标签:
一、统计学的三大基本原则和两大定理
变异性原则(变量的变异是做所有统计模型的基础,如果没有变异的数据,根本不需要分析)、社会分组原则(变量的变异性如何解决,即通过变量分组,例如根据性别分成男、女等)、社会情景原则(你得出的假设检验和统计结果适合于什么场景)。
中心极限定理,随着样本数量的增加,样本均值的抽样分布接近正态分布。大数定理,随机试验中,尽管每次出现结果不同,但是大量重复试验出现的结果的平均值确几乎总是接近于期望值。
二、概率与概率分布
统计学是证伪理论,是没有绝对的真理的,所有的结论都是建立在概率基础之上,因而概率论是其基石。
三、 几种常见分布
1.正态分布,正态概率分布是一种钟形且对称的分布,其均值、 中位值以及众数都与曲线 顶点重合。在统计推论时我们需要利用正态分布的一些特性来计算概率。概率密度函数如下:
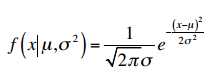
2. T分布,是在样本量很小的时候估计一个正态分布的总体的平均数时常常利用的一种概率分布,当样本量大于120时,与正态分布差异不大。用于单变量检验,两两数据比较。概率密度函数如下:
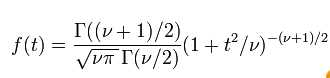
3. 卡方分布,可以证明一些很容易计算的量化数字大致服从卡方分布。例如, 若Xi是一系列独立的随机变量( i=1, …, k),且服从标准正态分布, 则一个新的随机变量 服从卡方分布。常用卡方分布的特征来检验一个实际观察到的分布和一个理论上的分布的拟合程度。在列联表的分析中,也要用到卡方分布来检验行和列之间的关联程度。
4. F分布,一个F-分布的随机变量是两个卡方分布变量的比率。F分布在方差分析和线性回归分析模型的比较与选择中有着广泛的运用。
四、假设检验
假设检验即通过样本统计量来检验总体参数的过程。假设检验的思想:是建立在小概率事件不会发生的基础上,如果小概率事件出现,则说明原假设不成立。前提是等概率抽样。我认为学习这部分之前必须先搞清楚你的变量类型和变量个数与统计方法的关系。首先在双变量分析中,只有一个因变量和一个自变量。在多元回归分析中,只有一个因变量,但会有多个自变量;而在其他更加复杂的多因变量分析模型, 如结构方程模型等, 则有多个因变量和自变量。定量分析致力于寻求因变量的最佳估计值。其逻辑思路是通过了解一个变量与另一变量之间的关系,再通过后者已知信息来估计该因变量的未知信息。具体每个变量类型与统计方法之间的对应关系如下图:
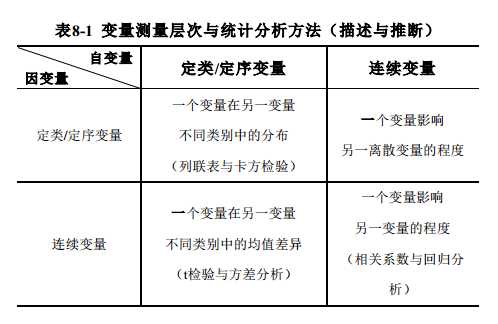
下面列举存在的以下几种情况:
1. 一个总体与一个给定均值的差异检验(单变量的情况。比如身高;给定均值是1.7m,检验班级的身高是否为1.7m)——Z检验、T检验
此时可以用Z检验,得到Z值。在假设检验时,我们通常会把样本统计量(如均值)转化为对应的标准正态分布的标准值(Z),即构造统计量,算出Z值。当然,在不同的检验中,得到Z值的公式会有所不同。而在正态分布中,计算Z值的公式如下:
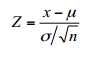
但现实研究中往往无法得知总体的标准差(σ), 就通常采用样本的标准差![]() 作为总体标准差(σ) 的估计值。 大样本情况下,这种替代无可厚非,但在小样本的情况下,其抽样分布则与正态分布存在细微差异,呈现t分布。 此时,须计算的检验统计量对应的应为t 值而非Z值,即服从t分布。
作为总体标准差(σ) 的估计值。 大样本情况下,这种替代无可厚非,但在小样本的情况下,其抽样分布则与正态分布存在细微差异,呈现t分布。 此时,须计算的检验统计量对应的应为t 值而非Z值,即服从t分布。
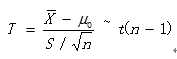
2. 两个正态总体比较是否存在显著差异(双变量情况。一个自变量是连续变量,比如身高,另一个自变量是分类变量,但该类别只有两类,比如性别,检验男人的身高和女人的身高有没有显著差异)——双样本T检验
当自变量有两个类别( 如男和女、两个时间段)或有两个变量(如一个因变量与一个自变量)时,可以通过t 检验分析两组均值(或比例)之间的差异。例如, 在两个总体中独立进行随机抽样( 样本量分别为 n1、 n2) , 并计算它们之间均值的差,其所对应的t值为:
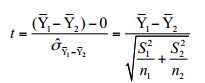
3. 同一个样本的两个正态总体比较(双变量情况。一个自变量是连续变量,比如成绩,另一个自变量是分类变量,比如培训,检验培训前后,成绩是否显著发生变化)——配对样本T检验

4. 多个正态总体比较是否存在差异(一个自变量是连续变量,比如麦子产量,另一个自变量是分类变量但该类别不止两类,比如化肥浓度,有A\B\C三种浓度,检验化肥的浓度对于麦子的产量有没有显著影响)——方差检验
当存在多个变量均值或比例差异的比较时,若继续采用 t 检验,就需要进 行多次两两间的比较,甚为烦琐,亟需一种整合的 t 检验。而方差分析(ANOVA) 可以比较多个组间均值或比例差异的统计方法。
所谓方差,就是观测值与均值间差异的平方和。对方差的分析,可以分为单因素、双因素及多因素方差分析。若只研究一个变动的因素,就称为单因素方差分析;若研究两个变动的因素,就称为双因素方差分析;若研究两个以上的变动因素,则称为多因素方差分析。
方差分析前提条件:正态分布、同方差、独立、随机抽样。构造的统计量为F统计量。
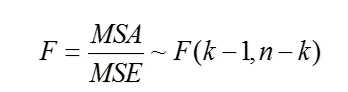
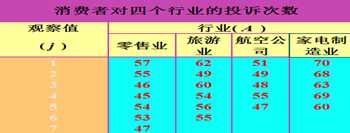
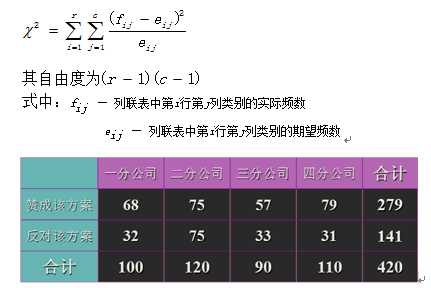
5. 两个定类变量指标比较——列联分析
两个定类变量关系的分析,可以构造列联表,列出事件的发生频数,并求出期望频数。根据期望频数与实际频数越接近说明两个定类变量越独立的思想,由此构建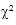 统计量:
统计量:
6. 两个连续变量指标比较——相关分析、回归分析
两个连续变量之间的关系可以用到相关分析,即皮尔森相关(两个连续变量):

斯皮尔曼相关系数(一个连续变量,一个定序变量):

如果深入到探究两个变量之间是否存在因果关系,以及影响的程度,则需要进行回归分析,这是大学计量经济学几乎一学期的课程,在此就不做具体说明。
标签:
原文地址:http://www.cnblogs.com/fionacai/p/5692876.html