标签:
写一个小的scrapy project,爬取相关网页内容并保存为.json文件
0.创建project,genspider等。
1.修改items.py,内容如下:
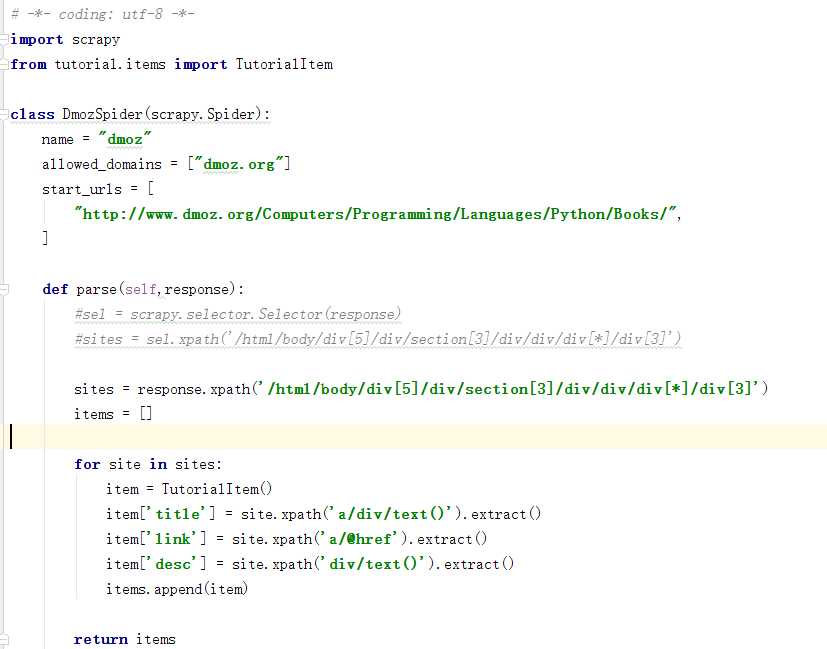
2.修改dmoz.py,内容如下:
3.运行爬虫,结果如下:
已成功爬取到网页内容,并保存为.json格式文件。
scrapy1.1入门用例简介-2
原文地址:http://www.cnblogs.com/flyinghorse/p/5658201.html