标签:
按照我做项目的经验,来了项目,首先是分析项目的目的和需求,了解这个项目属于什么问题,要达到什么效果。然后提取数据,做基本的数据清洗。第三步是特征工程,这个属于脏活累活,需要耗费很大的精力,如果特征工程做的好,那么,后面选择什么算法其实差异不大,反之,不管选择什么算法,效果都不会有突破性的提高。第四步,是跑算法,通常情况下,我会把所有能跑的算法先跑一遍,看看效果,分析一下precesion/recall和f1-score,看看有没有什么异常(譬如有好几个算法precision特别好,但是recall特别低,这就要从数据中找原因,或者从算法中看是不是因为算法不适合这个数据),如果没有异常,那么就进行下一步,选择一两个跑的结果最好的算法进行调优。调优的方法很多,调整参数的话可以用网格搜索、随机搜索等,调整性能的话,可以根据具体的数据和场景进行具体分析。调优后再跑一边算法,看结果有没有提高,如果没有,找原因,数据 or 算法?是数据质量不好,还是特征问题还是算法问题。一个一个排查,找解决方法。特征问题就回到第三步再进行特征工程,数据质量问题就回到第一步看数据清洗有没有遗漏,异常值是否影响了算法的结果,算法问题就回到第四步,看算法流程中哪一步出了问题。如果实在不行,可以搜一下相关的论文,看看论文中有没有解决方法。这样反复来几遍,就可以出结果了,写技术文档和分析报告,再向业务人员或产品讲解我们做的东西,然后他们再提建议/该需求,不断循环,最后代码上线,改bug,直到结项。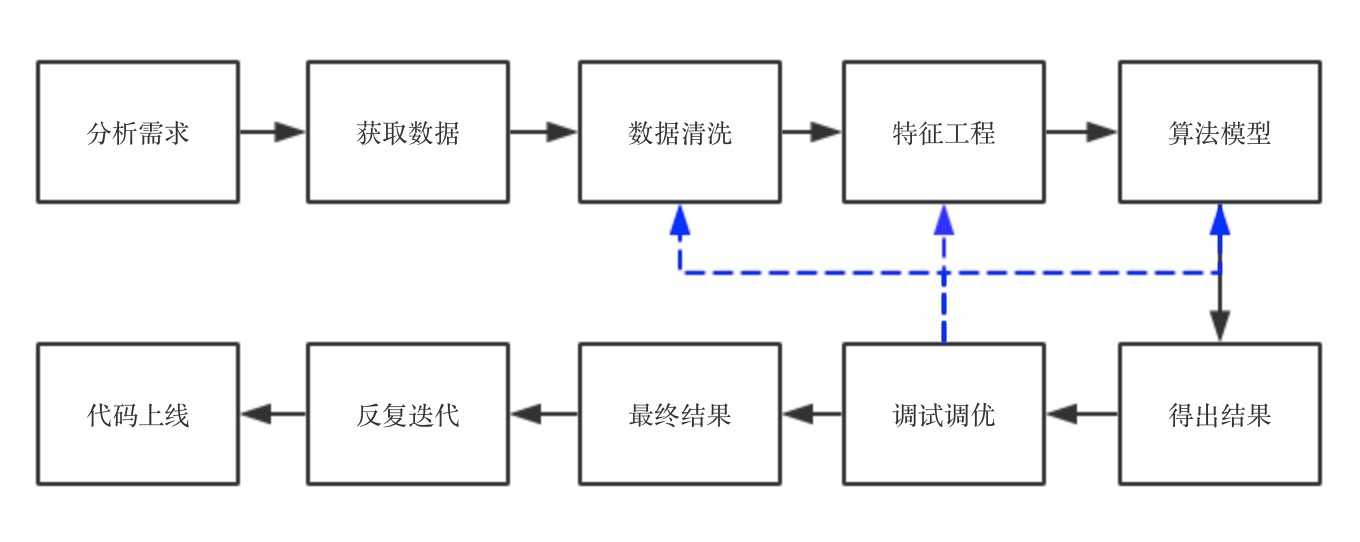
在真实数据中,我们拿到的数据可能包含了大量的缺失值,可能包含大量的噪音,也可能因为人工录入错误导致有异常点存在,对我们挖据出有效信息造成了一定的困扰,所以我们需要通过一些方法,尽量提高数据的质量。数据清洗一般包括以下几个步骤:
import scipy as spdata = sp.genfromtxt("web_traffic.tsv",delimiter = "\t")
可以看到,第2列已经出现了缺失值,现在我们来看一下缺失值的数量:
>>> x = data[:,0]>>> y = data[:,1]>>> sp.sum(sp.isnan(y))81.直接删除----适合缺失值数量较小,并且是随机出现的,删除它们对整体数据影响不大的情况
2.使用一个全局常量填充---譬如将缺失值用“Unknown”等填充,但是效果不一定好,因为算法可能会把它识别为一个新的类别,一般很少用
3.使用均值或中位数代替----优点:不会减少样本信息,处理简单。缺点:当缺失数据不是随机数据时会产生偏差.对于正常分布的数据可以使用均值代替,如果数据是倾斜的,使用中位数可能更好。
4.插补法
1)随机插补法----从总体中随机抽取某个样本代替缺失样本2)多重插补法----通过变量之间的关系对缺失数据进行预测,利用蒙特卡洛方法生成多个完整的数据集,在对这些数据集进行分析,最后对分析结果进行汇总处理3)热平台插补----指在非缺失数据集中找到一个与缺失值所在样本相似的样本(匹配样本),利用其中的观测值对缺失值进行插补。优点:简单易行,准去率较高缺点:变量数量较多时,通常很难找到与需要插补样本完全相同的样本。但我们可以按照某些变量将数据分层,在层中对缺失值实用均值插补4)拉格朗日差值法和牛顿插值法(简单高效,数值分析里的内容,数学公式以后再补 = =)5.建模法可以用回归、使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定。例如,利用数据集中其他数据的属性,可以构造一棵判定树,来预测缺失值的值。
以上方法各有优缺点,具体情况要根据实际数据分分布情况、倾斜程度、缺失值所占比例等等来选择方法。一般而言,建模法是比较常用的方法,它根据已有的值来预测缺失值,准确率更高。三.异常值处理1.简单的统计分析拿到数据后可以对数据进行一个简单的描述性统计分析,譬如最大最小值可以用来判断这个变量的取值是否超过了合理的范围,如客户的年龄为-20岁或200岁,显然是不合常理的,为异常值。在python中可以直接用pandas的describe():2.3?原则如果数据服从正态分布,在3?原则下,异常值为一组测定值中与平均值的偏差超过3倍标准差的值。如果数据服从正态分布,距离平均值3?之外的值出现的概率为P(|x-u| > 3?) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
import pandas as pddata = pd.read_table("web_traffic.tsv",header = None)data.describe()>>>0 1count 743.000000 735.000000mean 372.000000 1962.165986std 214.629914 860.720997min 1.000000 472.00000025% 186.500000 1391.00000050% 372.000000 1764.00000075% 557.500000 2217.500000max 743.000000 5906.000000data = pd.DataFrame({‘v1‘:[‘a‘]*5+[‘b‘]* 4,‘v2‘:[1,2,2,2,3,4,4,5,3]})data.duplicated()data.drop_duplicates()
list0=[‘b‘,‘c‘, ‘d‘,‘b‘,‘c‘,‘a‘,‘a‘]方法1:使用set()list1=sorted(set(list0),key=list0.index) # sorted outputprint( list1)方法2:使用 {}.fromkeys().keys()list2={}.fromkeys(list0).keys()print(list2)方法3:set()+sort()list3=list(set(list0))list3.sort(key=list0.index)print(list3)方法4:迭代list4=[]for i in list0:if not i in list4:list4.append(i)print(list4)方法5:排序后比较相邻2个元素的数据,重复的删除def sortlist(list0):list0.sort()last=list0[-1]for i in range(len(list0)-2,-1,-1):if list0[i]==last:list0.remove(list0[i])else:last=list0[i]return list0print(sortlist(list0))五.噪音处理噪音,是被测量变量的随机误差或方差。我们在上文中提到过异常点(离群点),那么离群点和噪音是不是一回事呢?观测量(Measurement) = 真实数据(True Data) + 噪声 (Noise)。离群点(Outlier)属于观测量,既有可能是真实数据产生的,也有可能是噪声带来的,但是总的来说是和大部分观测量之间有明显不同的观测值。噪音包括错误值或偏离期望的孤立点值,但也不能说噪声点包含离群点,虽然大部分数据挖掘方法都将离群点视为噪声或异常而丢弃。然而,在一些应用(例如:欺诈检测),会针对离群点做离群点分析或异常挖掘。而且有些点在局部是属于离群点,但从全局看是正常的。
标签:
原文地址:http://www.cnblogs.com/iathena/p/959079d15fe5f70da150c9470f025550.html