标签:
作者:白宁超
 2016年8月3日19:47:55
2016年8月3日19:47:55
【摘要】:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果。在中文分词、中文人名识别和歧义消解等任务中都有应用。本文源于笔者做语句识别序列标注过程中,对条件随机场的了解,逐步研究基于自然语言处理方面的应用。成文主要源于自然语言处理、机器学习、统计学习方法和部分网上资料对CRF介绍的相关的相关,最后进行大量研究整理汇总成体系知识。文章布局如下:第一节介绍CRF相关的基础统计知识;第二节介绍基于自然语言角度的CRF介绍;第三节基于机器学习角度对CRF介绍,第四节基于统计学习角度对相关知识介绍;第五节对统计学习深度介绍CRF,可以作为了解内容。(本文原创,转载请注明出处:条件随机场知识扩展延伸。)
【自然语言处理:漫步条件随机场系列文章(一)】:前戏:一起走进条件随机场
【自然语言处理:漫步条件随机场系列文章(二)】:基于自然语言处理角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(三)】:基于机器学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(四)】:基于统计学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(五)】:条件随机场知识扩展延伸
矩阵表示形式前提条件:假设P(y|x)是线性链条件随机场,给定观测序列x,相应的标记序列y的条件概率。引进特殊的起点和终点状态标记y0 = start,yn+1 = stop,这时Pw(y|x) 可以通过矩阵形式表示。(实际上,特殊点的引用大家都有接触,诸如学习隐含马尔科夫模型中向前算法解决了似然度问题,viterbi算法解决解码问题,向前向后算法解决学习参数。)
对观测序列x的每一个位置i=1, 2,..., n+1,定义一个m阶矩阵(m是标记yi取值的个数)
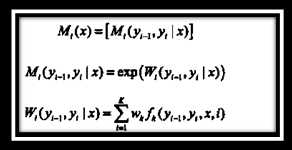
这样给定观测序列x,标记序列y的非规范化概率可以通过n+1个矩阵的乘积
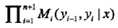
表示。于是,条件概率Pw(y|x)是
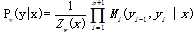
中,Zw(x)为规范化因子,是n+1个矩阵的乘积的(start,stop)元素:
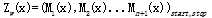
注意,y0= start,yn+1 = stop表示开始状态与终止状态,规范化因子Zw(x)是以start为起点stop为重点通过状态的所有路径y1y2...yn的非规范化概率
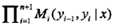
之和。
下面通过一个例子来说明“范化因子Zw(x)是以start为起点stop为重点通过状态的所有路径y1y2...yn的非规范化概率之和”这个事实
实例解析
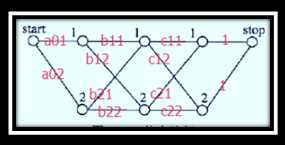
给定一个如上图所示的线性链条件随机场,观测序列x,状态序列y,i=1,2,3,n=3,标记yi∈{1,2},假设y0=start=1,y4=stop=1,各个位置的随机矩阵M1(x),M2(x),M3(x),M4(x)分别是
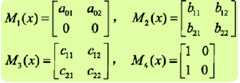
试求状态序列y以start为起点stop为终点所有路径的非规范化概率及规范化因子。
实例解答:
从start到stop对应于y=(1,1,1),y=(1,1,2), ..., y=(2,2,2)个路径的非规范化概率分别是:
a01b11c11,a01b11c12,a01b12c21,a01b12c22
a02b21c11,a01b21c12,a02b22c21,a02b22c22
然后按式11.12求规范化因子,通过计算矩阵乘积M1(x) M2(x) M3(x) M4(x)可知,其第一行第一列的元素为a01b11c11+ a01b11c12 + a01b12c21+ a01b12c22+a02b21c11 + a01b21c12+ a02b22c21 + a02b22c22,恰好等于从start到stop的所有路径的非规范化概率之和,即规范化因子Z(x)。
在之前的介绍中我们已近知道,条件随机场的概率计算问题是给定条件随机场P(Y|X),输入序列x和输出序列y,计算条件概率P(Yi=yi | x),P(Yi-1 =yi-1, Yi=yi | x)以及相应数学期望的问题。为了方便起见,像隐马尔可夫模型那样,引进前向-后向向量,递归的计算以上概率及期望值。这样的算法称为前向-后向算法。
对每个指标i =0,1,...,n+1,定义前向向量ai(x):
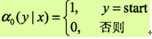
递推公式为
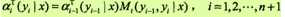
又可表示为
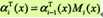
ai(yi|x)表示在位置i的标记是yi并且到位置i的前部分标记序列的非规范化概率,若yi可取的值有m个,那ai(x)就是m维的列向量。同样,对每个指标i =0,1,...,n+1,定义后向向量βi(x):
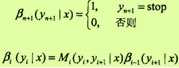
又可表示为
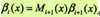
βi(yi|x)表示在位置i的标记为yi并且从i+1到n的后部分标记序列的非规范化的概率。
由前向-后向定义不难得到:
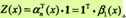
这里,若ai(x)是m维的列向量,那1就是元素均为1的m维列向量。
概率计算
按照前向-后向向量的定义,很容易计算标记序列在位置i是标记yi的条件概率和在位置i-1与i是标记yi-1和yi的条件概率:
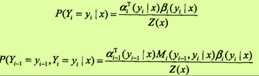
其中, Z(x)= anT(x)·1
期望值计算
利用前向-后向向量,可以计算特征函数关于联合分布P(X, Y)和条件分布P(Y | X)的数学期望。特征函数fk关于条件分布P(Y |X)的数学期望是
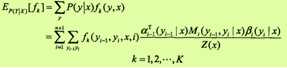
其中,Z(x)= anT(x)·1
则特征函数fk关于联合分布P(X, Y)的数学期望是
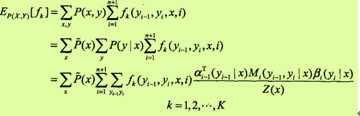
其中, Z(x)= anT(x)·1
特征函数数学期望的一般计算公式。对于转移贴纸tk(yi-1, yi, x, i),k=1,2,...,K1,可以将式中的fk换成tk;对于状态特征,可以将式中的fk换成si,表示sl(yi, x, i),k = K1 +1,l = 1,2,...,K2。有了式11.32 ~11.35,对于给定的观测序列x和标记序列y,可以通过一次前向扫描计算ai及Z(x),通过一次后向扫描计算βi,从而计算所有的概率和特征的期望。
条件随机场模型实际上是定义在时序数据上的对数线性模型,其学习方法包括极大似然估计和正则化的极大似然估计。
具体的优化实现算法有改进的迭代尺度法IIS、梯度下降法以及拟牛顿法。
1)进的迭代尺度法(IIS)
已知训练数据集,由此可知经验概率分布
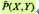
可以通过极大化训练数据的对数似然函数来求模型参数。训练数据的对数似然函数为
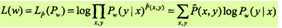
当Pw是一个由
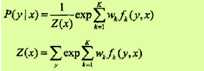
给出的条件随机场模型时,对数似然函数为
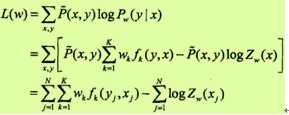
IIS通过迭代的方法不断优化对数似然函数改变量的下界,达到极大化对数似然函数的目的。
假设模型的当前参数向量为w=(w1,w2, ..., wK)T,向量的增量为δ=(δ1,δ2, ..., δK)T,更新参数向量为w +δ=(w1+δ1, w2 +δ2, ..., wk+δk)T。在每步迭代过程中,IIS通过一次求解下面的11.36和11.37,得到δ=(δ1,δ2, ..., δK)T。关于转移特征tk的更新方程为:
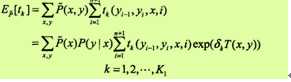
关于状态特征sl的更新方程为:
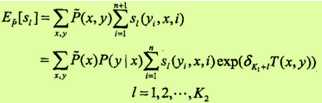
这里T(x, y)是在数据(x, y)中出现所有特征数的综合:
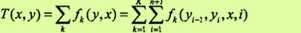
于是算法整理如下。
算法:条件随机场模型学习的改进的迭代尺度法
输入:特征函数t1,t2, ..., tK1,s1, s2, ..., sK2;经验分布
输出:参数估计值 ;模型 。
过程:

2)拟牛顿法
对于条件随机场模型
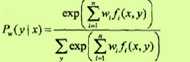
学习的优化目标函数是
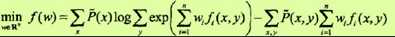
其梯度函数是
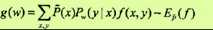
拟牛顿法的BFGS算法如下:算法:条件随机场模型学习的BFGS算法

【知乎】北京航空航天大学 计算机专业博士在读33 人赞同
大致命名实体识别的方法可以可以分为四个大类型:
有监督学习方法:
HMM http://www.nlpr.labs.gov.cn/2005papers/gjhy/gh71.pdf
SVM Biomedical named entity recognition using two-phase model based on SVMs
CRF http://psb.stanford.edu/psb11/conference-materials/proceedings%201996-2010/psb08/leaman.pdf
当然还有决策树最大熵等方法。基本每个模型都会在这个问题上试一遍的。
无监督学习方法:Unsupervised named-entity extraction from the Web: An experimental study
半监督学习方法:Minimally-supervised extraction of entities from text advertisements
混合方法:多种模型结合 Recognizing named entities in tweets
主要介绍三种主流算法,CRF,字典法和混合方法。
CRF:
用过CRF的都知道,CRF是一个序列标注模型,指的是把一个词序列的每个词打上一个标记。一般通过,在词的左右开一个小窗口,根据窗口里面的词,和待标注词语来实现特征模板的提取。最后通过特征的组合决定需要打的tag是什么。
而在CRF for Chinese NER这个任务中,提取的特征大多是该词是否为中国人名姓氏用字,该词是否为中国人名名字用字之类的,True or false的特征。所以一个可靠的百家姓的表就十分重要啦~在国内学者做的诸多实验中,效果最好的人名可以F1测度达到90%,最差的机构名达到85%。
基于条件随机场的中文命名实体识别特征比较研究--《第四届全国信息检索与内容安全学术会议论文集(上)》2008年
字典法:
字典法需要掌握的是一种快速搜索算法trie-tree,我相信很多人应该对这个算法已经有所了解。在NER中就是把每个字都当开头的字放到trie-tree中查一遍,查到了就是NE。中文的trie-tree需要进行哈希,因为中文字符太多了,不像英文就26个。
混合法:
对六类不同的命名实体采取不一样的手段进行处理,例如对于人名,进行字级别的条件概率计算。
例如我们需要算
其中Sur代表中国人姓氏,Dgb代表中国人名首字,Dge代表中国人名尾字。
而机构则在词级别进行此概率计算。
我知道的系统有:
中文
1、哈工大 语言云(语言技术平台云 LTP-Cloud)
2、上海交大 赵海 主页 分词 自然语言 计算语言学 机器学习
英文:
Stanford NER
BANNER(生物医学)
Minor Third
【知乎】标注看上去好像就是在序列上做分类。
然而实际上标注跟分类最大的区别就是:标注采的特征里面有上下文分类结果,这个结果你是不知道的,他在“分类”的时候是跟上下文一起"分类的"。因为你要确定这个词的分类得先知道上一个词的分类,所以这个得整句话的所有词一起解,没法一个词一个词解。
而分类是根据当前特征确定当前类别,分类的时候不需要考虑上下文的分类结果,但可以引入上下文的特征。
比如说命名实体识别,你采的特征如果是:{当前词,当前词性,当前词语义角色,上一个词,上一个词的词性}
那这样跟分类没有什么区别。如果你采的特征是:{当前词,当前词性,当前词语义角色,上一个词,上一个词的标签,上一个词的词性}
那就是序列标注了,
作者:赵孽
链接:http://www.zhihu.com/question/26405809/answer/74191113
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
【1】 数学之美 吴军 著
【2】 机器学习 周志华 著
【3】 统计自然语言处理 宗成庆 著(第二版)
【4】 统计学习方法(191---208) 李航
【5】 知乎 网络资源
【自然语言处理】:【NLP】揭秘马尔可夫模型神秘面纱系列文章
【自然语言处理】:【NLP】大数据之行,始于足下:谈谈语料库知多少
【自然语言处理】:【NLP】蓦然回首:谈谈学习模型的评估系列文章
【自然语言处理】:【NLP】快速了解什么是自然语言处理
【自然语言处理】:【NLP】自然语言处理在现实生活中运用
声明:关于此文各个篇章,本人采取梳理扼要,顺畅通明的写作手法。系统阅读相关书目和资料总结梳理而成,旨在技术分享,知识沉淀。在此感谢原著无私的将其汇聚成书,才得以引荐学习之用。其次,本人水平有限,权作知识理解积累之用,难免主观理解不当,造成读者不便,基于此类情况,望读者留言反馈,便于及时更正。本文原创,转载请注明出处:条件随机场知识扩展延伸。
标签:
原文地址:http://www.cnblogs.com/baiboy/p/crf5.html