标签:
还是打算选择python学习spark编程
因为java写函数式比较复杂,scala学习曲线比较陡峭,而且sbt和eclipse和maven的结合实在是让人崩溃,经常找不到主类去执行
python以前没用过但是名声在外,可以很方便的进行数据处理
在eclipse中集成pydev插件去编写python程序已经学习过了
今天使用了一下anaconda集成一起的python开发环境,感觉很不错
尤其是ipython notebook或者称为jupyter notebook很方便的进行可视化
但是如何在pyspark中启动呢
查了一些英文的文献都是在linux下的配置
ipython profile create spark
会创建一些启动需要的配置脚本,在脚本中进行设置之后
ipython notebook --profile spark
就可以在pyspark中启动notebook但是我没有配成功
后来看到一个简单的方法
直接在windows环境变量中增加两个pyspark启动时需要检查的变量即可将python解释环境转移到jupyter notebook
第一个变量是PYSPARK_DRIVER_PYTHON:jupyter
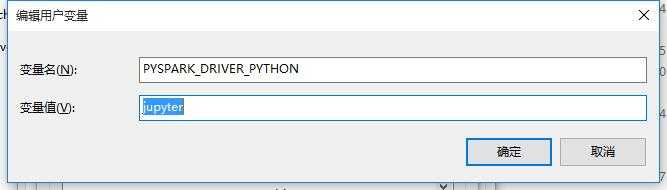
另外一个变量是PYSPARK_DRIVER_PYTHON_OPTS:notebook
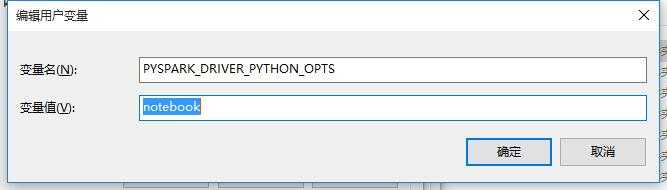
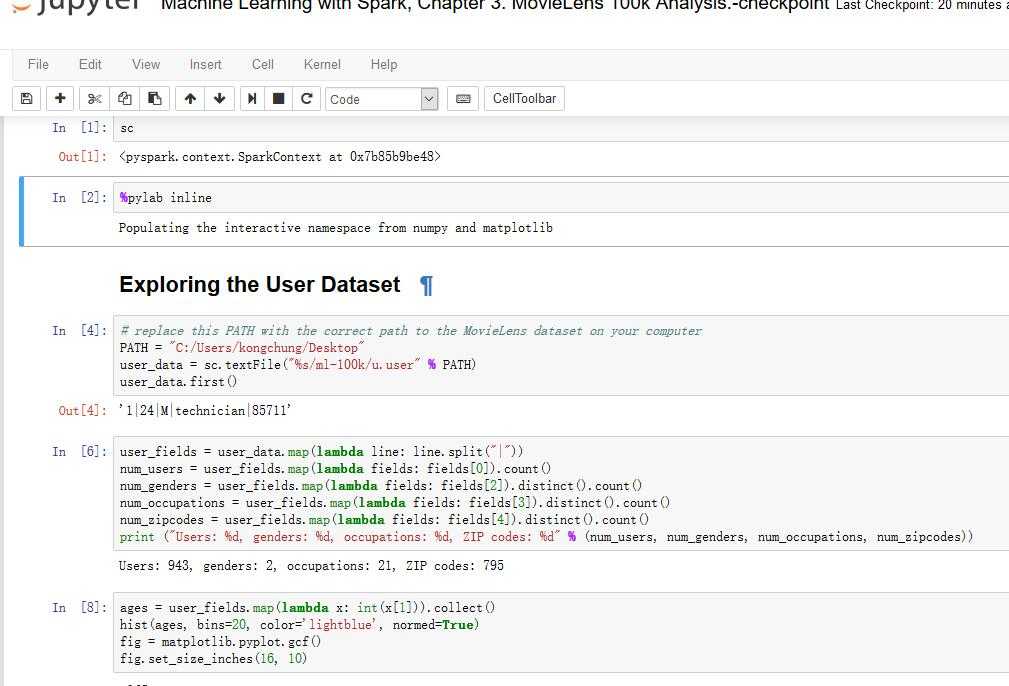
这样从命令行启动的话(双击启动不行)就可以打开一个web服务在notebook中的py脚本就可以运行在spark上了
参考文献:
http://www.cnblogs.com/NaughtyBaby/p/5469469.html
http://blog.csdn.net/sadfasdgaaaasdfa/article/details/47090513
http://blog.cloudera.com/blog/2014/08/how-to-use-ipython-notebook-with-apache-spark/
Spark机器学习 by Nick Pentreath
标签:
原文地址:http://www.cnblogs.com/kongchung/p/5646608.html