标签:
策略梯度方法(Policy Gradient Methods)
前面介绍了很多关于 state or state-action pairs 方面的知识,为了将其用于控制,我们学习 state-action pairs的值,并且将这些值函数直接用于执行策略和选择动作.这种形式的方法称为:action-value methods.
下面要介绍的方法也是计算这些 action (or state) values,但是并非直接用于选择 action, 而是直接表示该策略,其权重不依赖于任何值函数.
1.1 Actor-Critic Methods.
Actor-critic methods 是 TD方法,有一个独立的记忆结构来显示的表示策略,而与 value function 无关.该策略结构称为:actor,因为其用于选择动作,预测的值函数被称为:critic,因为其用于批判 actor 执行的动作.学习是on-policy的: the critic must learn about and critique whatever policy is currently being followed by the actor. The critique takes the form of a TD error. 尺度信号是单纯的 critic 的输出,并且引导 actor and critic 的学习,像下图所示:
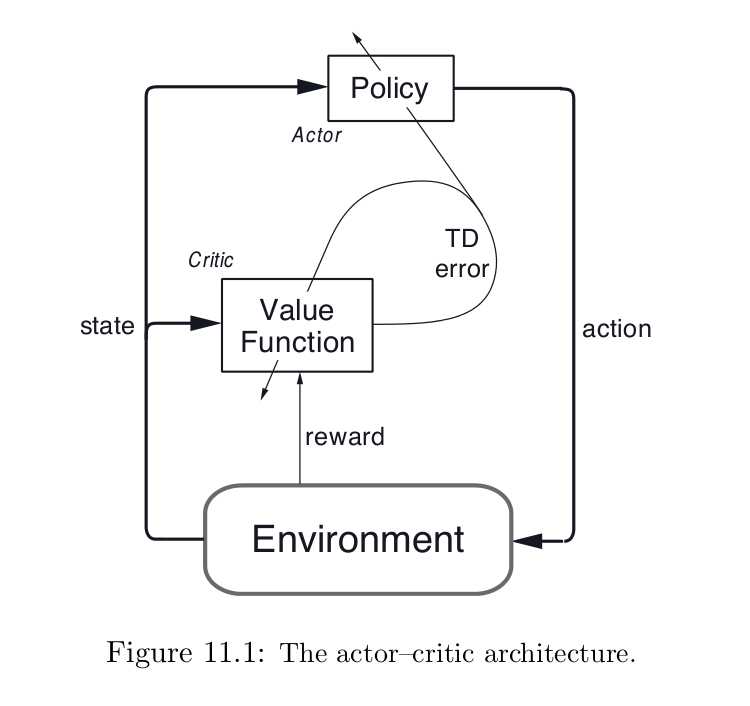
Actor-critic methods 是 gradient-bandit methods自然的拓展到 TD-learning和全部的RL学习问题.
DRL之:策略梯度方法 (Policy Gradient Methods)
标签:
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/5725685.html