标签:
环境:ubuntu 16.04 LTS (X86-64),pycharm
python版本 :3.5.1+
#生成的文件默认会保存到代码所在根目录
1 import urllib.request,urllib.error,re
2
3 class Tool:
4 removeImg=re.compile(‘<img.*?| {7}|‘)
5 removeAddr=re.compile(‘<a.*?|</a>‘)
6 replaceLine=re.compile(‘<tr>|<div>|</div>|</p>‘)
7 replaceTD=re.compile(‘<td>‘)
8 replaceBR=re.compile(‘<br></br>|br‘)
9 replaceExtra=re.compile(‘<.*?>‘)
10 def replace(self,x):
11 x=re.sub(self.removeImg,"",x)
12 x=re.sub(self.removeAddr,"",x)
13 x=re.sub(self.replaceLine,"\n",x)
14 x=re.sub(self.replaceTD,"\t",x)
15 x=re.sub(self.replaceBR,"\n",x)
16 x=re.sub(self.replaceExtra,"",x)
17 return x.strip()
18
20 class BDTB:
21 def __init__(self,baseUrl,see_lz):
22 self.tool=Tool()
23 self.baseurl=baseUrl+‘?see_lz=‘+str(see_lz)+‘&pn=‘
24 self.defaultTitle=u‘百度贴吧‘
25
26 def getPage(self,pagenum):
27 try:
28 url=self.baseurl+str(pagenum)
29 request=urllib.request.Request(url)
30 response=urllib.request.urlopen(request)
31 content = response.read().decode(‘utf-8‘)
32 return content
33 except urllib.error.URLError as e:
34 if hasattr(e,"reason"):
35 print(u‘connect error reason:‘+e.reason)
36 if hasattr(e,‘code‘):
37 print(u‘connect error,reason:‘+e.code)
38
39 def getPns(self,content):
40 pattern = re.compile(‘<li class="l_reply_num".*?<span class="red">(.*?)</span>‘, re.S)
41 pns = int((re.findall(pattern, content))[0])
42 return pns
43
44 def getTitle(self,content):
45 pattern=re.compile(‘<h3 class="core_title_txt pull-left text-overflow ".*?>(.*?)</h3>‘,re.S)
46 return str((re.findall(pattern,content))[0])
47
48 def getContent(self,content):
49 pattern=re.compile(‘<ul class="p_author".*?<li class="d_name".*?target="_blank">(.*?)</a>.*?<div id="post_content_.*?>(.*?)</div>‘,re.S)
50 items=re.findall(pattern,content)
51 contents=[]
52 for item in items:
53 content=‘Username: ‘+item[0]+‘ content: ‘+self.tool.replace(item[1])+‘\n‘
54 contents.append(content)
55 return contents
56
57 def setFileTitle(self,Title):
58 if Title is not None:
59 self.file=open(Title+‘.txt‘,‘w+‘)
60 else:
61 self.file=open(self.defaultTitle+‘.txt‘,‘w+‘)
62
63 def WriteData(self,contents):
64 for content in contents:
65 self.file.write(content)
66
67 def start(self):
68 Pns=self.getPns(self.getPage(1))
69 self.setFileTitle(self.getTitle(self.getPage(1)))
70 for i in range(Pns):
71 print(‘Page Sum:‘+str(Pns)+‘\n‘)
72 print(‘Now is Write page:‘+str(i)+‘\n‘)
73 self.WriteData(self.getContent(self.getPage(i)))
74 self.file.close()
75
76 print(‘please enter discussion num:‘)
77 url=‘http://tieba.baidu.com/p/‘+str(input())
78 see_lz=input(‘Whether just see lz(enter 0 or 1)‘)
79 bdtb=BDTB(url,see_lz)
80 bdtb.start()
运行结果: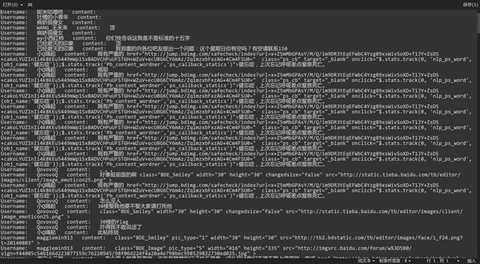
标签:
原文地址:http://www.cnblogs.com/INnoVationv2/p/5679849.html