标签:style blog http 使用 io strong 数据 2014
之前做过摄像机标定的研究,不过现在忘了好多,昨天下午又捡起来,好好复习一下(主要是学习opencv一书内容)。
摄像机标定基本知识:
摄像机标定误差包括内参(4个)、畸变参数(径向和切向共5个)、外参(平移和旋转共6个)。
误差参数分析:摄像机模型采用针孔模型成像模型,由于中心轴安装问题,这就造成了精度误差,就是所谓的相机内参数误差,使用一个3X3的矩阵表示(A) [fx 0 cx; 0 fy cy; 0 0 1].,有四个未知参数;另由于针孔成像采光效率不高,使用了透镜,这就造成的畸变误差:
径向畸变:这是由于透镜先天条件原因(透镜形状),成像仪中心(光学中心)的畸变为0,随着向边缘移动,畸变越厉害。这里有3个参数,k1,k2,k3其中k3是可选参数。
切向畸变:这是摄像机安装过程造成的,如当透镜不完全平行于图像平面的时候产生的。
旋转和平移主要针对外参数,旋转3个角度和平移3个方向6个参数。
棋盘就不介绍了。主要是提取角点,便于后面计算,opencv函数都有函数。书上p423有原理介绍,感兴趣的朋友可以参考书上内容。
opencv实现过程及主要函数介绍:
1.首先获得数据源(视频或图像),我读取的一段自己录的视频;
2.初始化单帧棋盘数据,如6X4,并对棋盘操作提取角点;
用到的函数说明:
CVAPI(int) cvFindChessboardCorners( const void* image, CvSize pattern_size, CvPoint2D32f* corners, int* corner_count CV_DEFAULT(NULL), int flags CV_DEFAULT(CV_CALIB_CB_ADAPTIVE_THRESH+CV_CALIB_CB_NORMALIZE_IMAGE) );
这个函数式找到内角点位置:
image
输入的棋盘图,必须是8位的灰度或者彩色图像。
pattern_size
棋盘图中每行和每列角点的个数。
corners
检测到的角点
corner_count
输出,角点的个数。如果不是NULL,函数将检测到的角点的个数存储于此变量。
flags
各种操作标志,可以是0或者下面值的组合:
CV_CALIB_CB_ADAPTIVE_THRESH - 使用自适应阈值(通过平均图像亮度计算得到)将图像转换为黑白图,而不是一个固定的阈值。
CV_CALIB_CB_NORMALIZE_IMAGE - 在利用固定阈值或者自适应的阈值进行二值化之前,先使用cvNormalizeHist来均衡化图像亮度。
CV_CALIB_CB_FILTER_QUADS - 使用其他的准则(如轮廓面积,周长,方形形状)来去除在轮廓检测阶段检测到的错误方块。
void cvFindCornerSubPix(const CvArr* image,CvPoint2D32f* corners,int count,CvSize win,CvSize zero_zone,CvTermCriteria criteria)函数 cvFindCornerSubPix 通过迭代来发现具有子象素精度的角点位置:image
输入的图像,必须是8位的灰度或者彩色图像。
corners
输入角点的初始坐标,也存储精确的输出坐标。
count
角点数目
win
搜索窗口的一半尺寸。如果win=(5,5)那么使用(5*2+1)×(5*2+1)=11×11大小的搜索窗口
zero_zone
死区的一半尺寸,死区为不对搜索区的中央位置做求和运算的区域。它是用来避免自相关矩阵出现的某些可能的奇异性。当值为(-1,-1)表示没有死区。
criteria
求角点的迭代过程的终止条件。即角点位置的确定,要么迭代数大于某个设定值,或者是精确懂达到某个设定值。criteria可以是最大迭代数目,或者是设定的精确度,也可以是它们的组合。
3.摄像机标定求参数,我们目前求内参和畸变参数进行图像校正;
用到的函数说明:void cvCalibrateCamera2( const CvMat* object_points, const CvMat* image_points, const CvMat*point_counts, CvSize image_size, CvMat* intrinsic_matrix, CvMat* distortion_coeffs, CvMat* rotation_vectors=NULL, CvMat* translation_vectors=NULL, int flags=0 );
标定函数,求摄像机内参和外参数:
object_points
定标点的世界坐标,为3xN或者Nx3的矩阵,这里N是所有视图中点的总数。
image_points
定标点的图像坐标,为2xN或者Nx2的矩阵,这里N是所有视图中点的总数。
point_counts
向量,指定不同视图里点的数目,1xM或者Mx1向量,M是视图数目。
image_size
图像大小,只用在初始化内参数时。
intrinsic_matrix
输出内参矩阵(A),如果指定CV_CALIB_USE_INTRINSIC_GUESS和(或)CV_CALIB_FIX_ASPECT_RATION,fx、 fy、 cx和cy部分或者全部必须被初始化。
distortion_coeffs
输出大小为4x1或者1x4的向量,里面为形变参数[k1, k2, p1, p2]。
rotation_vectors
输出大小为3xM或者Mx3的矩阵,里面为旋转向量(旋转矩阵的紧凑表示方式,具体参考函数cvRodrigues2)
translation_vectors
输出大小为3xM或Mx3的矩阵,里面为平移向量。
flags
不同的标志,可以是0,或者下面值的组合:
CV_CALIB_USE_INTRINSIC_GUESS - 内参数矩阵包含fx,fy,cx和cy的初始值。否则,(cx, cy)被初始化到图像中心(这儿用到图像大小),焦距用最小平方差方式计算得到。注意,如果内部参数已知,没有必要使用这个函数,使用cvFindExtrinsicCameraParams2则可。
CV_CALIB_FIX_PRINCIPAL_POINT - 主点在全局优化过程中不变,一直在中心位置或者在其他指定的位置(当CV_CALIB_USE_INTRINSIC_GUESS设置的时候)。
CV_CALIB_FIX_ASPECT_RATIO - 优化过程中认为fx和fy中只有一个独立变量,保持比例fx/fy不变,fx/fy的值跟内参数矩阵初始化时的值一样。在这种情况下, (fx, fy)的实际初始值或者从输入内存矩阵中读取(当CV_CALIB_USE_INTRINSIC_GUESS被指定时),或者采用估计值(后者情况中fx和fy可能被设置为任意值,只有比值被使用)。
CV_CALIB_ZERO_TANGENT_DIST – 切向形变参数(p1, p2)被设置为0,其值在优化过程中保持为0。
4.矫正,利用上步求得的参数对图像进行矫正。
用到的函数说明,有两种方法进行矫正,下面都介绍一下:
a.使用cvInitUndistortMap()和cvRemap()来处理,前者用来计算畸变映射,后者把求得的映射应用到图像。
这个函数计算畸变映射,其中intrinsic_matrix摄像机内参数矩阵(A) [fx 0 cx; 0 fy cy; 0 0 1].distortion_coeffs形变系数向量[k1, k2, p1, p2,k3],大小为5x1或者1x5。mapx为x坐标的对应矩阵。mapy为y坐标的对应矩阵。void cvInitUndistortMap( const CvMat* intrinsic_matrix, const CvMat* distortion_coeffs, CvArr* mapx, CvArr* mapy );void cvRemap( const CvArr* src, CvArr* dst,const CvArr* mapx, const CvArr* mapy,int flags=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS,CvScalar fillval=cvScalarAll(0) );对图像进行普通几何变换,求得矫正图像:
src
输入图像.
dst
输出图像.
mapx
x坐标的映射 (32fC1 image).
mapy
y坐标的映射 (32fC1 image).
flags
插值方法和以下开关选项的组合:
CV_WARP_FILL_OUTLIERS - 填充边界外的像素. 如果输出图像的部分象素落在变换后的边界外,那么它们的值设定为 fillval。函数cvInitUndistortMap预先计算非形变对应-正确图像的每个像素在形变图像里的坐标。这个对应可以传递给cvRemap函数(跟输入和输出图像一起)。
b.使用cvUndistort2()这个函数一次完成所有事项,不推荐。
CVAPI(void) cvUndistort2( const CvArr* src, CvArr* dst, const CvMat* camera_matrix, const CvMat* distortion_coeffs, const CvMat* new_camera_matrix CV_DEFAULT(0) );
函数说明:
其中,src为输入图像,dst为输出图像.,camera_matrix摄像机内参数矩阵(A) [fx 0 cx; 0 fy cy; 0 0 1],distortion_coeffs形变系数向量[k1, k2, p1, p2,k3],大小为5x1或者1x5。
建议还是使用第一种算法,因为计算畸变映射是一个耗时的操作,当畸变映射不变的时候,使用第一种效率更高。
本人实验效果如下:
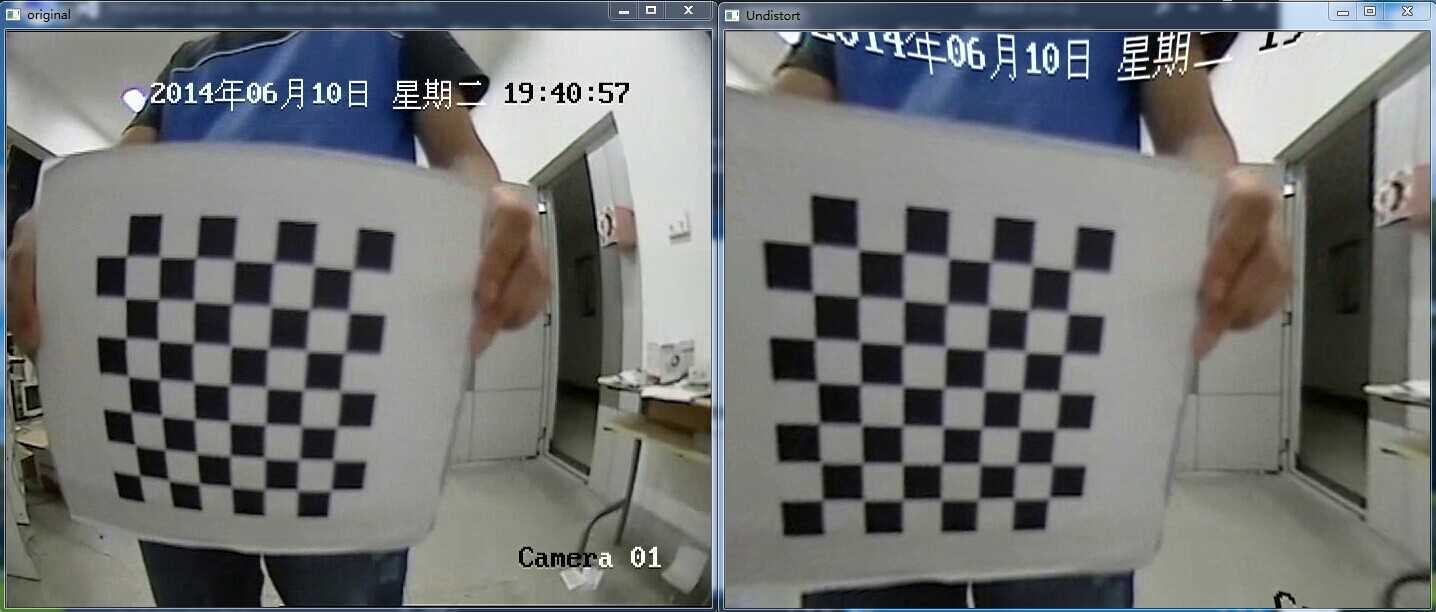
代码这里就不留了,opencv也有类似的源码,有需要的朋友留下联系方式可以发给你们,共勉!
标签:style blog http 使用 io strong 数据 2014
原文地址:http://www.cnblogs.com/tianya2543/p/3894644.html