标签:
整体思路
整体分三步:
1、记录日志
1、记录日志采用UDP协议写入大数据平台,大数据平台采用Hive表来存储日志信息。
2、写入日志的工作,封装了一个Auto.Lib3.Dealer.Log.dll,这个dll要依赖ZooKeeperNet.dll 和 log4net.dll。这三个dll文件地址如下:
|
dll文件 |
TFS上路径 |
|
Auto.Lib3.Dealer.Log.dll |
$/dealer/MCH/CommonLib/Auto.Lib3.Logging.dll |
|
ZooKeeperNet.dll |
$/dealer/MCH/CommonLib/ZooKeeperNet.dll |
|
log4net.dll |
$/dealer/MCH/CommonLib/log4net.dll |
2、分析日志
可以在HUE里分析日志,也可以用Hadoop客户机分析日志,分析日志就是从Hive表里读取数据,进行各种变换数据(分组、排序、算术运算等)得到想要的结果的过程。
可以将分析的结果数据导出到SQL Server中,用于显示或者导出
3、显示分析结果
将分析结果用各种方式展示给用户,常见的显示方式有:图标、列表、导出Excel。
技术架构
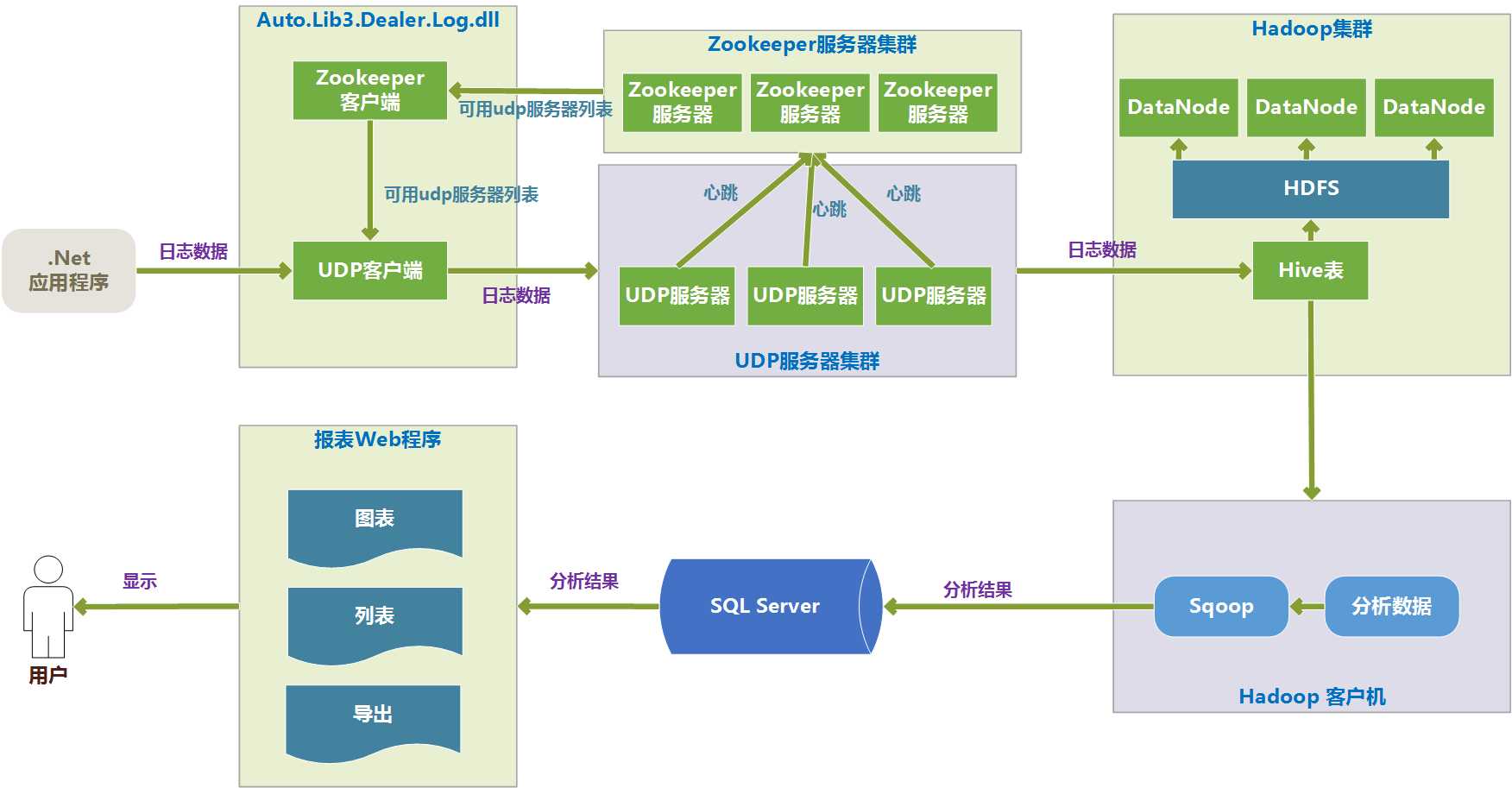
![]()
1、.net站点调用Auto.Lib3.Dealer.Log.dll来写日志,传递的参数只有一个日志数据,另外需要配置一个 zookeeper集群的连接信息(包括IP和端口号),参数名为:zk.connect
2、Auto.Lib.Dealer.Log.dll 封装了两部分内容:Zookeeper客户端和UDP客户端。
UDP客户端负责将日志信息发送给UDP服务器,因为UDP服务器是个集群,UDP不知道要发送给那个UDP服务器,所以要去Zookeeper客户端查询哪些UDP服务器是当前可用的。
Zookeeper客户端负责从Zookeeper集群查询可用的UDP服务器列表,并实时监听UDP服务器列表的变化,一旦UDP服务器列表有变化,就能监听到,并更新存储在Zookeeper客户端的“可用UDP服务器列表”,供UDP客户端使用。
3、Zookeeper集群用来保证UDP集群的高可用,(高可用的含义是:集群中就算有一部分服务器宕机,也能保证正常地对外提供服务。)
· Zookeeper集群能够保证UDP服务高可用的原理是:UDP集群中各个机器都定时地给Zookeeper发送心跳,告诉Zookeeper我还活着,可以提供服务,一旦Zookeeper检测不到某一台UDP服务器发送来的心跳后,就从可用服务器列表中,将这台UDP服务器删除掉,同时会通知所有正在监听的Zookeeper客户端,Zookeeper客户端刷新可用UDP服务器列表。这样就保证这些客户端能及时知道UDP服务器集群的变化,一直都是使用可用的UDP服务器,达到UDP集群的高可用目的
·
选举制度:Zookeeper集群也能保证自身的高可用,保证自身高可用的原理是,Zookeeper集群中的各个机器分为Leader和Follower两个角色,写入数据时,要先写入Leader,Leader同意写入后,再通知Follower写入。客户端读取数时,因为数据都是一样的,可以从任意一台机器上读取数据。
这里Leader角色就存在单点故障的隐患,高可用就是解决单点故障隐患的。Zookeeper从机制上解决了Leader的单点故障问题,Leader是哪一台机器是不固定的,Leader是选举出来的。选举流程是,集群中任何一台机器发现集群中没有Leader时,就推荐自己为Leader,其他机器来同意,当超过一半数的机器同意它为Leader时,选举结束,所以Zookeeper集群中的机器数据必须是奇数。这样就算当Leader机器宕机后,会很快选举出新的Leader,保证了Zookeeper集群本身的高可用。
· 写入高可用:集群中的写入操作都是先通知Leader,Leader再通知Follower写入,实际上当超过一半的机器写入成功后,就认为写入成功了,所以就算有些机器宕机,写入也是成功的。
· 读取高可用:zookeeperk客户端读取数据时,可以读取集群中的任何一个机器。所以部分机器的宕机并不影响读取。
4、UDP服务器负责接收日志数据,并定时地写入Hive表。
5、Hive表中的数据实际上是存储在HDFS上的,HDFS是分布式文件系统,在HDFS上的文件是先切分为块,然后将各个块分布式地存储在很多DataNode上的,一个DataNode就是一台机器,同时每一个块会在不同的机器上存储多个副本,当某一个DataNode宕机时,可以用其他副本读取数据,这样存储方式也是高可用的。
到此,日志记录过程结束!
=====================================================================
接下来,是日志的分析、显示过程。
6、日志的分析在Hadoop客户机上进行,Hadoop客户机是一个可以使用Hadoop集群的机器,在Hadoop客户机上利用Hive语句来查询统计数据,将统计的结果数据存储在HDFS上,再利用Sqoop工具导出到SQL Server库中。
7、接下来是将数据显示的过程,一般是将Sql server库中的数据用程序变成图表、列表、导出Excel的方式给用户来看。
记录日志代码实现
. 1、日志格式说明
(1) 最终发给UDP服务器的日志格式如下:
日志类型名称|字段\t字段\t字段\t字段\t字段\t字段\t字段\t字段
字段的顺序要跟hive表的字段顺序完全一致,hive表的创建是让大数据部门的人员创建的。
(2) Auto.Lib3.Dealer.Log.HadoopRecort类说明
HadoopRecort有两个参数:TableName (string) 和 ValueList (List<string>),分别对应于日志格式中 | 前一部分和后一部分。
分析日志代码实现
前面已经将数据存储在了Hive表上,接下来就是分析数据了。
1、临时性的分析日志可以用HUE系统来利用Hive 语句来查询统计。
可以用HUE来查询统计数据。
HUE方式可以列表显示分析结果,也可以将分析结果导出到Excel。
2、利用Hadoop客户机来分析
这种方式可以将分析结果导出到Sql Server 数据库里。
关于Auto.Lib3.Dealer.Log.dll实现
这个DLL功能可以分为两部分:对Zookeeper客户端的封装、对UDP客户端的封装
一、Zookeeper客户端
1、封装Zookeeper客户端的原因
用UDP服务来接收日志信息,目前部署了7台UDP服务器集群,利用Zookeeper来保证UDP服务的高可用。Zookeeper是个本身就高可用的集群,它能帮助其他集群实现高可用。
Zookeeper实现高可用的原理是:每台UDP服务器定时向Zookeeper集群发送心跳报告自己还活着,Zookeeper集群会记录当前活着的可用UDP服务器列表,并供Zookeeper客户端查询。Zookeeper客户端会在Zookeeper集群上注册一个监听,当可用UDP服务列表发生变化时,会实时通知Zookeeper客户端,从而zookeeper客户端可以实时更新自己的列表,保证zookeeper客户端连接的都是可用的UDP服务器。
所以,就封装了一个Zookeeper客户端组件,Auto.Lib3.Dealer.Log.dll 中发送日志时,首先要根据Zookeeper客户端查询可用的UDP服务器列表。
2、预期的代码介绍
(1)zookeeper客户端初始化时执行initZookeeper方法,来实例化一个客户端并建立一个监听。
(2)refreshIp 方法是从zookeeper集群上查询目前可用的udp服务列表。
(3)GetNextUDPServer方法是publice方法,是随机从可用的服务器列表中取一个,提供给调用方。
(4)Watcher类是监听类,当zookeeper集群中的可用的UDP服务器列表发送变化时,会实时通知这个监听类,并执行这个类中的Process方法,这个方法里,重新刷新可用的UDP服务器列表。
二、UDP客户端
1、其他应用程序通过调用Auto.Lib3.Dealer.Log.dll中的UDP客户端来发送日志。
2、代码介绍
主要代码在UDPClient、UDPAgent类中
(1) UDPClient类中实现对日志信息的拼接和发送
(2) UDPAgent类是个代理类,创建了一个线程池,以多线程方式发送UDP请求。因为是新开线程发送日志,所以发送日志对主体原有业务线程性能影响不大。
标签:
原文地址:http://www.cnblogs.com/chybin/p/5690400.html