标签:
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比。 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作。 DSM是一种通用的内存数据抽象,但这种通用性同时也使其在商用集群上实现有效的容错性和一致性更加困难。
RDD与DSM主要区别在于[2],不仅可以通过批量转换创建(即“写”)RDD,还可以对任意内存位置读写。 RDD限制应用执行批量写操作,这样有利于实现有效的容错。 特别是,由于RDD可以使用Lineage(血统)来恢复分区,基本没有检查点开销。 失效时只需要重新计算丢失的那些RDD分区,就可以在不同节点上并行执行,而不需要回滚(Roll Back)整个程序。
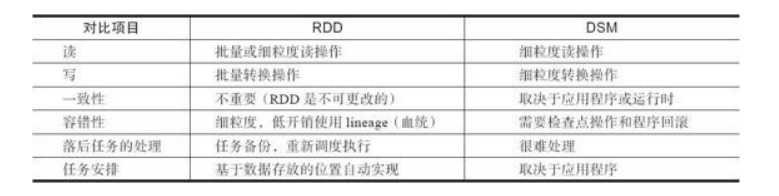
表 RDD与DSM的对比
通过备份任务的复制,RDD还可以处理落后任务(即运行很慢的节点),这点与MapReduce类似,DSM则难以实现备份任务,因为任务及其副本均需读写同一个内存位置的
数据。
与DSM相比,RDD模型有两个优势。 第一,对于RDD中的批量操作,运行时将根据数据存放的位置来调度任务,从而提高性能。 第二,对于扫描类型操作,如果内存不足以缓存整个RDD,就进行部分缓存,将内存容纳不下的分区存储到磁盘上。
另外,RDD支持粗粒度和细粒度的读操作。 RDD上的很多函数操作(如count和collect等)都是批量读操作,即扫描整个数据集,可以将任务分配到距离数据最近的节点上。 同时,RDD也支持细粒度操作,即在哈希或范围分区的RDD上执行关键字查找。
1)Transformations(变换)和Action(行动)算子维度。
2)在Transformations算子中再将数据类型维度细分为:Value数据类型和Key-Value对数据类型的Transformations算子。 Value型数据的算子封装在RDD类中可以直接使用,KeyValue对数据类型的算子封装于PairRDDFunctions类中,用户需要引入importorg.apache.spark.SparkContext._才能够使用。 进行这样的细分是由于不同的数据类型处理思想不太一样,同时有些算子是不同的。
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5723977.html