标签:
对数据集movie ml-100k
有用户,电影,评分,时间戳四个数据字段, 以用户-电影组成的评分矩阵R,可以用SVD方法转化成两个因子矩阵P,Q ,用两个因子的乘积R‘来作为原先矩阵的近似,R由于用户看的电影数目及一个电影所能吸引用户的数量,决定了R是稀疏的,然而R‘是R的近似,相对于R是稠密的,因而可以通过减小他们之间的误差来计算得到R‘,进而对于没有看过某类电影的用户给个预估分,这就能直观的看出用户对于电影的兴趣,进而考虑是否推荐
首先是最小化目标函数
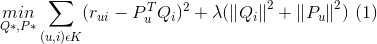
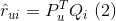
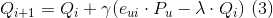
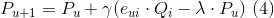
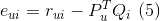
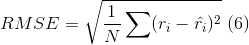
def prediction(P,Q):
return np.dot(P.T,Q)
lmbda = 0.1
k = 20
m, n = R.shape # R是由用户-电影组成的评分矩阵 训练集
n_epochs = 100 # 迭代数
gamma=0.01
P = 3 * np.random.rand(k,m) # 对P,Q 随机取初始值
Q = 3 * np.random.rand(k,n)
# 计算RMSE
def rmse(I,R,Q,P):
return np.sqrt(np.sum((I * (R - prediction(P,Q)))**2)/len(R[R > 0]))
#存储误差,可用matplotlib画图显示误差变化
train_errors = []
test_errors = []
users,items = R.nonzero()
for epoch in xrange(n_epochs):
for u, i in zip(users,items):
e = R[u, i] - prediction(P[:,u],Q[:,i]) # 公式5
P[:,u] += gamma * ( e * Q[:,i] - lmbda * P[:,u]) # 公式4
Q[:,i] += gamma * ( e * P[:,u] - lmbda * Q[:,i]) # 公式3
train_rmse = rmse(I,R,Q,P) # I表示与R相同规模的矩阵,R的元素不为0时相应位置为1,为0置为0
test_rmse = rmse(I2,T,Q,P) # T为R一样,是测试集
train_errors.append(train_rmse)
test_errors.append(test_rmse)
标签:
原文地址:http://www.cnblogs.com/who-a/p/5648558.html