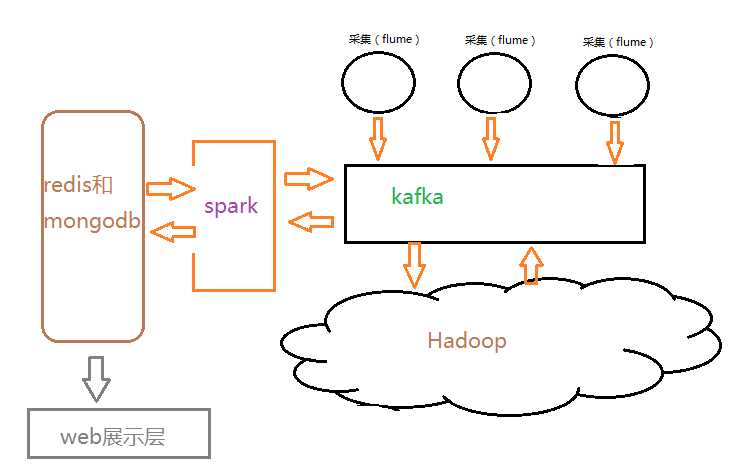
当然在做离线处理时,我们能将数据直接基内存获取,或者说我们数据来源放在内存中,不论是离线计算还是流式计算,都会从磁盘获取历史数据做长周期聚合运算时,这些数据在内存获取必然提高运算效率。这样基于数据的内存管理显得尤为重要,tachyon作为分布式内存文件管理系统,解决了这样一部分问题,其结构如图:
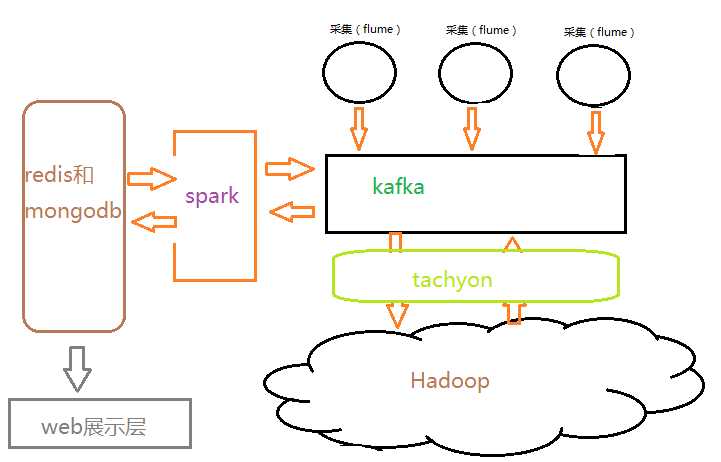
这样数据处理和分析业务,基本完善,优化之后大大提高了运行效率,然而大数据另一种处理场景,当日质量非常巨大是,目标数据的搜索获取又将成数据处理和分析的瓶颈,怎么解决这个问题。hBase作为分布式列式存储的非关系型数据库来说,他更像数据搜索引擎,为什么?(因为他不是基于列搜索,而是行健)其搜索速度也是非常恐惧的,如果你忽略了行健、搞了个UUID,那你来大数据就是来搞笑的,HBase不是数据库,鉴于此,理解为搜索引擎更为切且。
俗话说双拳难敌四手,好汉架不住人多。所以搜索的数据量达到百万级时,速率也会下下降。这样有没有提高的办法呢?有,提高搜索效的唯一办法就是索引,索引的好,查询就更快。为啥呢?(关系型数据到HBase转型就知道了)我们和利用Lucene和solr建立文本搜索引擎,做海量数据的索引和模糊结果基于HBase的精确查找,获取结果。将大批量的查询结果变为精确的小批量搜索,可使HBase的查询速率更快,也可以给用户提供海量原始数据的搜索体验和索引数据处理分析的(精确计算)。其结构如图:

整个大数据处理业务的技术选型,与功能搭配就是如此。你要看到本质搭配,不是说别人用什么,我用什么,实际选型,是根据真实业务场景和生产对接情况。
标签:
原文地址:http://www.cnblogs.com/gnool/p/5645036.html