标签:
Flink一般架构和处理模型
本文翻译自General Architecture and Process Model
---------------------------------------------------------------------
当Flink系统启动时,首先启动JobManager和一至多个TaskManager。JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个TaskManager会启动在同一个JVM中。
当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的(parallel data flow)形式,交给JobManager和TaskManager执行。图1展示了在系统交互中各个组件的角色。
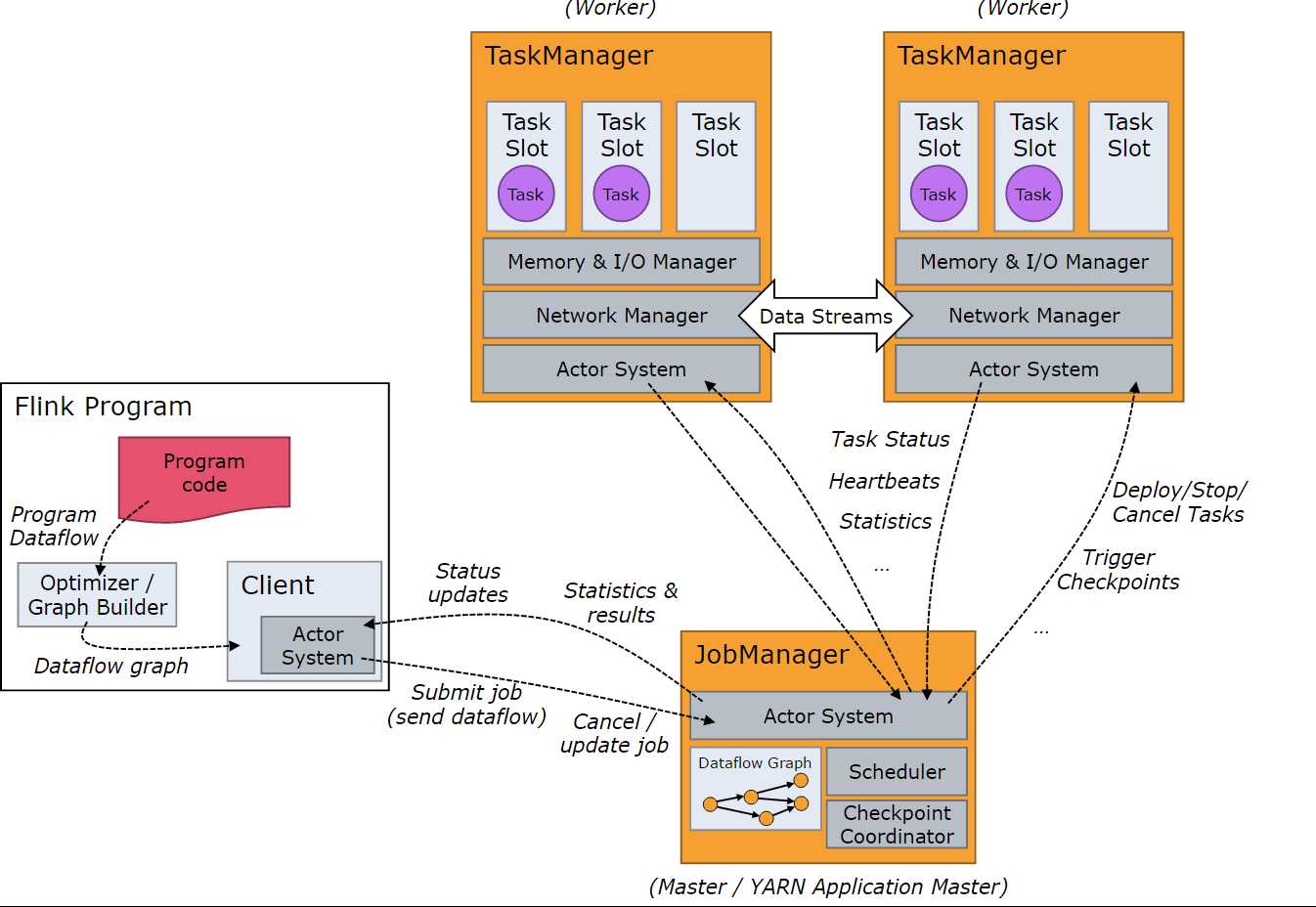
图1Flink运行时各组件关系
Flink以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式:
o 运行时层以JobGraph形式接收程序。JobGraph即为一个一般化的并行数据流图(data flow),它拥有任意数量的Task来接收和产生data stream
o DataStream API和DataSet API都会使用单独编译的处理方式(Separate compilation process)生成JobGraph。DataSet API使用Optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
o 在执行JobGraph时,Flink提供了多种候选部署方案(如local,remote,YARN等)
o Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,事件处理的CEP
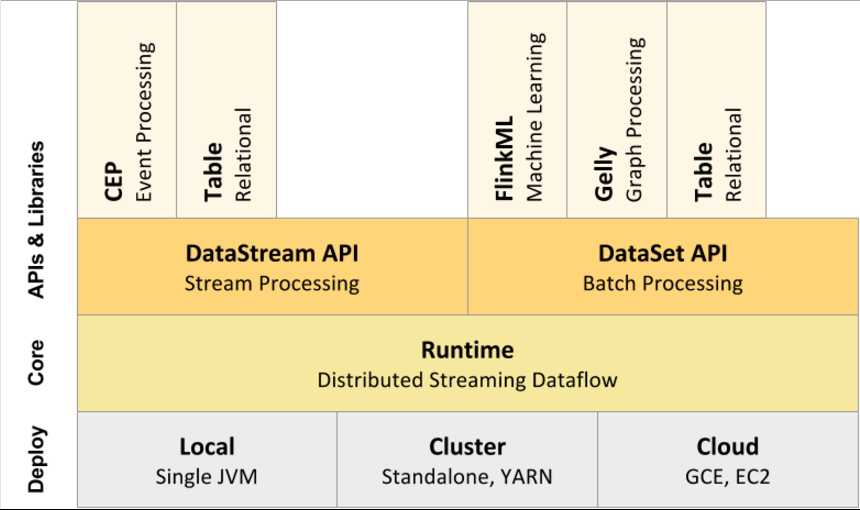
图2Flink组件栈
Flink系统核心可分为多个子项目。分割项目旨在减少开发Flink程序需要的依赖数量,并对测试和开发小组件提供便捷。
独立的工程和依赖关系如图3所示
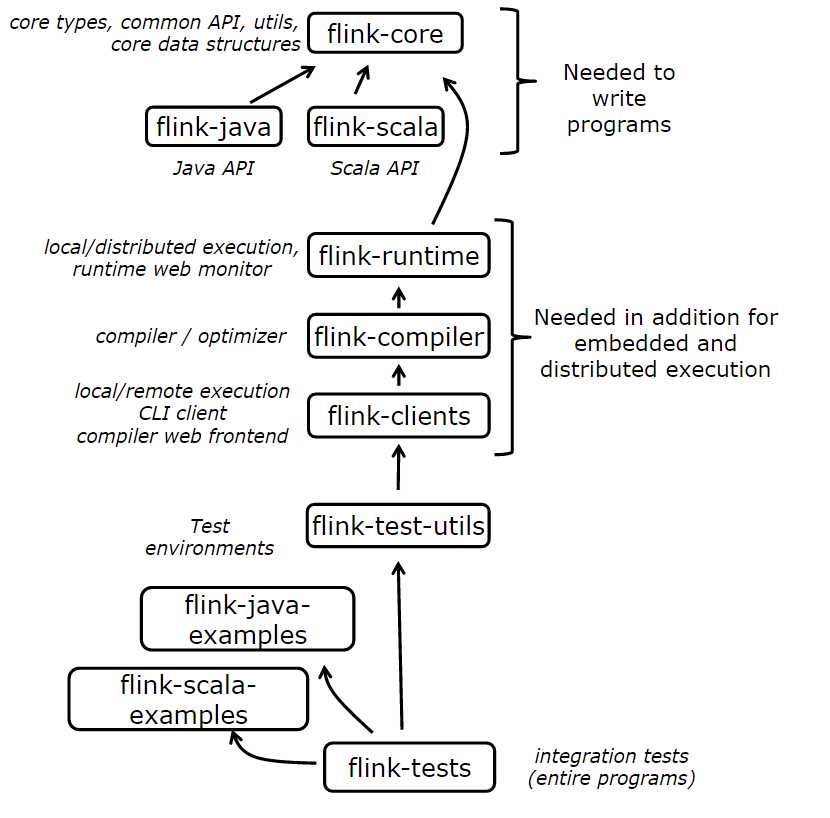
图3Flink子项目和依赖关系
此外,除了图3列出的项目,Flink当前还包括以下子项目:
o Flink-dist:distribution项目。它定义了如何将编译后的代码、脚本和其他资源整合到最终可用的目录结构中。
o Flink-quick-start:有关quickstart和教程的脚本、maven原型和示例程序
o flink-contrib:一系列有用户开发的早起版本和有用的工具的项目。后期的代码主要由外部贡献者继续维护,被flink-contirb接受的代码的要求低于其他项目的要求。
标签:
原文地址:http://www.cnblogs.com/lanyun0520/p/5657697.html