标签:
前几天看到一个有意思的分享,大意是讲如何用Tensorflow教神经网络自动创造音乐。听起来好好玩有木有!作为一个Coldplay死忠粉,第一想法就是自动生成一个类似Coldplay曲风的音乐,于是,开始跟着Github上的教程(项目的名称:Project Magenta)一步一步做,弄了三天,最后的生成的音乐在这里(如果有人能告诉我怎么在博客里插入音乐请赶快联系我!谢谢!)
http://yun.baidu.com/share/link?shareid=1799925478&uk=840708891
http://yun.baidu.com/share/link?shareid=3718079494&uk=840708891
这两段音乐是我生成的十几个音乐中听起来还不错的,虽然还是有点怪,但是至少有节奏,嘿嘿。下面来说一下是怎么做的:
1.首先下载Project Magenta
1 git clone https://github.com/tensorflow/magenta.git
2.安装需要的工具:
在这里(https://www.tensorflow.org/versions/r0.9/get_started/os_setup.html)安装python、bazel和Tensorflow
注:我在安装bazel的时候一直出现“Segmentation fault:11”的错误,google了很多解决方法后发现是gcc的安装版本问题,如果你是mac用户,下载了xcode,并不代表你安装了gcc,还必须安装command line tools,如果安装成功,在linux里输入“gcc --version”会出现相应的版本信息,如果没有,就说明安装失败。如果安装失败了,用下载好的bazel再输入“bazel install gcc”,下载完检测一下gcc -v,如果依然是"Segmentation fault:11"错误,恭喜你,遇到和我一样的错误了,google了半天后发现发现了这个:
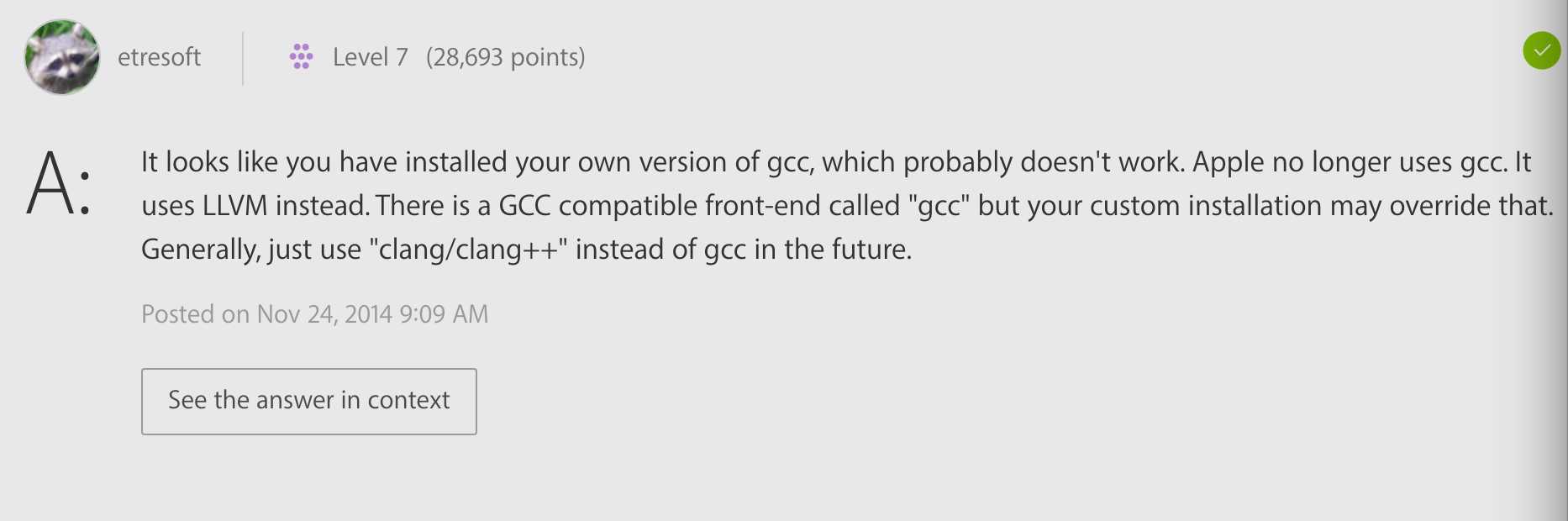
so,Apple现在已经不用gcc了,改为LLVM。以后要用"clang、clang++"来代替gcc。如果你输入gcc -v,显示"Segmentation fault:11",不妨输入一下"clang -v",看一下有没有对应的版本信息。如果有就代表你下载成功了。但是没有完,还有最后一步,把指向gcc的链接改到clang。输入"which gcc"和"which clang",可以看到你的gcc和clang的位置,然后改一下软链接:

1 cd /usr/local/bin 2 sudo mv gcc gcc_OLD 3 sudo ln -s /usr/bin/clang /usr/local/bin/gcc 4 gcc -v 5 Apple LLVM version 6.1.0 (clang-602.0.53) (based on LLVM 3.6.0svn) 6 Target: x86_64-apple-darwin14.5.0 7 Thread model: posix
这样就大功告成了!哈哈!不要问我为什么花这么大篇幅写这个看似无关紧要的东西,因为我被这玩意儿折磨了两天!!弄完这个才花了三天结果搞个这个居然就花了两天!!哦,对了,如果你看到这儿不知道bazel是干啥的,简单的说就是一个编译工具,相当于pip的intsall。
现在用bazel来测试一下能不能顺利运行:
1 bazel test //magenta:all
注:如果全部测试成功,很好。如果出现这个错误:
1 INFO: Found 5 targets and 6 test targets... 2 INFO: Elapsed time: 0.427s, Critical Path: 0.00s 3 //magenta:basic_one_hot_encoder_test (cached) PASSED in 3.7s 4 //magenta:convert_midi_dir_to_note_sequences_test (cached) PASSED in 2.3s 5 //magenta:melodies_lib_test (cached) PASSED in 3.5s 6 //magenta:midi_io_test (cached) PASSED in 5.5s 7 //magenta:note_sequence_io_test (cached) PASSED in 3.5s 8 //magenta:sequence_to_melodies_test (cached) PASSED in 40.2s 9 10 Executed 0 out of 6 tests: 6 tests pass.
11 There were tests whose specified size is too big. Use the --test_verbose_timeout_warnings command line option to see which ones these are.
恭喜你,又犯了和我同样的错误:)这个错误是说测试文件太大了,不能一下子全部测试(我16g的内存还不够吗 = =),所以你可以跟我一样手动测试,以其中一个举例:
1 >>>bazel-bin/magenta/basic_one_hot_encoder_test 2 >>>---------------------------------------------------------------------- 3 Ran 5 tests in 0.074s 4 5 OK
把上述六个文件依次测试一下,成功请看下一步。
3.创建你的旋律数据集
和机器学习一样,我们得先输入一定的数据让它去训练,这里的训练数据可以自己下载喜欢的音乐,不过Magenta不能直接读取mp3文件,只能读取MIDI文件(mp3太大了,一个10M左右的mp3格式音乐可以转换成100k左右的midi文件)。当然,转换成midi格式的方法很多,我搜集了一个超好用的网址可以在线转:Convert Tool
读取MIDI文件后,Magenta要把MIDI文件转化成Sequence文件才能进行训练
##创建旋律数据库 MIDI_DIRECTORY=/Users/shelter/magenta/magenta/music/train #这里换成你的文件路径就行了 SEQUENCES_TFRECORD=/tmp/notesequences.tfrecord bazel run //magenta:convert_midi_dir_to_note_sequences -- --midi_dir=$MIDI_DIRECTORY --output_file=$SEQUENCES_TFRECORD --recursive
然后再从这些Sequence序列里提取出旋律:
1 ##从Sequences中提取旋律 2 SEQUENCES_TFRECORD=/tmp/notesequences.tfrecord 3 TRAIN_DATA=/tmp/training_melodies.tfrecord #生成的训练文件地址 4 EVAL_DATA=/tmp/evaluation_melodies.tfrecord 5 EVAL_RATIO=0.10 ENCODER=basic_one_hot_encoder 6 bazel run //magenta/models:basic_rnn_create_dataset -- 7 --input=$SEQUENCES_TFRECORD 8 --train_output=$TRAIN_DATA 9 --eval_output=$EVAL_DATA 10 --eval_ratio=$EVAL_RATIO 11 --encoder=$ENCODER
ok,这里我们的数据处理就完成了,生成的训练文件在"/tmp/training_melodies.tfrecord"里
4.训练神经网络模型
训练数据生成后就可以训练模型了,这里使用的是RNN模型:
1 ##训练神经网络模型
2 #首先compile basic_rnn工具
3 bazel build //magenta/models:basic_rnn_train
4
5 #训练模型,其中“rnn_layer_size”是神经网络的层数,可以自定义
6 ./bazel-bin/magenta/models/basic_rnn_train --experiment_run_dir=/tmp/basic_rnn/run1 --sequence_example_file=$TRAIN_DATA --eval=false --hparams=‘{"rnn_layer_sizes":[50]}‘ --num_training_steps=1000
5.生成测试的旋律
模型那一步非常非常耗时间,Github里设置的是20000次迭代,差点把我的电脑跑烧起来 = =,你可以根据实际硬件情况设置迭代次数。测试旋律和训练的旋律一样,都是midi文件,我这里选取的是Katy Perry的Peacock(小黄歌 = =,想看一下用Coldplay的训练数据在katy Perry上测试的结果是啥)
1 ##生成旋律
2 #指定测试旋律的文件地址
3 PRIMER_PATH=/Users/shelter/magenta/magenta/music/coldplay/KatyPerryPeacock.mid #注意这里是绝对地址,只能指定一首歌
4 bazel run //magenta/models:basic_rnn_generate -- 5 --experiment_run_dir=/tmp/basic_rnn/run1 6 --hparams=‘{"rnn_layer_sizes":[50]}‘ 7 --primer_midi=$PRIMER_PATH 8 --output_dir=/tmp/basic_rnn_3 9 --num_steps=64 10 --num_outputs=16
你可以用 "bazel test //magenta:all"查看结果,在 http://localhost:6006 里查看可视化结果,包含收敛过程,accuracy等。
最后生成的旋律就是开头百度云里的文件了。还有另外一个是用轻音乐测试的,效果也不错。
总结:
1.一开始我的训练次数是20000次,到1000次的时候算法发散了,loss值由本来从20几万下降到2000多左右然后突然上升到16000左右,accuracy也下降了,所以就退出了,把迭代次数换成1000次训练。训练结束的时候算法还没有收敛,但是我想快点看到结果,而且电脑跑的太慢了,就直接拿来用了。如果你有GPU或者愿意等个几天跑程序,可以把迭代次数设置的大一点,等算法收敛后再进行测试。模型训练的好坏直接决定最后得到的音乐的好听程度,所以最好等算法收敛后在进行测试。我测试的世界各文件中很多都像乱弹的。
2.这个项目刚开始不久,有一个论坛专门给大家交流学习的心得以及提问题,点这里。上面的注释是我遇到的问题,如果遇到了新的问题,可以在论坛上发帖求助。我看到有的人生成的音乐很有那种诡异的哥特风哈哈。
3.这个项目背后的具体原理我没有写,Github上写的很清楚,可以参考这里
4.生成后的音乐可以根据自己的需要加上节拍,应该会好听一点~
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5666413.html