标签:
为了降低传输数据的容量,我们通常会对数据进行压缩。数据压缩算法有些是无损的,有些是有损的,主要目标是降低存储空间和传输量。
数据压缩的压缩率通常取决于数据本身,数据压缩算法的选择主要取决于数据。
一 游程编码 是一种十分简单的无损数据压缩算法,在某些情况下非常有用
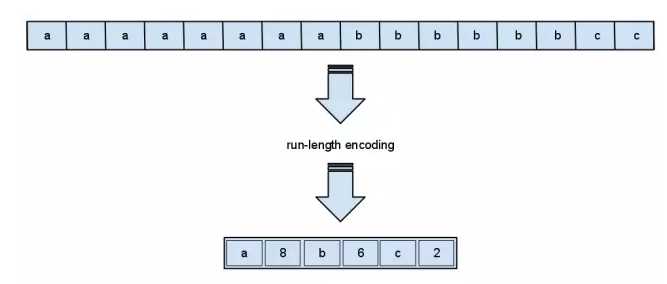
游程算法适用于大量重复元素序列,不仅适用于字符串,对数组也能取得很好的结果。
二 位图压缩
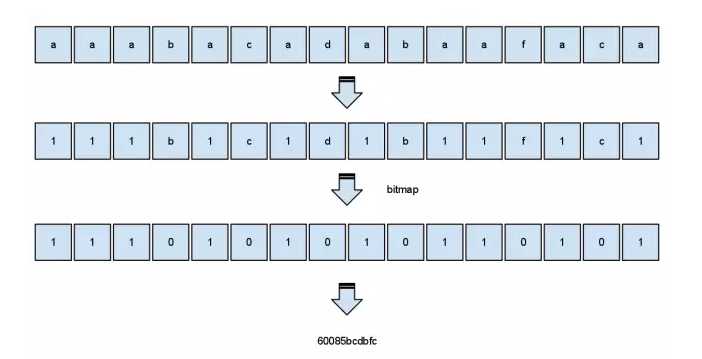
1110,1010,1011,0101 DAB5 十进制为60085
使用位图压缩字符串,可以使用序列中的位来保存给定元素出现的位置,这个序列可以简单的转化为十进制。如abababababababab,表示为1010101010101010,十进制为43690,十六进制为AAAA。
三 图编码和模式替换 游程编码的两种变形
日常英语中就有些图,例如“the”,“and”,“ing”(例如在“waiting”中),“aa”,“tt”,“ee”这些双字母。事实上我们可以通过添加字符串两边的空格来扩展这些图。这样我们可以不编码“the”,而编码“ the ”,就可以编码5个字符了(3个字符,2个空格),从而获得更好的压缩率。
但是有时候失真压缩可能有用,比如在我们要去除空格的情况中。字符串“successfully accomplished”表达的意思和“successfully accomplished”确实完全相同。在这种情况下,我们能够很简单地去除那些空格。我们可以像这样用一个标记去代替一长串的空格:“successfully@6 accomplished”,这样可以使输入字符串完全没有损失,但是我们也有另一种选择,可以直接把那些空格直接扔掉。这个选择取决于我们的目的是什么,只有当我们很确定删除换行标记符和制表标记符能够完全保证表达出相同的意思时,才能下决定扔掉那些空格。
对纯文本压缩选择图压缩方法比游程编码好。
模式替换是图编码的一种变形。但是第一个问题是需要知道了解将要被压缩的这门语言,第二是关于解压缩,我们需要构造一个用来解压缩的字典,如果能找到比3个字母长的模式会很好,但是如果找不到那么压缩率就会比较低。
四 相对编码
让我们看看下面的输入流——一段给定的年份(90年的)。
1991,1991,1999,1998,1991,1993,1992,1992
这里有39个字符,我们能够压缩它们。我们通常使用的方法是去掉前面的“19”。
91,91,99,98,91,93,92,92
现在我们得到一个更短的字符串,但在保留第一个年份的基础上可以更进一步的压缩。其余的年份均相对于该年份。
91,0,8,7,0,2,1,1
此时传输的数据量减少了很多(从39降至16——超过50%)。然而,我们首先需要考虑一些问题,因为数据流的格式不会总是如此巧合。下面字符流会怎样?
91,94,95,95,98,100,101,102,105,110
我们看到数值100在区间的中间,使用该值作为相对编码的基准很方便。那么上面的数据流就变成如下:
-9,-6,-5,-5,-2,100,1,2,5,10
问题在于决定哪一个数值作为基准值并不容易。如果数据以不同方式排列会怎样。
96,97,98,99,100,101,102,103,999,1000,1001,1002
此时,数值“100”不能作为基准值,因为以该值为基准将得到如下结果:
-4,-3,-2,-1,100,1,2,3,899,900,901,902
对某基准值附近的相对值分组将会更加方便。
(-4,-3,-2,-1,100,1,2,3)(-1,1000,1,2)
然而,找出基准值并不那么容易。编码格式也并不那么重要。
五 前缀编码 前向编码,通过移除冗余数据来降低数据量的算法。
请看下面的字典。
use
used
useful
usefully
usefulness
useless
uselessly
uselessness
为了不使用纯文本保存这些单词或者在网络上传输,我们可以用前缀编码进行压缩(编码)。
很明显,每一个单词都以表中的第一个单词“use”为前缀。所以我们很容易将它们压缩成下面的数组。
$data = array(
0 => 'use',
1 => '0d',
2 => '0ful',
3 => '0fully',
4 => '0less',
5 => '0lessly',
6 => '0lessness',
);
显然这并不是最佳的压缩结果,在不仅仅使用第一个词作为前缀的情况下,我们可以更进一步压缩。
$data = array(
0 => 'use',
1 => '0d',
2 => '0ful',
3 => '2ly',
4 => '0less',
5 => '4ly',
6 => '4ness',
);
此时的压缩更好,好消息是解码是一个相对简单的过程。但棘手的部分在于压缩本身。问题是选择合适的前缀非常困难。第一个例程的前缀选择很简单,但事实上,大多时候数据很混乱。的确,对于随机产生的数据压缩过程将非常困难,算法过程不仅很慢,而且难以实现。
举例:日期和时间前缀,电话号码,地理坐标
input: (1998, 1992, 1932, 1924, 2001, 2012)
output: (#19, 98, 92, 32, 24, #20, 01, 12)
一旦解码器读到#字符,它就知道下面的数为前缀。
电话号码是前缀编码的典型应用。不仅仅是国际代码,移动网络运营商的电话号码也使用前缀编码。如果我们要传输电话号码,假设是英国的,我们可以用一些更短的东西替换开头的“+44”。
当然还有后缀编码,与前缀编码类似。
来自:
http://mp.weixin.qq.com/s?__biz=MzI1MTIzMzI2MA==&mid=2650560059&idx=1&sn=8e9285e79a19c84ec3667a595533d30e&scene=0#wechat_redirect
http://mp.weixin.qq.com/s?__biz=MzI1MTIzMzI2MA==&mid=2650560060&idx=1&sn=2656626d727449828123cbf2b9f040b7&scene=0#wechat_redirect
http://mp.weixin.qq.com/s?__biz=MzI1MTIzMzI2MA==&mid=2650560063&idx=1&sn=b072fc8376f0291e20a92e48b0f67ea2&scene=0#wechat_redirect
http://mp.weixin.qq.com/s?__biz=MzI1MTIzMzI2MA==&mid=2650560066&idx=1&sn=5af04ba689b5d492a13cd62de2dfea98&scene=0#wechat_redirect
http://mp.weixin.qq.com/s?__biz=MzI1MTIzMzI2MA==&mid=2650560084&idx=1&sn=ed18f9949ebbe9ffd51fd80fd4649f45&scene=0#wechat_redirect
标签:
原文地址:http://www.cnblogs.com/yuxiye/p/5700704.html