标签:
MapReduce 单词统计案例编程
一、在Linux环境安装Eclipse软件
1、 解压tar包
下载安装包eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz到/opt/software目录下。
解压到/opt/tools目录下:
[hadoop@bigdata-senior01 tools]$ tar -zxf /opt/sofeware/eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz -C /opt/tools/
2、 创建存放源代码的目录
[hadoop@bigdata-senior01 eclipse]$ sudo mkdir -p /opt/mysource/workspace
修改mysource的所有者为hadoop用户
[hadoop@bigdata-senior01 opt]$ sudo chown -R hadoop:hadoop /opt/mysource/
3、 启动Eclipse
在XWindow环境中,进入/opt/tools/eclipse目录,执行eclipse打开eclipse界面。
[hadoop@bigdata-senior01 eclipse]$ /opt/tools/eclipse/eclipse
设置Workspace目录为:/opt/mysource/workspace。
二、Hadoop Maven配置
1、 安装Apache Maven
(1) 解压Maven
[hadoop@bigdata-senior01 sofeware]$ tar -zxf apache-maven-3.0.5-bin.tar.gz -C /opt/modules/
(2) 配置/etc/profile文件
export MAVEN_HOME="/opt/modules/apache-maven-3.0.5"
export PATH=$MAVEN_HOME/bin:$PATH
(3) 生效配置文件
[root@bigdata-senior01 sofeware]# source /etc/profile
(4) 确认Maven配置成功
[root@bigdata-senior01 sofeware]# mvn -version
Apache Maven 3.0.5 (r01de14724cdef164cd33c7c8c2fe155faf9602da; 2013-02-19 21:51:28+0800)
Maven home: /opt/modules/apache-maven-3.0.5
Java version: 1.7.0_67, vendor: Oracle Corporation
Java home: /opt/modules/jdk1.7.0_67/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "2.6.32-504.el6.x86_64", arch: "amd64", family: "unix"
2、 设置Eclipse中设置Maven路径
(1) Preferences对话框左侧选择Maven下的Installations,右侧点击Add,添加一个Maven位置。
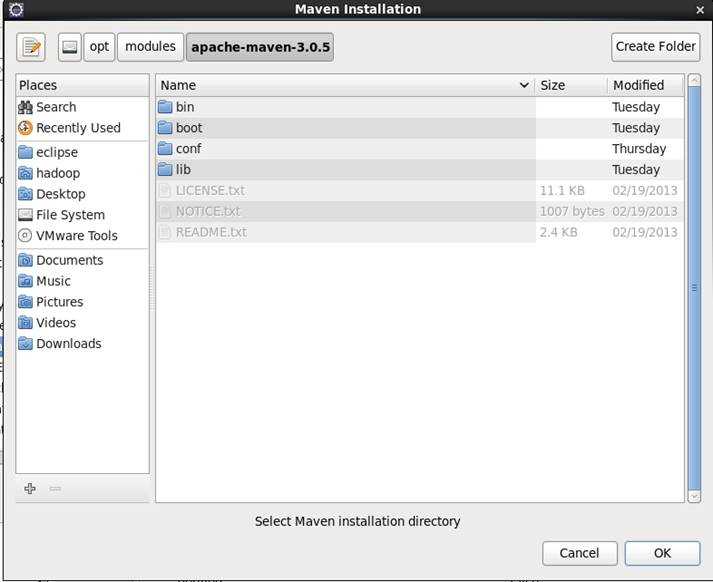
(2) 选择自己的maven目录:/opt/modules/apache-maven-3.0.5
3、 查看home目录下是否有.m2目录
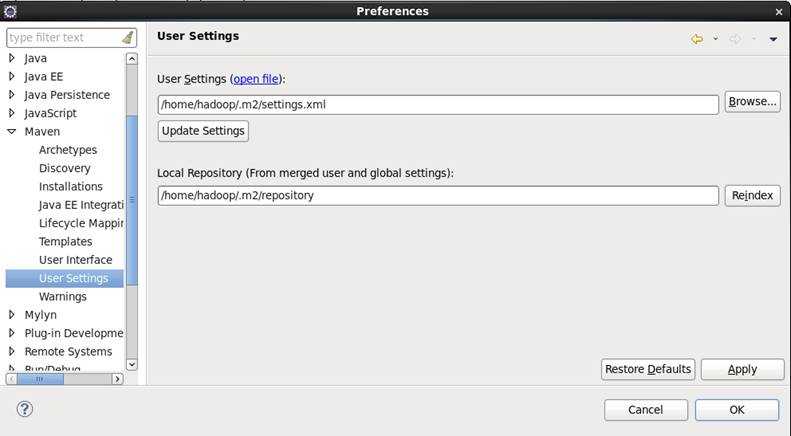
在Preferences左侧的Maven下的User Setting中,查看右侧是否提示.m2目录不存在,如果不存在,要手动创建。
4、 拷贝maven的settings.xml
[hadoop@bigdata-senior01 ~]$ cp /opt/modules/apache-maven-3.0.5/conf/settings.xml ~/.m2/
三、创建WordCount程序项目
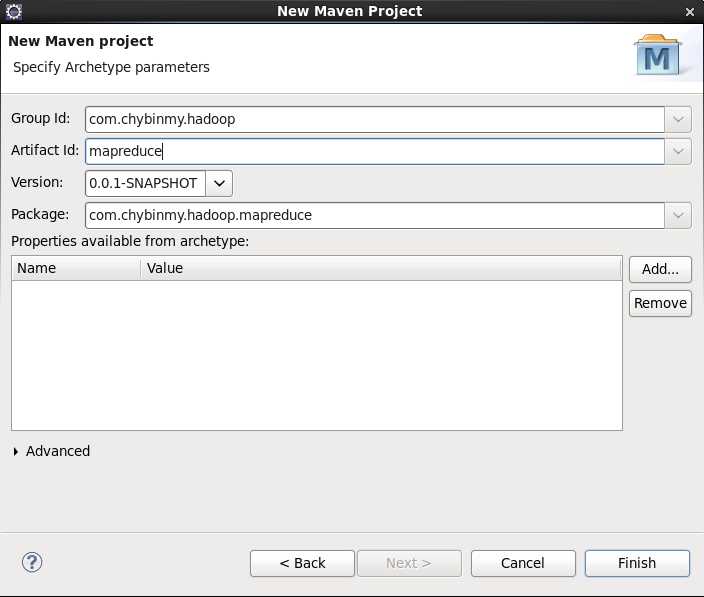
1、 创建一个Maven项目
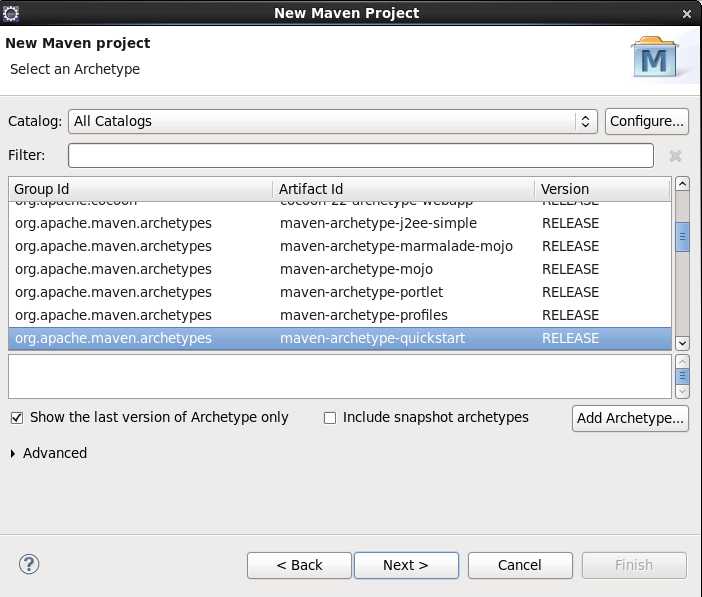
(1) File菜单中,新建Maven Project。
2、 添加Source Folder用来存放配置文件
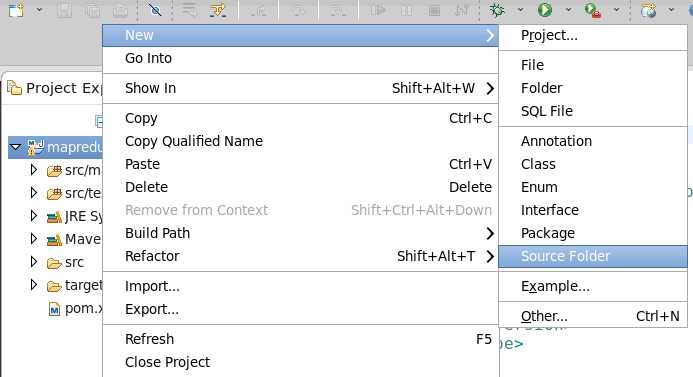
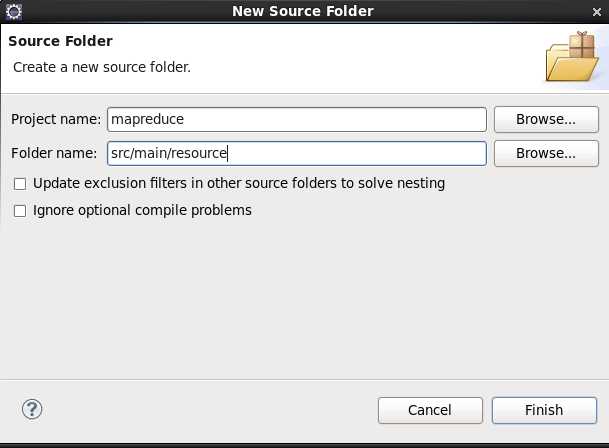
将来core-site.xml、hdfs-site.xml、yarn-site.xml等配置文件存放在这个目录下。
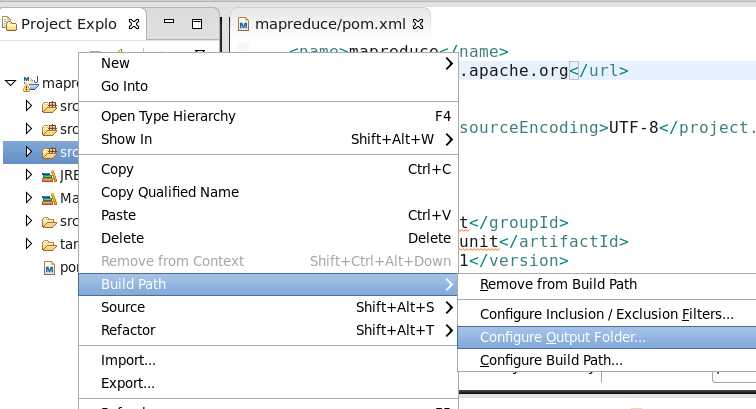
3、 为src/main/resource指定输出路径
4、 编辑pom.xml文件
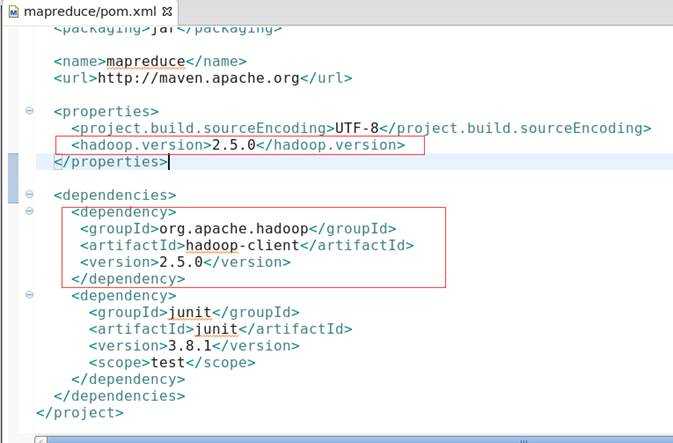
修改pom.xml后保存后,maven会自动去下载依赖包
四、编写MapReduce方法
1、 添加一个类WordCountMapReduce
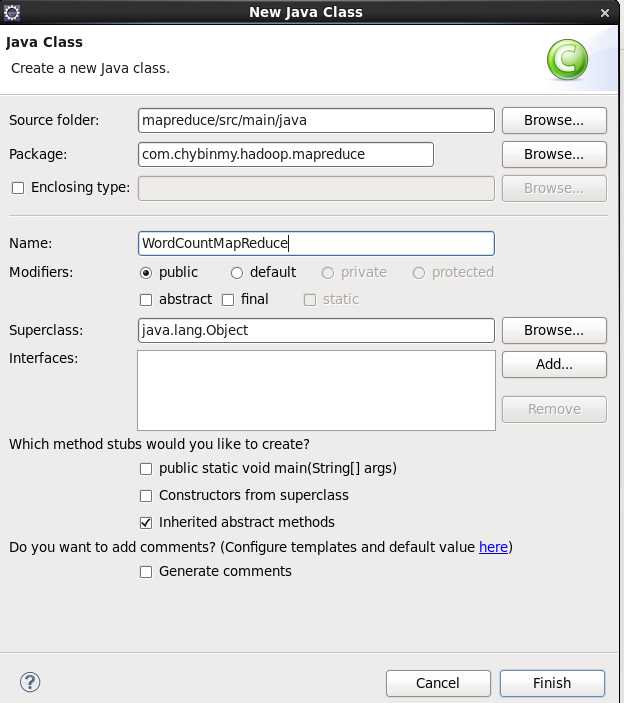
WordCountMapReduce类继承org.apache.hadoop.con类并实现org.apache.hadoop.util接口。
|
package com.chybinmy.hadoop.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.util.Tool; public class WordCountMapReduce extends Configuration implements Tool { } |
2、 Map类
|
public
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { |
3、 Reduce类
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { |
4、 run方法
public int run(String[] args) throws Exception { |
5、 main方法
public static void main(String[] args) throws Exception { |
五、打包JAR,在YARN上运行
1、 将打包好的jar包放在
2、 运行jar
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/yarn jar /opt/mysource/mapreduce.jar com.chybinmy.hadoop.mapreduce.WordCountMapReduce /wordcountdemo/input/wordcount.input /wordcountdemo/output3
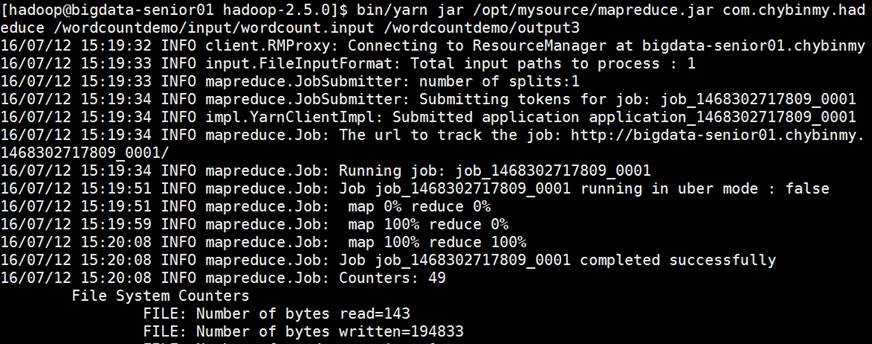
3、 查看结果
|
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -text /wordcountdemo/output3/part* hadoop 3 hbase 1 hive 2 mapreduce 1 spark 2 sqoop 1 storm 1 |
六、以WordCount为例理解MapReduce并行运行过程
1、 流程图
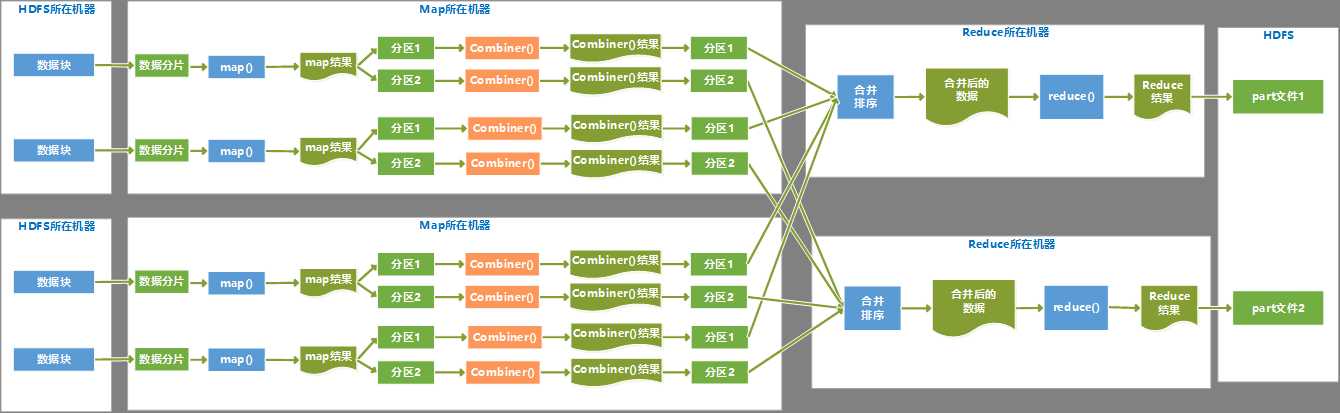
2、 执行过程描述
(1) 每个分片数据分配一个map任务,任务内容是用户写的map函数,map函数是尽量运行在数据分片的机器上,这样保证了“数据本地优化”。
(2) map任务的结果是各自排好序的,各个map结果进行再次排序合并后,作为reduce任务的输入。
(3) reduce任务执行reduce函数来处理数据,得到最终结果后,存入HDFS。
(4) 会有多个reduce任务,每个reduce任务的输入都来自于许多map任务,map任务和reduce任务之间是需要传输数据的,占用网络资源,影响效率,为了减少数据传输,可以在map()函数后,添加一个combiner函数来对结果做预处理。
标签:
原文地址:http://www.cnblogs.com/chybin/p/5685730.html