标签:
有这么一个问题,说我在看一篇文章,觉得不错,想要从书架的众多书籍中找相类似的文章来继续阅读,这该怎么办?

于是我们想到暴力解决法,我一篇一篇的比对,找出相似的
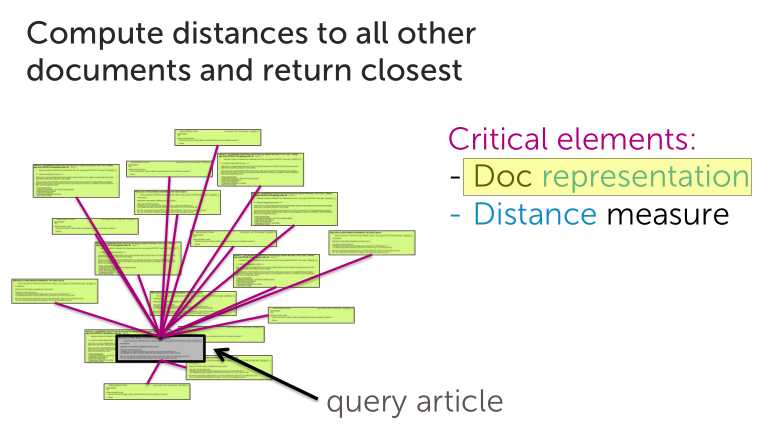
最近邻的概念很好理解,我们通过计算知道了每一篇文章和目标文章的距离,选择距离最小的那篇作为最相近的候选文章或者距离最小的一些文章作为候选文章集。
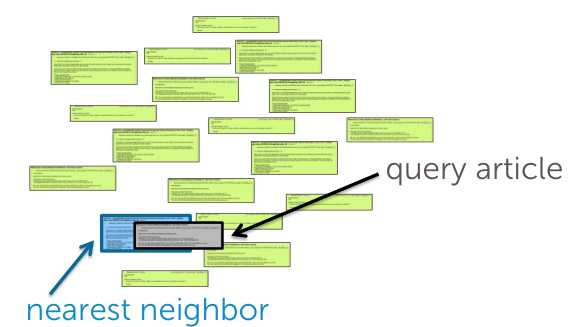
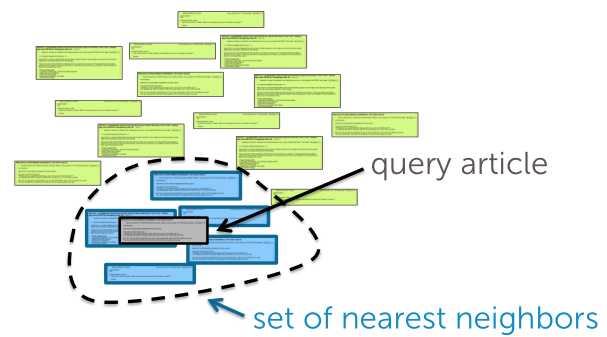
让我们转化成更数学的表述方式:


这其实就是一个衡量相似性的问题(•?How do we measure similarity?)要完成上述想法,我们需要解决两大难题:
文档的表示方法,经常听到的就是词袋模型
词袋模型文本被看作是无序的词汇集合,忽略语法、词序,假设每个词的出现都是独立的,不依赖与其他词是否出现。这样就可以将一篇文章表示出一系列词构成的长向量,向量元素是词频。显然,词频方法没有充分考虑特有词汇的重要性,进而我们引入TF-IDF算法。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
距离的计算,在相似性(http://www.cnblogs.com/sxbjdl/p/5708681.html)一文中有具体学习,此处不再啰嗦
OK 接下来解决下一问题 搜索算法(•?How do we search over articles?)
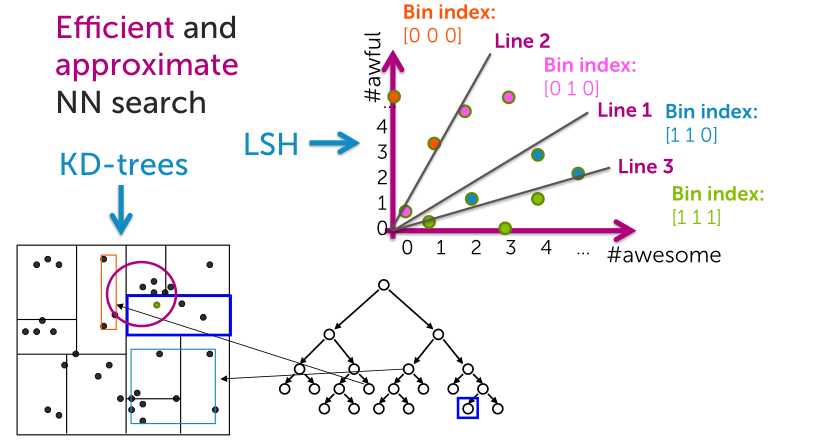
k近邻法的最简单实现是线性扫描,这时要计算输入实例与每一个训练实例的距离,当训练集很大时,计算非常耗时,这种方法是不可行的。为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。
具体方法有很多,这里介绍kd树方法(详见http://blog.csdn.net/likika2012/article/details/39619687)
?KD-trees are cool, but…
-?Non-trivial to implement efficiently
-?Problems with high-dimensional data
故而,引出LSH
locality sensitive hashing(局部敏感哈希LSH )
参看博文http://blog.csdn.net/icvpr/article/details/12342159
低维小数据集我们可以通过线性查找找到相似点,海量高维数据也采用该方法效率十分低下(非常耗时)。为了解决该问题,我们采用一些类似索引的技术来加快查找(如最近邻查找、近似最近邻查找)。LSH是ANN(Approximate Nearest Neighbor)中的一类方法,其基本思想是:如果我们对原始数据进行一些hash映射后,我们希望原先相邻的两个数据能够被hash到相同的桶内,具有相同的桶号。对原始数据集合中所有的数据都进行hash映射后,我们就得到了一个hash table,这些原始数据集被分散到了hash table的桶内,每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的,当然也存在不相邻的数据被hash到了同一个桶内。因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话,那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。
需要注意的是,LSH并不能保证一定能够查找到与query data point最相邻的数据,而是减少需要匹配的数据点个数的同时保证查找到最近邻的数据点的概率很大。
LSH的应用场景:查重、图像检索、音乐检索、指纹匹配
标签:
原文地址:http://www.cnblogs.com/sxbjdl/p/5721264.html