标签:
一. CNN的生物原理,应用以及优点
CNN根据人眼睛视觉神经的局部感受野特点设计,广泛应用在图像图像,模式识别,机器视觉和语音识别中,它对图像平移、缩放、旋转等的变形具有高度不变性。总之,CNN的核心思想是将局部感受野,权值共享,时间或空间子采样这三种思想结合起来获得了某种程度的平移、缩放、旋转不变性。
二. CNN的网络结构
CNN是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
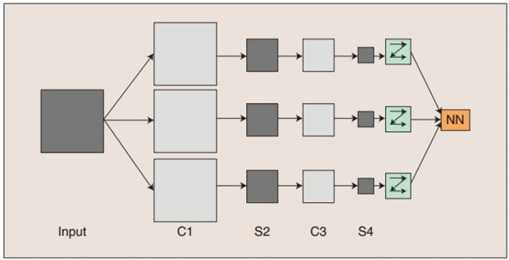
图1 CNN的网络结构
C层为特征提取层,每个神经元的输入与前一层的局部感受野相连接,并提取该局部的特征,一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来。S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。CNN中的每个特征提取层(C-层)都紧跟着一个特征映射层(S-层),这种特有的两次特征提取的结构使CNN对输入样本具有较高的畸变容忍能力。
根据图1,首先输入图像通过和3个卷积核(滤波器)和偏置项进行卷积,在C1层产生3个特征映射图,其次特征映射图再进行操作得到3个S2层的特征映射图,这些特征映射图再进行卷积得到C3层,然后得到S4,最后把这些像素值连接成一个长向量输入到传统的神经网络中,以得到输出。
三. CNN与权值共享
CNN的最大特点在于通过感受野和权值共享减少了神经网络需要训练的参数个数,这个是非常了不起的地方。那么到底什么是权值共享呢?下面接着来看一个具体的例子。
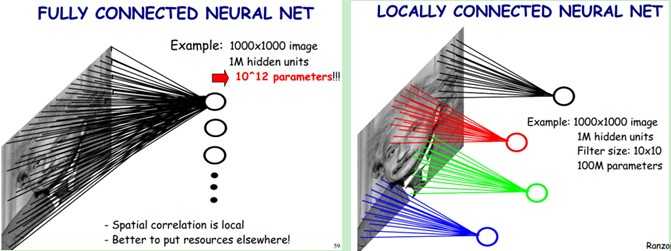
图2 权值共享
根据图2左图,假设我们有1000*1000像素的图像,即100万个隐层神经元,如果全连接(即每个隐层神经元都连接图像的每个像素点)的话,那么就有 1000*1000*1000000=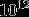 个连接,也就是参数的个数。根据生物原理,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样做的话,我们就可以减少连接的数目,也就是减少神经网络需要训练的参数的个数。
个连接,也就是参数的个数。根据生物原理,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样做的话,我们就可以减少连接的数目,也就是减少神经网络需要训练的参数的个数。
根据图2右图,假设局部感受野是10*10,每个隐层神经元只和这10*10的局部图像相连接,这样100万个隐层神经元就只有10*10*100000个参数。但是参数依然很多,还有什么办法呢?
我们知道,每个隐层神经元都连接10*10个图像区域,也就是说每个隐层神经元存在10*10=100个连接参数。如果每个隐层神经元这100个参数是相同的呢?即每个隐层神经元用的是同一个卷积核去卷积图像。这样我们就只有100个参数。因此,不管隐层神经元的个数,两层间的连接只有100个参数,这就是权值共享的好处。但是,一个疑问随之而来,这样做真的靠谱吗?
其实,这样做我们仅仅提取了图像的一种特征(比如,某个方向的边缘),如果我们想要提取图像的多种特征该怎么办呢?答案是多加几种卷积核(滤波器)。假设现在我们有100中卷积核,每种卷积核的参数不一样,表示提取输入图像的不同特征,每种卷积核去卷积图像就得到对图像不同特征的映射,我们称为特征图。因此,100中卷积核就有100个特征图,这100个特征图就组成了一层神经元。现在我们就可以计算这一层有多少个参数了,即100中卷积核*每种卷积核共享100个参数=100*100=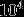 ,也就是1万个参数了。
,也就是1万个参数了。
上面说了隐层参数个数和隐层神经元个数无关,只和卷积核大小和卷积核种类有关。那么隐层神经元个数与什么有关呢?它和原图像(神经元个数)、卷积核大小和卷积核在图像中滑动步长有关。下面举个例子,假设图像是1000*1000像素,卷积核大小是10*10,步长为10(卷积核没有重叠),这样隐层神经元个数为(1000*1000)/(10*10)=100*100。这只是一种卷积核,也就是一个特征图神经元个数。如果100种卷积核,也就是100个特征图,那么神经元个数就是100倍了。当然,如果步长为8,那么卷积核就会重叠2个像素。需要注意的是,上面都没有考虑每个神经元的偏置项,所以参数权值个数需要加1。[一种卷积核共享一个偏置项,这点没有疑问,但是多种卷积核还是共享一个偏置项吗?不是,一种卷积核共享一个偏置项]
四. CNN实例LeNet-5
LeNet-5是一种典型的用来识别数字的卷积神经网络,它共有7层。如下所示:http://yann.lecun.com/exdb/lenet/index.html。
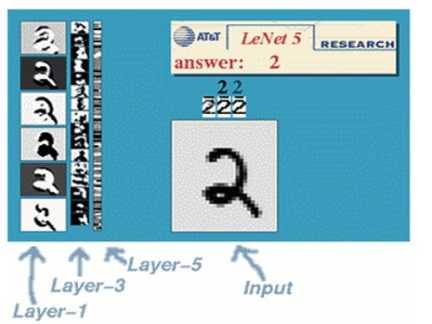
图3 LeNet-5示意图
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。整体上来看,LeNet-5共有7层,不包含输入,每个层有多个特征图,每个特征图通过一种卷积核提取输入图像的一种特征,每个特征图有多个神经元。输入图像为32*32的大小。
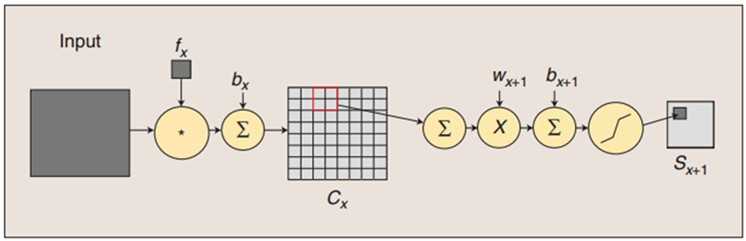
图4 卷积和子采样过程
解析:
(1)卷积过程
用一个滤波器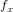 去卷积一个输入的图像,然后加上一个偏置项
去卷积一个输入的图像,然后加上一个偏置项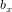 ,得到卷积层
,得到卷积层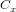 。
。
(2)子采样过程
每邻域4个像素求和变为一个像素,首先通过标量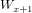 加权,其次加上偏置项
加权,其次加上偏置项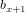 ,然后通过一个sigmoid激活函数产生一个大概缩小4倍的特征图
,然后通过一个sigmoid激活函数产生一个大概缩小4倍的特征图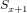 。
。
下面详细地讲解LeNet-5中的每一层,如下所示:
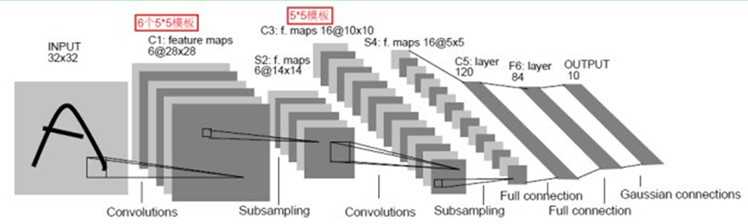
图5 LeNet-5结构图
(1)C1层是一个卷积层(卷积运算一个重要的特点就是可以使原信号特征增强,并且降低噪音)。它由6个特征图构成,特征图中的每个神经元与输入图像中的5*5的邻域相连。特征图的大小为28*28。C1有(5*5+1)*6=156个参数,(5*5+1)*6*28*28=122304个连接。[参数等于卷积核参数加上一个偏置项,再乘以特征图个数。连接数等于参数乘以特征图大小][卷积核其实就是权值参数]
(2)S2层是一个下采样层(为什么要进行下采样呢?因为利用图像局部相关性原理,对图像进行子采样可以减少数据处理量的同时还能保留有用信息),它由6个14*14的特征图构成。特征图中的每个神经元与C1中相对应特征图的2*2邻域相连接。因为每个神经元的2*2感受野并不重叠,所以S2中每个特征图的大小是C1中特征图大小的1/4。S2层有(1+1)*6=12个参数和14*14*(4+1)*6=5880个连接。[池化层与下采样层有什么区别吗?是一样的]
(3)C3层是一个卷积层,它通过5*5的卷积核去卷积层S2,它由16个10*10的特征图构成。但是,卷积的方式有变化,因为C3层的输入是6个特征图,而C1层的输入是一个图像。C3层中的每个特征图连接到S2层中的所有6个或者几个特征图的,表示本层的特征图是上一层提取到的特征图的不同组合(这个做法也并不是唯一的)。
现在肯定会有这样一个疑问,为什么不把S2层中的所有特征图都连接到每个C3层上的特征图呢?一方面是因为不完全的连接机制将连接的数量保持在合理的范围内。另一方面是因为不全连接破坏了网络的对称性。由于不同的特征图有不同的输入,因此迫使它们提取不同的特征。
LeCun采用的方式是:C3层的前6个特征图以S2层中的3个相邻的特征图子集为输入,接下来6个特征图以S2层中的4个相邻特征图子集为输入,然后3个特征图以S2层中的4个不相邻特征图子集为输入,最后将S2层中的所有特征图为输入。如下所示:
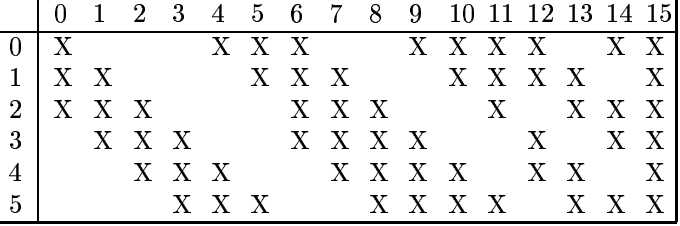
图6 S2层与C3层示意图
C3层有(25*3+1)*6+(25*4+1)*6+(25*4+1)*3+(25*6+1)*1=1516个参数和((25*3+1)*6+(25*4+1)*6+(25*4+1)*3+(25*6+1)*1)*(10*10)=151600个连接。
(4)S4层是一个下采样层,它由16个5*5的特征图构成。特征图中的每个神经元与C3中相应特征图的2*2邻域相连接,根S2和C1之间的连接一样。S4层有16*(1+1)=32个参数和5*5*(4+1)*16=2000个连接。
(5)C5层是一个卷积层,它通过5*5的卷积核去卷积层S4,它由120个1*1的特征图构成,即S4和C5之间的全连接。C5层有(5*5*16+1)*120=48120个参数和48120*1*1=48120个连接。
(6)F6层有84个神经元(选择这个数字的原因是来自于输出层的设计),与C5层全连接。就像经典的神经网络一样,F6层计算输入向量和权重向量之间的点积,再加上一个偏置项,然后将其输入给sigmoid激活函数产生相应的输出。F6层有(120+1)*84=10164个参数和10164个连接。
(7)输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类[0-9]一个单元,每个单元有84个输入。
说明:从一个平面到下一个平面的映射可以看作是卷积操作,S层可以看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的特征图递增,这样可用于检测更多的特征信息。
五.CNN训练过程
CNN的训练过程与BP算法差不多,主要包括4步,这4步又被分为两个阶段,如下所示:
1. 第一阶段,前向传播
(1)从训练集中取一个样本 ,将
,将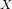 输入网络;
输入网络;
(2)计算相应的实际输出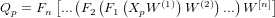 。
。
2. 第二阶段,后向传播
(1)计算实际输出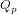 与相应的理想输出
与相应的理想输出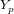 的差值;
的差值;
(2)按极小化误差的方法反向传播调整权值矩阵。
参考文献:
[1] 卷积神经网络:http://www.cnblogs.com/ronny/p/ann_03.html
[2] 卷积神经网络:http://ibillxia.github.io/blog/2013/04/06/Convolutional-Neural-Networks/
[3] 一文读懂卷积神经网络CNN:http://dataunion.org/11692.html
[4] 卷积神经网络算法的一个实现:http://www.cnblogs.com/fengfenggirl/p/cnn_implement.html
[5] 卷积神经网络CNN:http://blog.sina.com.cn/s/blog_628b77f80102v3ud.html
[6] Mariana CNN并行框架与图像识别:http://djt.qq.com/article/view/1239
[7] 卷积神经网络:http://blog.csdn.net/zouxy09/article/details/8781543/
[9] 卷积特征提取与池化——处理大型图像:http://www.tuicool.com/articles/eyaQzeM
[10] Notes on Convolutional Neural Networks
[11] 池化方法总结:http://demo.netfoucs.com/danieljianfeng/article/details/42433475
[12] Deep Learning:http://blog.csdn.net/liulina603/article/details/44216677
[13] Deep Learning的常用模型或者方法:http://www.xuebuyuan.com/1541870.html
[14] CNN学习:http://www.docin.com/p-758296611.html
[15] Convolutional Neural Networks卷积神经网络:http://www.gageet.com/2014/0878.php
[17] handwriting:http://wenku.baidu.com/link?url=CMvf2VGogywWA-vzzdeyfwlMJBITamPBOHy4rkZsfWZnuNCTHst24GmTX0lOnseXndPL0whTOE5xvMJSb-NkOaKp_UEVHqZDn3F5P05ioHy
标签:
原文地址:http://www.cnblogs.com/shengshengwang/p/5648575.html