标签:
在分布式存储系统中,数据需要分散存储在多台设备上,数据分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。数据分片要达到三个目的:
数据分片一般都是使用Key或Key的哈希值来计算Key的分布,常见的几种数据分片的方法如下:
通过上面的对比,在这个系统选择一致性哈希的方法来进行数据分片。
为了让系统有更好的扩展性,这里提出存储层VServer(虚拟服务器)的概念,一个VServer是一个逻辑上的存储服务器,是分布式存储系统的一个存储单元,一台物理设备上可以部署多个VServer,一个VServer支持一个写进程和多个读进程。
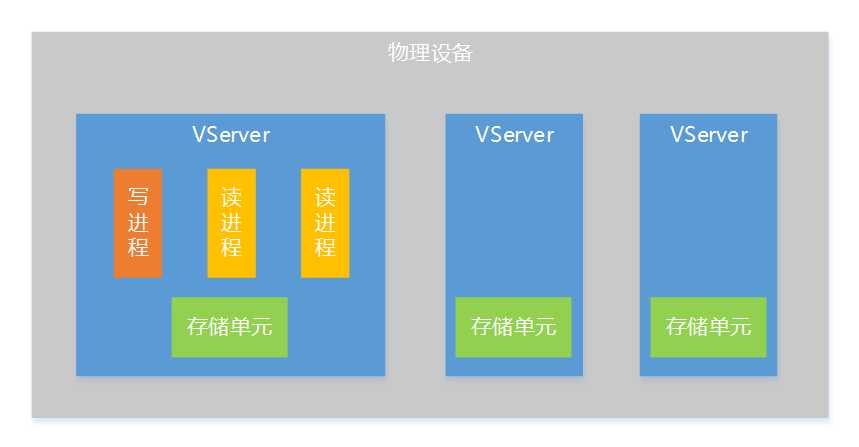
通过VServer的方式,会有下面一些好处:
数据分片是在接口层实现的,目的是把数据均匀地划分到不同的VServer上。有了接口层的存在,逻辑层寻址就轻量了很多,寻址存储层VServer的工作全部由接口层负责,逻辑层只需要随机选一个接口层机器访问即可。
接口层使用了一致性哈希的割环算法来实现数据分片,在割环算法中,为了让数据均匀分布到各个VServer,每个VServer需要有多个VNode(虚拟节点)。一个Key寻址的过程如下图所示,首先根据Hash(Key)在哈希环上找到对应的VNode,在根据VNode和VServer的映射表确定所属的VServer。
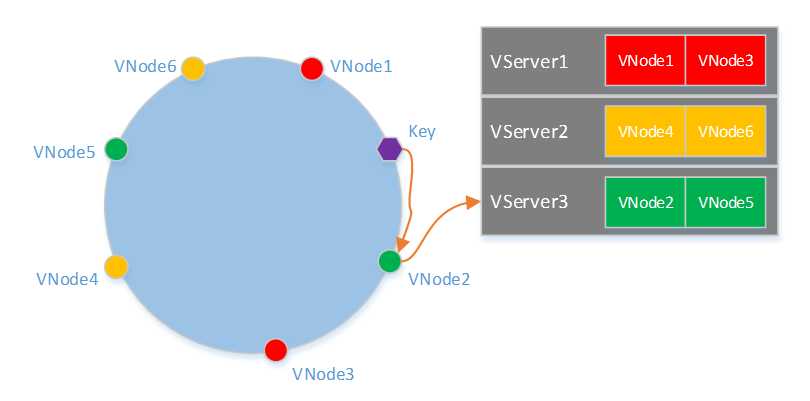
由上述查找过程可知,需要事先离线计算出VNode在哈希环上的分布、VServer和VNode映射关系。为了是计算结果具有通用性,即在拥有任何数量VServer的一个系统都可以使用该结果得到一致性哈希的映射表,这就要求结果是与机器无关的,比如不能使用IP来计算VNode的哈希值。在计算前需要确定每个VServer包含的VNode数量,以及一个系统所支持的最大VServer数量。一个简单的方法是类似上文链接中提到的方法,但不能和IP相关,可以改用VServer和VNode的编号来计算哈希值,如Hash("1#1"),Hash("1#2")… 这种方法要求一个VServer包含的VNode的数量比较多,大概需要500个才能使各个VServer上的数据比较均匀。当然还有其他的一些方法做到一个VServer上包含更少的VNode数量,并且让数据分布偏差在一定范围内。
Google提出了一种新的一致性哈希算法Jump Consistent Hash,此算法零内存消耗,均匀分配,快速,并且只有5行代码,优势非常明显,详细介绍见此处http://my.oschina.net/u/658658/blog/424161。和上面介绍的方法相比,一个最大的不同点是,在扩容重新分布数据时,在上面的方法中,新机器的一个VNode上的数据只会来自一个老机器上的VNode,而这种方法是会来自所有老机器上的VNode。这个问题可能会导致一些设计上复杂化,所以使用的时候要慎重考虑。
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5654789.html