我们先看第一个话题,就是Borg是什么?它解决了什么问题?我们看一下这张图,这张图来自于一部电影叫做《星际迷航》相信大家大部分人都看过。Borg是里面的一种外星人,反派,他做什么事情呢?他和其他的文明接触,把你这个文明抢占下来,然后它会和你同化,会把你进行改造,把你改造成一个半人半机器的怪物,你就变成他们这个文明当中的一部分,然后他在这个宇宙当中不断的扩张下去。我觉得这是一个非常酷的种族。而Borg就以这个名字来命名其大规模分布式的集成管理系统。他希望他们的系统也可以把不同的机器同化掉,变成他们自己的机器,然后运行他们自己的程序。

对谷歌来说,Borg是一个比较顶层的集成管理系统。在它上面跑了谷歌大部分的应用程序和框架包括Gmail、Google Docs、Web Search这样直接面对客户的一些应用程序。它同时也包括一些底层的框架,(MR),包括它的一些GFS这些分布式的存储系统。也就是说你可以认为所有的应用程序都需要通过它来管理底层的这些物理机。Borg在谷歌已经成功的应用的十多年。
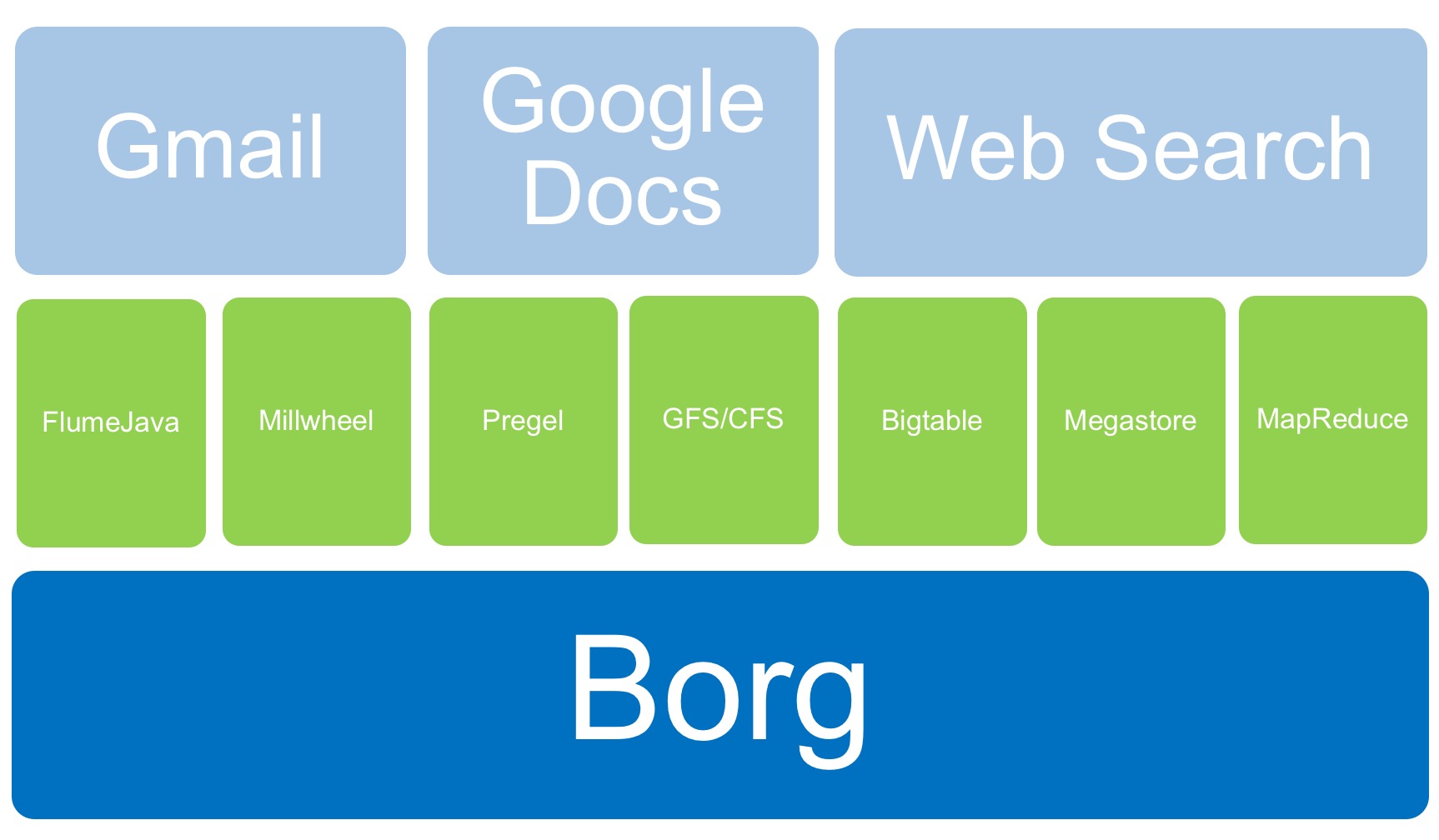
大家可以看一下Borg的整体的架构。它也是一个典型的分布式平台的架构,就是一个逻辑上的master,然后下面有很多的节点,每一个节点上有一些它的代理程序。这里就可以看一下,作为谷歌内部的一个工程师怎么样用这个系统呢?他们使用Borgcfg(命令行)或者Web UI提交需要跑的应用(Task) 到系统,Task可以是任何一种东西,比如说他是一个应用程序,或者是一个批处理任务,或者是一个(MR)的任务。他把这个任务通过Borgcfg提交到BorgMaster,然后BorgMaster会接受这个请求,把请求放到队列里面去,并由Scheduler来扫描这个队列,查看这个应用的资源需求,并在集群中寻找匹配的机器。你其实提交的这个任务,它需要多少的资源,你需要怎么样的机器,大概要跑多少时候,他会做一个匹配,就会看到底层有哪些机器是空闲的。然后就把这个任务发配到这个机器上面去,然后开始运行。
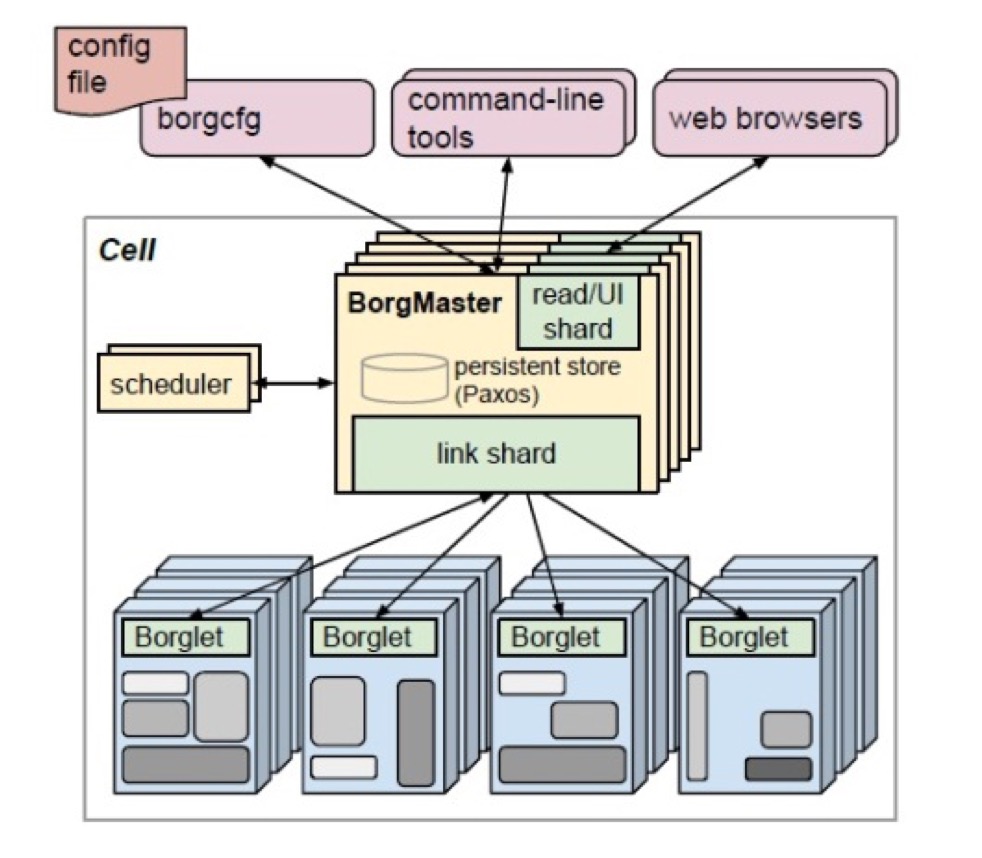
这个就是总体的一个Borg的框架。一个典型的启动时间,从用户提交应用到应用启动是25秒。其中80%的时间是每个节点上下载这个应用包的时间。大家可以看到这个时间是很快的,它的调度时间还不到5秒,其中20秒是耗在传输这一层上。
我后面主要想探讨一下,我今天想说的一个重点就是关于BorgMaster,它这里有很多应用,它怎么样调动这个应用的优先级呢?或者说到底哪台机器应该跑什么应用呢?Borg的做法就是对单个Task做了一个资源上的估量,大家可以看到这里有好几条线,其中一个机器上面最外面的那条虚线就是用户提交的一个资源的一个配额,就是Task再怎么运行也不能超过它的限制,这是一个硬性的限制,如果说超过这个限制,就会限制它,不让它跑。这只是用户提交的数字,大家知道用户提交的数字很多时候是不准确的,你无法预估到底你的程序在你的系统上需要耗多少CPU,占多少内存。Borg是怎么去评估这个资源呢?他在Task启动300秒之后,就进行一个资源回收的工作。大家可以看到中间有一个黄色的区域,黄色的区域就是这个应用程序实际上所消耗的资源。然后它会从外面,慢慢把它推进去,推到绿区的地方,推到绿区的地方划一条线,这条线就是所谓的保留资源,就是Borg这个系统认为你这个应用是长期稳定运行的所需要的资源。
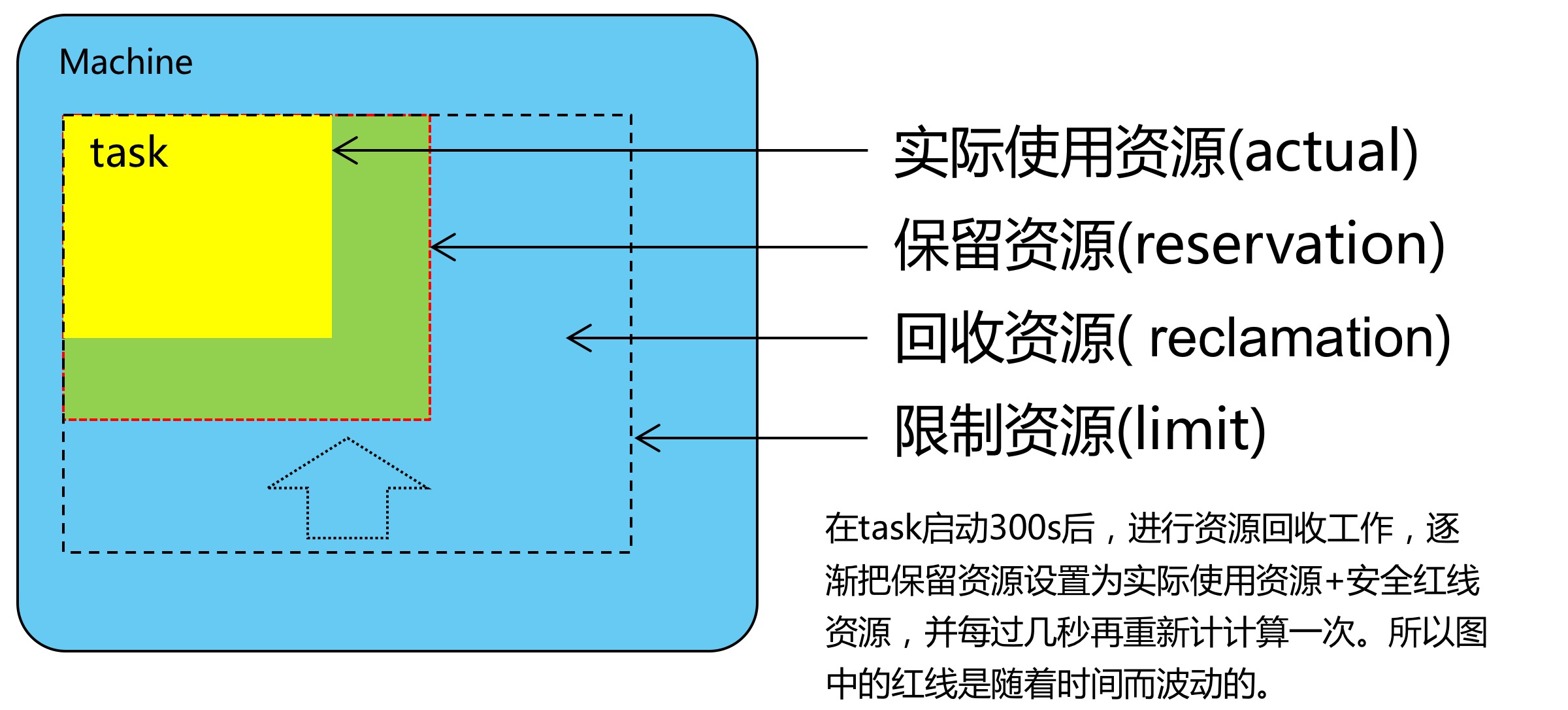
这里就有一个问题,为什么Borg要这么做呢?原因是为了把剩下的区域的资源给空出来,如果说我知道这个应用实际上就用了这么多的资源。然后我给它划了一定的安全线之后,剩下的这些资源我就可以调度出来,也就是说可以给到其它的应用程序用。
绿色的这一块是黄色的块加上一些安全区组成的,每过几秒重新计算一遍应用程序耗费了多少资源。这实际上是一个动态的过程,它并不是说划走了之后就再也不能变了。绿色的方块是可以一直拓展到外面的虚线的范围之内。这就是对单个Task做的一个策略。然后通过他对系统上跑的应用做了一个区分。就是说,他先想了一下,到底有哪些应用,这些应用有什么样的特性。其中有一类应用就是所谓的生产型的应用,就是prod task,其特征就是永远都是不停止的,他是一个长进程,它永远是面向用户的,比如说Gmail或者是Web Search,它中间不可能断的,它的响应时间是几微秒到几百毫秒。然后这种任务就是说,你必须要优先保证它的运行,它的短期性能波动是比较敏感的。
还有一类任务就是所谓的non-prod task,他是一个批处理任务,类似像Map Reduce,它不是直接面向用户的,对性能不是非常的敏感,跑完了就完了,下一个再跑就是下一个任务了,不是一个长进程。

当prod task的资源任务消耗比较大的时候,比如说很多人突然都来上一个网站,这个网站的服务器内存CPU就会非常高。这个时候,在这台机器上应用资源不足的时候,他就会把Non-prod task杀掉,杀掉之后让它去其他的机器上去运行。但是在空闲的时候,就可以让任务继续回来。这样的话,我就可以充分利用这台机器上的所有时间点上的资源,可以把这些东西塞的比较满。最后谷歌的测试结果是,大概20%的工作负载可以跑在回收资源上。这个数据其实是非常大的。对谷歌有那么多台的机器,你可以省下20%的资源,对它来说就是非常非常多的钱。
我这里稍微总结一下,Borg这套系统给谷歌提供了什么样的价值。它主要是提供了三个方面。第一个是隐藏的资源管理和故障处理的细节,让用户可以专注于应用开发。用户不用操心底层的系统是怎么操作的,就算我挂了他也会帮我启起来。第二个是本身提供高可靠性和高可用性的操作,并支持应用程序做到高可靠高可用。第三个是在数以万计的机器上高资源利用率运行。
对于Borg具体怎么做到这三个方面,google有一篇很长的论文《在Google使用Borg进行大规模集群的管理》,里面有很多细节,今天就不展开说了。
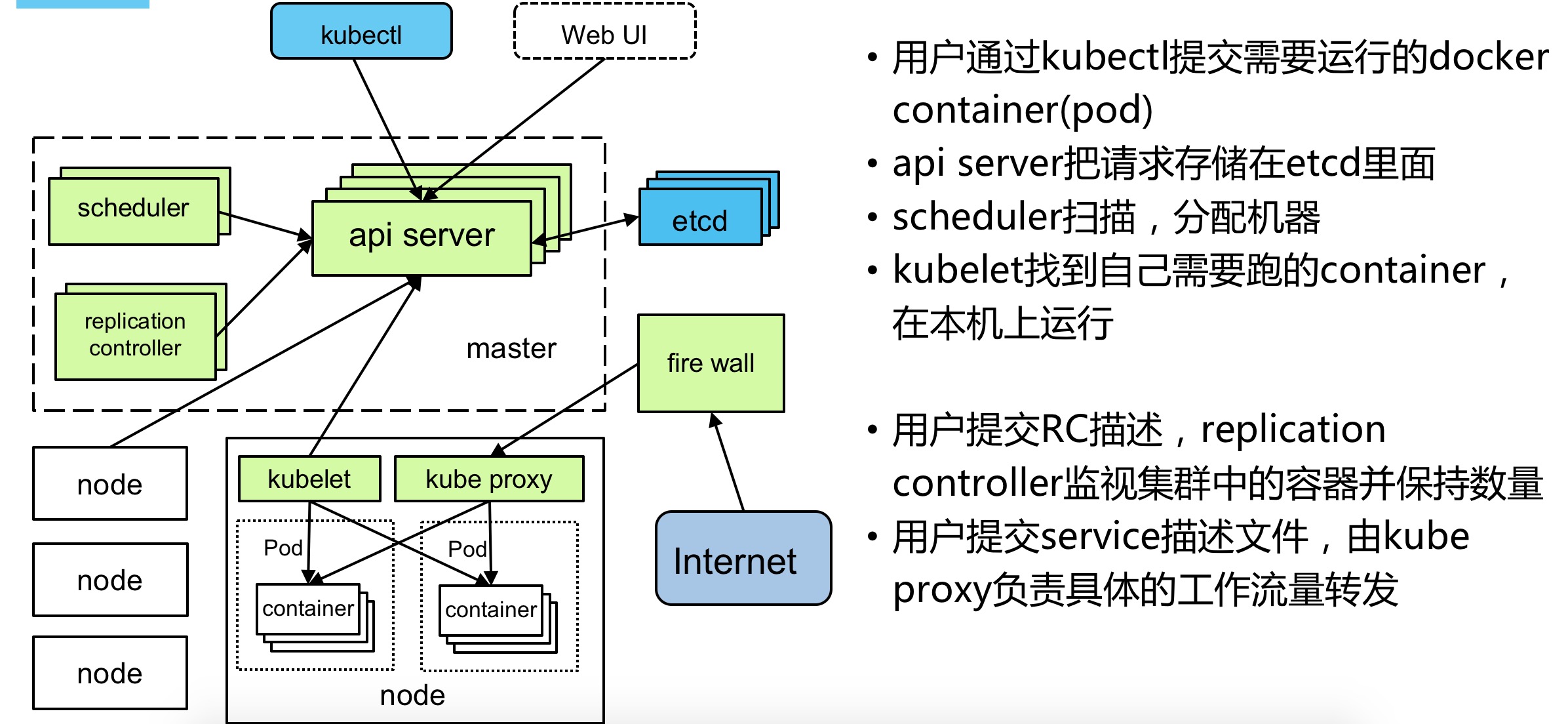
自从谷歌把Borg这个系统推出之后,对内部来说是非常成功,但是在外面的社区,其实大家都不知道这个东西到底是怎么做的,也不知道他内部是怎么实现的。后来做Borg的那批人他们就做了另外一个软件,这个软件就是Kubernetes,Kubernetes总体而言你可以认为是Borg的一个开源的版本,但是Kubernetes和Borg有一些不一样,我后面会大致的讲一下。这是Kubernetes的架构,大家其实可以看到,它的这个架构和Borg的架构基本上是类似的,包括用户怎么用的也是类似的。用户通过用kubectl这么一个命令行工具,把任务提交上来。
Borg在谷歌已经运行了十年,而且机器的规模量非常大,他一个集群就是一万台,甚至更多。而Kubernetes是2014年才出来的,我个人认为这是针对亚马逊,亚马逊的公有云非常的成功,谷歌也想进入这个领域,他的方式就是把Kubernetes这个系统开源推出来,在业界产生一定的影响力,让大家都去用。这样的话,后面就可以和亚马逊竞争一下,这是我个人推测他们的一个想法。
Borg底层用的是lxc的容器,而Kubernetes是用的Docker容器。Borg是用C++编写的,Kubernetes是用Go语言编写的。Borg在集群调度的性能上做了很多的优化,Kubernetes还没有做非常多的优化,目前他在这方面还是比较土的,后面还有很多工作需要做。Borg的单集群能够调度的机器有上万台,而按Kubernetes目前只能支持几百台,这是目前的数据。
然后我们再看一下,对于这两个系统的用户来说它们有什么区别。Borg的用户其实就是谷歌的一批工程师,大家也知道谷歌工程师都是世界比较顶尖的工程师,他们在写这个程序的时候就考虑过程序会跑在云上,他知道这个程序是分布式的。他在写这个应用的时候,就会针对这个系统做非常多的优化,在设计的时候就知道我应该做一个分布式的系统。但是Kubernetes他想做的事情更多一些,就是除了运行这些分布式的系统之外,他还想就是说能够支持一些,他首先是支持Docker的这些容器,但是他还希望支持一些比较传统的,比较菜的,技术水平一般的人写的这些应用程序。他在这方面做了一些工作。一个是用了Docker容器,这样的话就支持很多东西了。还有内他还可以挂载外部的持久层,就是你可以把一些分布层面的系统挂在那个系统上面。我的容器就去读取外部的分布式的存储。这样的话,我这个容器就算是挂了,我这个数据也可以比较安全的保存。另外他就提供了一些监控还有一些日志的功能。但是这些功能是不是够呢,这还是有一定的疑问的。后期如果说我想用Kubernetes来跑一些传统的应用,那我肯定还会对这些应用和系统做一定程度的改造,但至少没有困难到无法完成。
这个是它Kubernetes设计上的一些特色,Kubernetes的网络架构是每一个Pod都有一个单独的IP,这样的应用更加友好一些。写应用程序的人就不用考虑冲突这种情况。还有就是它分组的模式,就是我这些容器如何分组。Borg是一个比较专家的系统,他有230多个参数,但是Kubernetes是非常简单的大概就是三四个描述文件就完了。
这里就是我对Borg和Kubernetes的一个形象化的总结。Borg就是一个喷气式飞机的驾驶系统,非常的专业和高大上,他适用于谷歌这样的大公司,它有几百万的机器。Kubernetes是一个它的简化版,它是一辆设计优良的轿车,它适合中小型公司,用它来对自己的集群进行调度。
未来Kubernetes这边也会做一些相应的工作,包括多租户支持,包括容器持久化、集群规模的提升、利用率和网络方面的等等。

最后可以说是我个人的一些思考。我们未来的云到底需要什么样的东西。大家可以看到,自从计算机风靡以来,有很多的系统,很多的软件,一波又一波的起来,有一部分的系统或者说软件是比较成功的,可以长久存在下去,比如说像Java、或者是C,或者是像Windows这样,还有一些系统非常不幸,像Cobol或者是DOS或者是Minix这些系统,它们慢慢的被人所遗弃,慢慢被人所遗忘,最后变成废弃的停车场。
我这里想考虑一下,如果说再过十年,我们现在在用的一些技术,像Kubernetes或者是Borg这样的技术,是会进入到左边这个行列还是右边这个行列呢?我个人是希望进入左边的行列,毕竟我们还是希望他可以成为一款经典的产品。至少对这些系统来说,我们会非常自豪,我们做了一款比较经典的产品,可以长久的被人们所使用下去。
如果说想做到这一点,就得面对我们现在这个时代,整个计算机系统所面临的一个困境,或者说我们集群管理系统所面对的一个困境。这个困境是什么呢?就是这里所展示的Babel塔的困境。在以色列那个地方,这是一个圣经的故事,人们想造成一般座通天之塔,他们想挑战上帝的权威。上帝一看你们这批凡人,就觉得你们这批鸟人居然敢挑战我的权威,他就发明了各种语言,一起做巴别塔工作的人就各自使用不同的语言,他们就无法交流,最后这个塔就造不下去了。
其实在计算机的世界也是如此,大家使用各自的语言,各自的框架,最后使我们合作起来非常的复杂。包括我们的集群管理系统也好,包括其他的系统也好,其实都是帮助我们跨越这个鸿沟,帮助我们大家可以比较好的进行合作。但是目前来说,还没有一个非常好的方案可以让大家非常好的进行合作,我觉得这个是我们做这个系统需要做的一个事情。我这里引一句老子的话,大家可以看一下。
埏埴以为器,当其无,有器之用。
凿户牖以为室,当其无,有室之用。
故有之以为利,无之以为用。
我在想,是什么因素决定了一个系统或者是一个软件,它是否可以长期生存下去呢?我觉得非常重要的一点,他要明确自己要做什么。其实就是前面讲的端水的端水,扫地的扫地,就是说你不但要明确自己这个软件要做什么,还得明确自己不要做什么。你什么东西是无以之为用,就是这个领域我是不进去的,我是不去做的。如果说你什么东西都做,最后就会比较弱,很容易就会颠覆,或者是被人取代。如果说你单单把一件事情做好,那你今后在这个领域,至少你是无可替代的,可以长期生存下去。我记得前一段时间有人问Linus,怎么看Docker容器。然后他说我才不关心这什么狗屁容器,我就关心我的内核,你不要来问我这个问题。我觉得他这个就是一个非常好的一个态度,他把他自己内核这一个模块做好,他把他系统这一块做好,那么对他而言,他这个工作就可以长期延续下去。
那么对于我们来说,比较详细一点,就是说在我们软件开发当中碰到的情况是这样的。从我们的软件设计到开发到测试、生产都经过非常多,非常反复的过程。同时在大部分的集群系统当中,我们也非常难以调度它。那么我觉得对于我们来说,就是后面要解决几个方面的问题。我觉得这是我们一个大的方向。
我们以后的产品是不是可以减少语言、程序、框架不同带来的复杂性,能不能把流程进行简化,把语言进行简化,把网络和服务依赖进行简化,这是我提的另一个问题。
免费提供最新Linux技术教程书籍,为开源技术爱好者努力做得更多更好:http://www.linuxprobe.com/
标签:
原文地址:http://www.cnblogs.com/linuxprobe/p/5658749.html