标签:
据说大多数汇编器会根据do-while循环来产生代码, 所以其他循环可能会先转化为do-while形式再编译成机器代码, 所以我们首先介绍do-while循环...
do-while的通用形式如图所示 :
loop: body-statement t = test-expr; if(t) goto loop;
这里给出一个实际的例子 :
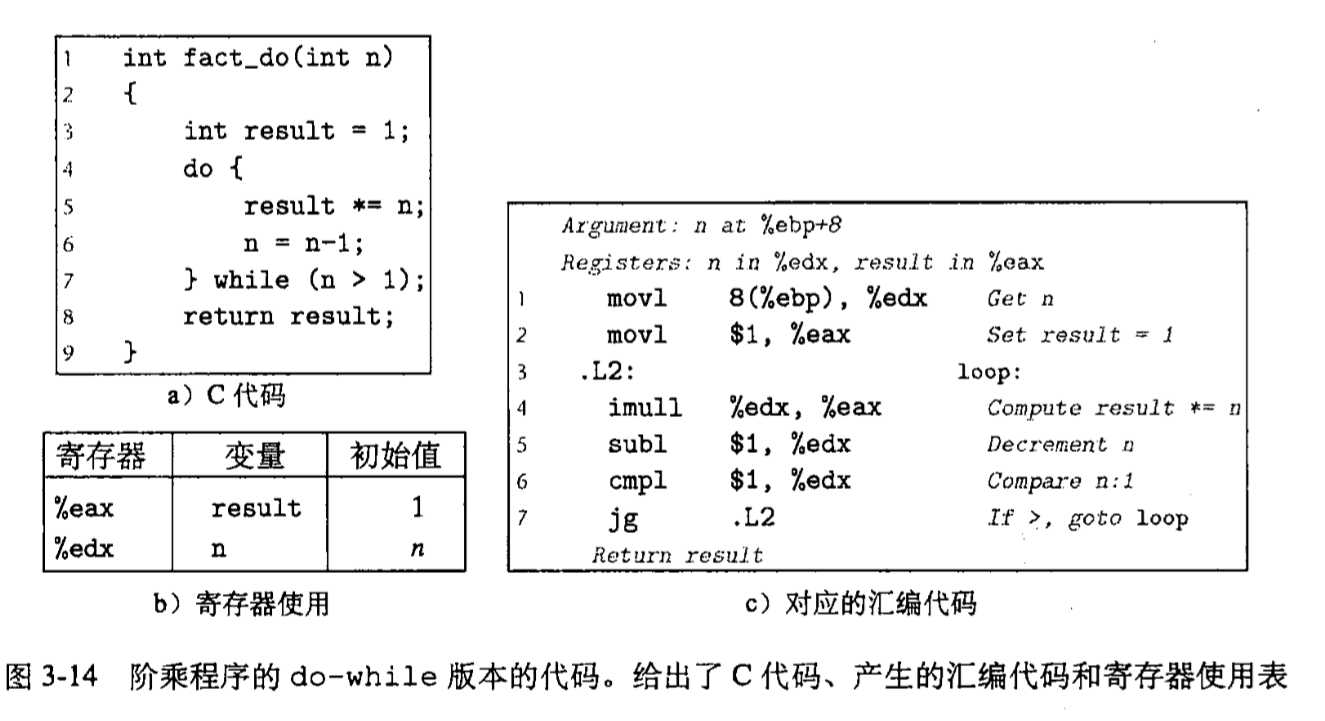
while循环有多种翻译方法, gcc使用了的是 先用if 进行检测第一次循环, 这样就将while转换为了do-while, 具体如下 :
t = test-expr if(!t) go to done loop: body-statement t = test-expr if(t) goto loop done
同样给出一个实际的例子 :

这里有必要提一下这一节的练习题, 对于3.21 我要说的是, 要注意在a变化之后, 不单单代表%ecx的a要发生变化, 代表a+b的%edx也要变(这是因为汇编中我们不可能在一个表达式中直接表达a+b, 所以a+b一节被抽象成了一个临时变量, 所以a更新的时候也要更新a+b)...

对于3.22, 其实这道题我在看了很久才看明白, 本身汇编代码很简单, 很容易翻译, 但是难就难在, 你拿着C代码也不知道他想干什么... 要看懂这道题我觉得你必须从目的入手, 这道题是要求x的二进制表示中有多少位的值是1, 如果这个数量是偶数, 则返回0, 否则返回1, 此时可以分析出最后一行代码其实是掩码, 也就是有用的信息全都保存在val的第一位中. 然后我们可以这样思考 : 第一次循环, 其实是讲x赋值给了val, 然后随着x不停地右移动, 相当于是借助val 完成了对于x中所有位的异或(假设x的值位1010, 那么跳出循环时的val == 1 ^ 0 ^ 1 ^ 0), 同时我们知道自己和自己异或等结果肯定是0, 当有偶数个1时(也就代表其实有偶数个0), 此时异或的结果显然是0(从第二章我们知道异或也符合交换律), 到这里这几行代码的思路就很清晰了...


对于for循环, 它其实可以转换为等价的while循环 :
init-expr; while(test-expr){ body-statement update-expr }
那么显然, 我们可以基于之前的思路, 先将for转换为while, 再while 转换为do-while, 最终它的模板就变成了这样...
init-expr; t = test-expr; if(!t) goto done; loop: body-statement update-expr t = test-expr if(t) goto loop; done;
习题倒是没什么好讲的, 但是这里补充一个知识点, 习题里面多次出现但是书中并没有明确提到的, 就是移位操作其实也可以只有一个操作数, 这时候默认是移位为一, 但是我一直没找到依据, 最后我google之后才看到 :
Unless stated, these instructions can take either one or two arguments. If only one is supplied, it is assumed to be a register or memory location and the number of bits to shift/rotate is one (this may be dependent on the assembler in use, however).
shrl $1, %eaxis equivalent toshrl %eax(GAS syntax).
再来看一个实际使用的例子 :

首先这些指令近代的IA32才拥有更好的支持, 正是因为兼容性问题, 这些指令使用很少, 甚至在过去gcc的默认设置中产生的代码都不产生这些指令, 但是对于近年来的mac以及64位的linux和windows上gcc都会使用这些指令. 那么问题就在于, 对于这些指令, 其实完全可以用条件判断之后跳转的方式实现相同的效果, 那么为什么要费尽波折只用这些看似无意义还不向前兼容的指令呢? 很简单, 为了效率... 要解释这个问题我们必须要先来了解一下现代处理器运行的知识 :
可能你之前也听说过, 现代处理器在运行过程中其实并不是简单的单条指令执行的, 而是每条指令都被分成了很多小部分, 然后多条指令的各个部分分别执行, 通过重叠相同的部分或是提前执行那些不存在前向依赖的部分来提高效率... 那么, 在机器遇到条件跳转时, 机器为了确定下一条指令的位置必须确定是否发生跳转, 确定的方式是分支预测逻辑. 一方面, 如果预测可靠, 那么流水线中充满了该预测方向的指令, 提高了性能; 另一方面, 如果预测失败, 当前流水线中的所有指令都必须放弃, 转而执行另一方向的指令, 这将导致非常严重的性能下降. 而条件传送指令并不需要预测(因为实际上他对于两种情况都进行了计算, 比如 x = condition ? A : B, 那么CPU直接对A, B都进行计算). 所以我们很容易理解的一点是 : 他并不是总能提高效率, 特别是在A 和 B都需要大量计算的时候, 这时候无论最终选择A还是B都会有大量计算浪费. 所以现代编译器必须在两者之间权衡, 书中说通过对gcc的大量实验表明, 只有当两个表达式都很容易计算时, 他才会使用条件传送...
另一方面, 并不是任何情况下都可以使用条件传送, 如下例 :
int cread(int *xp){ return (xp ? *xp : 0); }
如果使用条件传送, 当xp是0的时候, *xp明显是程序员不想看到的, 所以要注意条件传送并不总是通用...
练习题3.2很有意思, 但是如果没有看第二章的话恐怕很难想到.
这一节书的排版个人感觉是有问题的, 所以我重新整理了一下思路之后尽量以比较容易理解的方式来介绍switch语句的汇编实现.
提到switch语句, 很多人认为其与多组if没区别, 其实是有区别的, 区别就在于实现效率... switch采用了一种称之为跳转表的数据结构来完成, 在case 很多或者同时case的值跨度不大的情况下, 就会使用跳转表. 我们先来看看跳转表的C语言实现 :


图b属于gcc的扩展C语法, 它使用&&来表示指向代码位置的指针, 这里引入这个是为了更好地看清汇编的实现... 最终的汇编实现是这样的 :
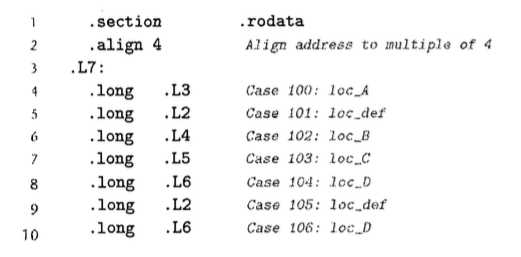

前面是对于跳转表的声明, 这里的.rodata值的是read-only data, 这个跳转表的基地址是.L7, 之后的连续排列的.long(也就是4个字节)的数据, 至于里面的存的数据要到下面标号出现的位置才能确定... 这里标号的顺序有点乱, 但其实仔细看还是能看清楚的... 所以在C语言中如果要实现大量分支的选择, 首先应该考虑switch.
可以来分析一下练习3.28来巩固一下 :
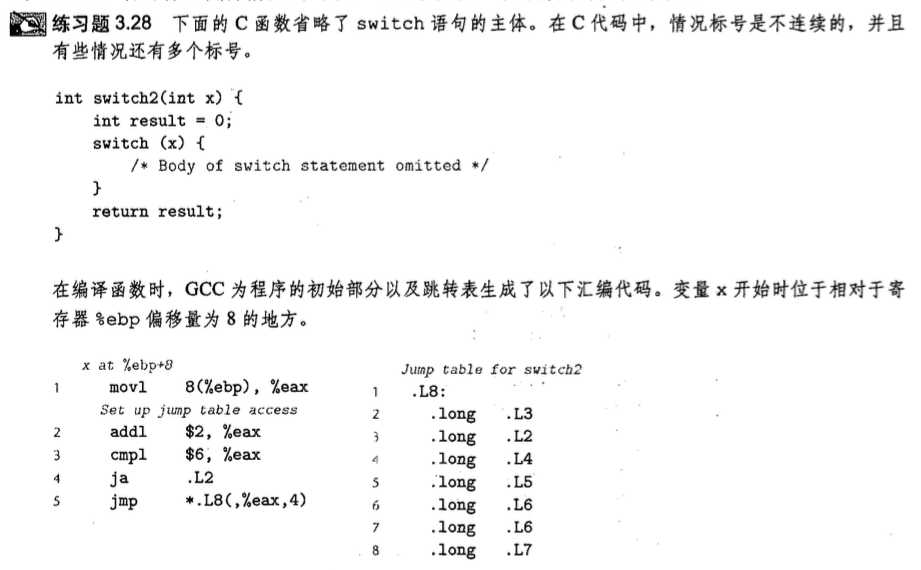
我来讲一下我的思路 :
1. 首先x无缘无故先加了2, 这显然是为了使得每个case的key值更符合从0开始的规范, 从而更好地创建数组(也就是跳转表)... 所以这里可以看出来case中最小的应该是-2...
2. 从x加2之后无缘无故和6比较可以看出这是default的界限, 所以default的界限应该是4...
3. 因为.L2的default的情况, 又对应右边的表中, default还对应jt[1], 所以case 1 应该是不存在的, 所以跳到了default. 所以case 有这么几种 : -2, 0, 1, 2, 3, 4...
标签:
原文地址:http://www.cnblogs.com/nzhl/p/5648030.html