标签:
当你利用 Hadoop 进行大数据分析和处理时,首先你需要确保配置、部署和管理集群。这个即不容易也没有什么乐趣,但却受到了开发者们的钟爱。本文提供了5款工具帮助你实现。
Apache Ambari
Apache Ambari是对Hadoop进行监控、管理和生命周期管理的开源项目。它也是一个为Hortonworks数据平台选择管理组建的项目。Ambari向Hadoop MapReduce、HDFS、 HBase、Pig, Hive、HCatalog以及Zookeeper提供服务。
Apache Mesos

Apache Mesos是集群管理器,可以让用户在同一时间同意集群上运行多个Hadoop任务或其他高性能应用。Twitter的开放源代码经理Chris Aniszczyk表示,Mesos可以在数以百计的设备上运行,并使其更容易执行工作。
Platform MapReduce
Platform MapReduce提供了企业级可管理性和可伸缩性、高资源利用率和可用性、操作便利性、多应用支持以及一个开放分布式系统架构,其中包括对于Hadoop分布式文件系统(HDFS)和Appistry Cloud IQ的即时支持,稍后还将支持更多的文件系统和平台,这将确保企业更加关注将MapReduce应用程序转移至生产环境中。
StackIQ Rocks+ Big Data

StackIQ Rock+ Big Data是一款Rocks的商业流通集群管理软件,该公司已加强支持Apache Hadoop。Rock+支持Apache、Cloudera、Hortonworks和MapR的分布,并且处理从裸机服务器来管理Hadoop集群配置的整个过程。
Zettaset Orchestrator
Zettaset Orchestrator是端到端的Hadoop管理产品,支持多个Hadoop的分布。Zettaset吹捧Orchestrator的基于UI的经验和MAAPS(管理、可用性、自动化、配置和安全)的处理能力。
------------------------------------------------------------------------------------------------------------------------------------------------------
Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
先决条件
1) 确保在你集群中的每个节点上都安装了所有必需软件:sun-JDK ssh Hadoop。
2) JavaTM1.5.x,必须安装,建议选择Sun公司发行的Java版本。
3) ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程。
实验环境
操作平台:vmware
操作系统:CentOS 5.9
软件版本:hadoop-1.2.1,jdk-6u45
集群架构:包括4个节点:1个Master,3个Salve,节点之间局域网连接,可以相互ping通。节点IP地址分布如下:
| 主机名 | IP | 系统版本 | Hadoop node | hadoop进程名 |
| Master | 192.168.137.100 | CetOS 5.9 | master | namenode,jobtracker |
| Slave1 | 192.168.137.101 | CetOS 5.9 | slave | datanode,tasktracker |
| Slave2 | 192.168.137.102 | CetOS 5.9 | slave | datanode,tasktracker |
| Slave3 | 192.168.137.103 | CetOS 5.9 | slave | datanode,tasktracker |
四个节点上均是CentOS5.9系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
安装步骤
下载:jdk-6u45-linux-x64.bin , hadoop-1.2.1.tar.gz (主机名和网络配置略)
说明:在生产的hadoop集群环境中,由于服务器可能会有许多台,通过配置DNS映射机器名,相比配置/etc/host方法,可以避免在每个节点都配置各自的host文件,而且在新增节点时也不需要修改每个节点的/etc/host的主机名-IP映射文件。减少了配置步骤和时间,便于管理。
1、JDK安装
添加java环境变量:
生效java变量:
在所有的机器上都建立相同的目录,也可以就建立相同的用户,最好是以该用户的home路径来做hadoop的安装路径。安装路径都是:/home/hadoop/hadoop-1.2.1
2、SSH配置
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。以本文中的四台机器为例,现在Master是主节点,他须要连接Slave1、Slave2和Slave3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。
切换到hadoop用户( 保证用户hadoop可以无需密码登录,因为我们后面安装的hadoop属主是hadoop用户。)
1) 在每台主机生成密钥对
这个命令生成一个密钥对:id_rsa(私钥文件)和id_rsa.pub(公钥文件)。默认被保存在~/.ssh/目录下。
2) 将Master公钥添加到远程主机Slave1的 authorized_keys 文件中
在/home/hadoop/.ssh/下创建authorized_keys
将刚才复制的公钥复制进去
权限设置为600.(这点很重要,网没有设置600权限会导致登陆失败)
测试登陆:
同样的方法,将Master 的公钥复制到其他节点。
3、安装Hadoop
1) 切换为hadoop用户,下载安装包后,直接解压安装即可:
我的安装目录为:
/home/hadoop/hadoop-1.2.1
为了方便,使用hadoop命令或者start-all.sh等命令,修改Master上/etc/profile 新增以下内容:
修改完毕后,执行source /etc/profile 来使其生效。
2) 配置conf/hadoop-env.sh文件
配置conf/hadoop-env.sh文件,添加:
这里修改为你的jdk的安装位置。
测试hadoop安装:
4、集群配置(所有节点相同)
1) 配置文件:conf/core-site.xml
fs.default.name是NameNode的URI。hdfs://主机名:端口/hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
2) 配置文件:conf/mapred-site.xml
mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。
3) 配置文件:conf/hdfs-site.xml
dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
4) 配置masters和slaves主从结点
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
5、hadoop启动
1) 格式化一个新的分布式文件系统
查看输出保证分布式文件系统格式化成功执行完后可以到master机器上看到/home/hadoop//name1和/home/hadoop/name2两个目录。在主节点master上面启动hadoop,主节点会启动所有从节点的hadoop。
2) 启动所有节点
启动方式1:
执行完后可以到master(Master)和slave(Slave1,Slave2,Slave3)机器上看到/home/hadoop/hadoopfs/data1和/home/hadoop/data2两个目录。
启动方式2:
启动Hadoop集群需要启动HDFS集群和Map/Reduce集群。
在分配的NameNode上,运行下面的命令启动HDFS:
$ bin/start-dfs.sh
(单独启动HDFS集群)
bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。
在分配的JobTracker上,运行下面的命令启动Map/Reduce:$bin/start-mapred.sh
(单独启动Map/Reduce)
bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。
3) 关闭所有节点
从主节点master关闭hadoop,主节点会关闭所有从节点的hadoop。
Hadoop守护进程的日志写入到 ${HADOOP_LOG_DIR} 目录 (默认是 ${HADOOP_HOME}/logs).
${HADOOP_HOME}就是安装路径.
6、测试
1) 用jps检验各后台进程是否成功启动
2) 通过用浏览器和http访问NameNode和JobTracker的网络接口:
NameNode – http://192.168.137.100:50070/dfshealth.jsp

Jobtracker – http://192.168.137.101:50060/tasktracker.jsp

3) 使用netstat –nat查看端口9000和9001是否正在使用。
HDFS操作
运行bin/目录的hadoop命令,可以查看Haoop所有支持的操作及其用法,这里以几个简单的操作为例。
建立目录
在HDFS中建立一个名为testdir的目录
复制文件
把本地文件/home/hadoop/hadoop-1.2.1.tar.gz拷贝到HDFS的根目录/user/hadoop/下,文件名为testfile.zip
查看现有文件
Apache Ambari是对Hadoop进行监控、管理和生命周期管理的开源项目。它也是一个为Hortonworks数据平台选择管理组建的项目。Ambari向Hadoop MapReduce、HDFS、 HBase、Pig, Hive、HCatalog以及Zookeeper提供服务。最近准备装ambari,在网上找了许久,没找到比较系统的ambari安装过程,于是,就根据官网进行了安装,下面是我推荐的正确的较完善的安装方式,希望对大家有所帮助。
一、准备工作
1、系统:我的系统是CentOS6.2,x86_64,本次集群采用两个节点。管理节点:192.168.10.121;客户端节点:192.168.10.122
2、系统最好配置能上网,这样方便后面的操作,否则需要配置yum仓库,比较麻烦。
3、集群中ambari-serveer(管理节点)到客户端配置无密码登录。
4、集群同步时间
5、SELinux,iptables都处于关闭状态。
6、ambari版本:1.2.0
二、安装步骤
A、配置好集群环境
############ 配置无密码登录 ################# [root@ccloud121 ~]# ssh-keygen -t dsa [root@ccloud121 ~]# cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys [root@ccloud121 ~]# scp /root/.ssh/id_dsa.pub 192.168.10.122:/root/ [root@ccloud121 ~]# ssh 192.168.10.122 [root@ccloud122 ~]# cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys ############# NTP 时间同步 ################# [root@ccloud121 ~]# ntpdate time.windows.com [root@ccloud121 ~]# ssh ccloud122 ntpdate time.windows.com ########### SELinux & iptables 关闭 ########### [root@ccloud121 ~]# setenforce 0 [root@ccloud121 ~]# ssh ccloud122 setenforce 0 [root@ccloud121 ~]# chkconfig iptables off [root@ccloud121 ~]# service iptables stop [root@ccloud121 ~]# ssh ccloud122 chkconfig iptables off [root@ccloud121 ~]# ssh ccloud122 service iptables stop
B、管理节点上安装ambari-server
1、下载repo文件
[root@ccloud121 ~]# wget http://public-repo-1.hortonworks.com/AMBARI-1.x/repos/centos6/ambari.repo [root@ccloud121 ~]# cp ambari.repo /etc/yum.repos.d
这样,ambari-server的yum仓库就做好了。
2、安装epel仓库
[root@ccloud121 ~]# yum install epel-release
# 查看仓库列表,应该有HDP,EPEL
[root@ccloud121 ~]# yum repolist
3、通过yum安装amabari bits,这同时也会安装PostgreSQL
[root@ccloud121 ~]# yum install ambari-server
这个步骤要等一会,它需要上网下载,大概39M左右。
4、运行ambari-server setup,安装ambari-server,它会自动安装配置PostgreSQL,同时要求输入用户名和密码,如果按n,它用默认的用户名/密码值:ambari-server/bigdata。接着就开始下载安装JDK。安装完成后,ambari-server就可以启动了。
三、集群启动
1、直接接通过ambari-server start和amabari-server stop即可启动和关闭ambari-serveer。
2、启动成功后,在浏览器输入http://192.168.10.121:8080
界面如下图所示:
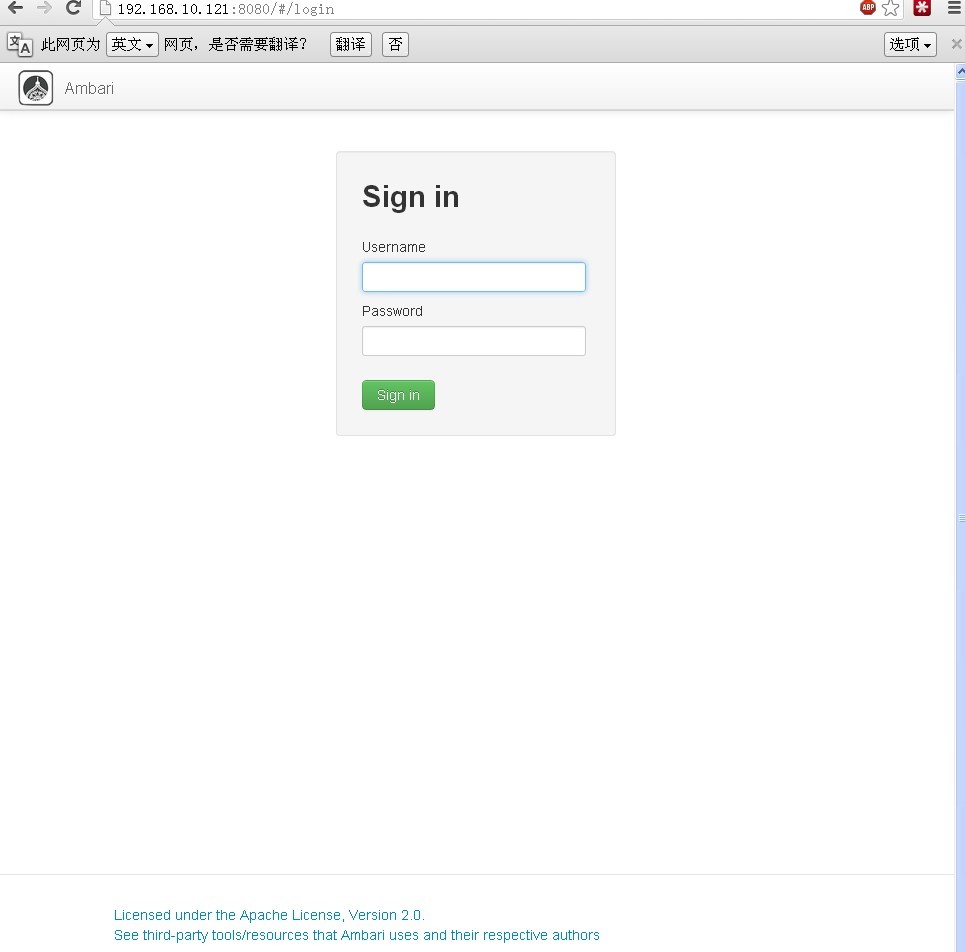
登录名和密码都是admin。
这样就可以登录到管理控制台。
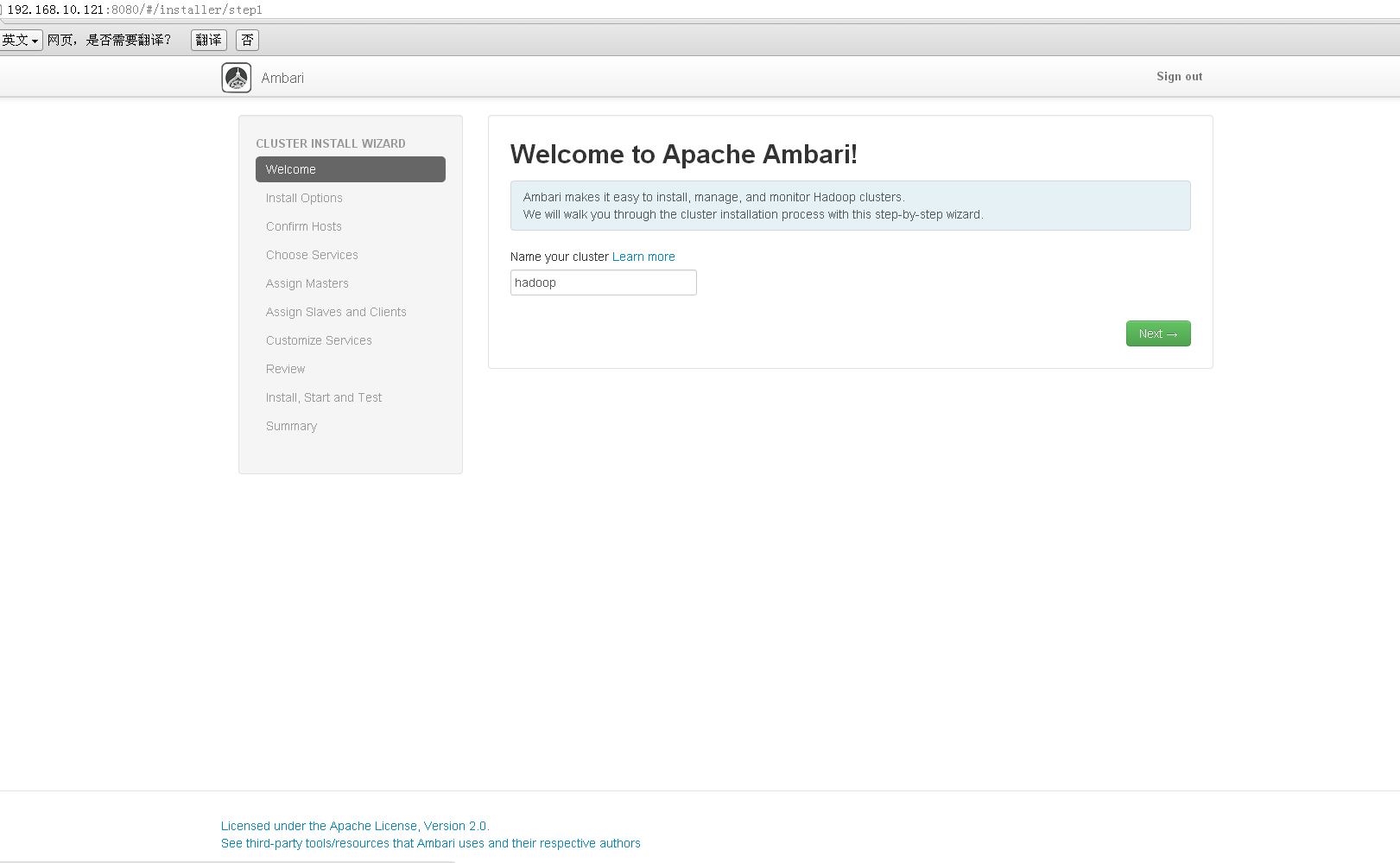
3、集群的安装配置按照步骤一步步做,在ssh private key里选择/etc/.ssh/id_rsa这个文件,但是我在注册节点时出现了个问题:
(‘INFO 2013-03-06 10:37:42,580 NetUtil.py:58 - Failed to connect to httPS://180.168.41.175:8440/cert/ca due to [Errno 111] Connection refused
INFO 2013-03-06 10:37:42,580 NetUtil.py:77 - Server at https://180.168.41.175:8440 is not reachable,
这个问题始终得不到解决,安装无法继续下去,网上也找不到解决方案,希望看到这篇博文的高手朋友们,能提供些解决方案,在此先谢谢了。
四、备注
ambari源码:http://svn.apache.org/repos/asf/incubator/ambari/tags/
【参考文献】1.HTools:开源免费的Hadoop集群监控工具
http://www.thinksaas.cn/topics/0/233/233669.html
2.Netflix开源Hadoop集群调度工具:日处理近万作业、上千TB数据
http://www.csdn.net/article/2013-06-27/2816022-genie-is-out-of-bottle
3.从主机名谈真实Hadoop集群与虚拟机集群管理http://blog.csdn.net/chaijunkun/article/details/23283431
4.阿里大规模Hadoop集群运维经验谈_图文http://wenku.baidu.com/view/e064d15c561252d380eb6ec6.html?from=search
5.Hadoop集群管理和运维http://wenku.baidu.com/view/692e02b91711cc7931b716fd.html
6.红象云腾 http://www.redhadoop.com/ SequoiaDB http://www.sequoiadb.com/cn/
标签:
原文地址:http://blog.csdn.net/enweitech/article/details/51917249