向量空间模型 (或者 词组向量模型) 作为向量的标识符(比如索引),是一个用来表示文本文件的代数模型。它应用于信息过滤、信息检索、索引以及关联规则。SMART是第一个使用这个模型的信息检索系统。
文档和查询都用向量来表示。

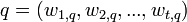
每一维都相当于是一个独立的词组。如果这个术语出现在了文档中,那它在向量中的值就非零。已经有很多不同的方法来计算这些值,这些值叫做(词组)权重。其中一种广为人知的算法就是tf_idf权重(见下面的例子)。 我们是根据应用来定义词组的。典型的词组就是一个单一的词、关键词、或者较长的短语。如果字被选为词组,那么向量的维数就是出现在词汇表中不同字的个数。 向量运算能通过查询来比较各文档。

通过文档相似度理论的假设,比较每个文档向量和原始查询向量(两个向量的类型是相同的)之间的角度偏差,使得在文档中搜索关键词的关联规则是能够计算的。 实际上,计算向量之间夹角的余弦比直接计算夹角本身要简单。

其中 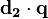 是文档向量(即右图中的d2)和查询向量(图中的q)的点乘。
是文档向量(即右图中的d2)和查询向量(图中的q)的点乘。  是向量d2 的模,
而
是向量d2 的模,
而 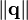 是向量q的模. 向量的模通过下面的公式来计算:
是向量q的模. 向量的模通过下面的公式来计算:
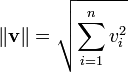
由于这个模型所考虑的所有向量都是严格非负的,如果其余弦值为零,则表示查询向量和文档向量是正交的,即不符合(换句话说,就是该检索词在文档中没有找到)。如果要了解详细的信息可以查看余弦相似性。
Salton, Wong 和 Yang 提出的传统向量空间模型,一个词组在文件向量中权重就是局部参数和全局参数的乘积,这就是著名的tf-idf模型(词频_逆向文件频率)。文档的权重向量d就是  ,其中
,其中
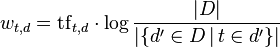
 是词组t在文档d中出现的频率(一个局部参数)
是词组t在文档d中出现的频率(一个局部参数) 是逆向文件频率(一个全局参数)。
是逆向文件频率(一个全局参数)。 是文件集中的文件总数;
是文件集中的文件总数; 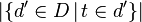 是含有词组t的文件数。
是含有词组t的文件数。文件dj 和查询q之间的余弦相似度通过一下公式来计算:

在简单的词组计算模型中,词组的权重不包含全局参数,而是单纯的计算词组出现的次数: 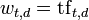 。
。
相对于标准的布尔数学模型,向量空间模型具有如下优点:
向量空间模型有如下局限:
然而,这些局限中的多数能够通过多种多样的方法集成来解决,包括数学上的技术,比如奇异值分解和词汇数据库(比如wordnet)
基于模型的和基于扩展的向量空间模型包括:
原文地址:http://blog.csdn.net/wbj01100/article/details/38401535