标签:
前面我们举了回归和分类得到例子。在回归的例子中,$y \mid x;\theta \sim N(u,\sigma ^{2})$,在分类例子中,$y\mid x;\theta \sim Bbernoulli(\phi)$
广义线性模型是基于指数函数族的,指数函数族原型为:
$p(y;\eta) = b(y)exp(\eta^{T}T(y)-a(\eta))$
$\eta$为自然参数,$T(y)$为充分统计量,一般情况下$T(y)=y$。选择固定的T,a,b定义一个分布,参数为$\eta$。
对于伯努利分布(均值为$\phi$),有:
$p(y=1,\phi)=\phi;p(y=0;\phi)=1-\phi$
$p(y;\phi) = \phi^{y}(1-\phi)^{1-y}$
$p(y;\phi) = exp(ylog\phi +(1-y)log(1-\phi))$
$p(y;\phi) = exp((log(\frac{\phi}{1-\phi}))y+log(1-\phi))$
因此有:
$T(y) = y$
$a(\eta) = -log(1-\phi)$
$a(\eta) = log(1+e^{\eta})$
$b(y)=1$
对于高斯分布,有:
$p(y;u) = \frac{1}{\sqrt{2\pi}}exp(-\frac{1}{2}(y-u)^{2})$
$p(y;u) = \frac{1}{\sqrt{2\pi}}exp(-\frac{1}{2}y^{2})\cdot exp(uy=\frac{1}{2}u^{2})$
因此有:
$\eta = u$
$T(y) = y $
$a(\eta) = \frac{u^{2}}{2} = \frac{\eta^{2}}{2}$
$b(y) = (\frac{1}{\sqrt{2\pi}})exp(-\frac{1}{2}y^{2})$
1. $y \mid x;\theta \sim ExponentialFamily(\eta)$
2. 给定x,我们的目标是预测T(y),大部分情况下T(y)=y,因此我们可以选择预测输出h(x),$h(x) =E\left [ y \mid x \right ]$
3. 自然参数$\eta$和输入x是线性相关的,$\eta = \theta^{T}x$
普通最小二乘法是GLM模型的一种特例:y是连续的,给定x后的y的条件分布是高斯分布$N(u,\sigma^{2})$。因此令指数函数族的分布为高斯分布。正如前面,高斯分布U作为指数函数族时,$u=\eta$。因此有:
$h_{\theta}(x) = E\left [ y \mid x ; \theta \right ] = u = \eta =\theta^{T}x$
逻辑回归中y只取0和1,因此使用伯努利分布作为指数函数族的分布,因此$\phi = \frac{1}{1+e^{-\eta}}$。进一步,由$y \mid x;\theta \sim Bernoulli(\phi)$,则$E\left [ y \mid x;\theta \right ] = \phi $,得到:
$h_{\theta}(x) = E\left [ y \mid x ; \theta \right ] $
$h_{\theta}(x) = \phi $
$h_{\theta}(x) = \frac{1}{1+e^{-\eta}}$
$h_{\theta}(x) = \frac{1}{1+e^{-\theta^{T}x}}$
在逻辑回归中,y离散取值只有两个,现在考虑当y取多个值的情况,$y\in {1,2,...,k}$。
为了参数化具有k个可能的输出的多项式,我们可以使用k个参数$\phi_{1},...,\phi_{2}$来表示每个输出的概率。但是这些参数是冗余的,因为这k个参数之和为1。所以我们只需要参数化k-1个变量:$\phi_{i} = p(y=i;\phi) ~~ p(y=k;\phi) = 1-\sum_{i=1}^{k-1}\phi_{i}$,为了方便,我们令$\phi_{k}= 1-\sum_{i=1}^{k-1}\phi_{i}$,但记住它并不是一个参数,而是由其它k-1个参数值决定。
为了使多项式为指数函数族分布,定义以下$T(y) \in R^{k-1}$:
$ T(1) =\begin{bmatrix} 1\\ 0\\ 0\\ \vdots \\0 \end{bmatrix}$
$ T(2) =\begin{bmatrix} 0\\ 1\\ 0\\ \vdots \\0 \end{bmatrix}$
$ T(k-1) =\begin{bmatrix} 0\\ 0\\ 0\\ \vdots \\1 \end{bmatrix}$
$ T(k) =\begin{bmatrix} 1\\ 0\\ 0\\ \vdots \\0 \end{bmatrix}$
跟前面不同的是,这里T(y)并不等于y,T(y) 在这里是一个k-1维向量,而不是一个实数。令$(T(y))_{i}$表示$T(y)$的第i个元素。
接着定义一个函数$1{\cdot}$,当参数为true时,函数值为1,反之为零。例如 1{2=3}=0.
因此,$(T(y))_{i}=1{y=i}$,进一步我们有$E[(T(y))_{i}]=P(y=i)=\phi_{i}$。
接下来说明该多项式也属于指数函数族:
$p(y;\phi) = \phi_{1}^{1\{y=1\}} \phi_{2}^{1\{y=2\}} \cdots \phi_{k}^{1\{y=k\}}$
$p(y;\phi) = \phi_{1}^{1\{y=1\}} \phi_{2}^{1\{y=2\}} \cdots \phi_{k}^{1-\sum_{i=1}^{k-1}(T(y))_{i}}$
$p(y;\phi) = \phi_{1}^{(T(y))_{1}} \phi_{2}^{(T(y))_{2}} \cdots \phi_{k}^{1-\sum_{i=1}^{k-1}(T(y))_{i}}$
$p(y;\phi) = exp((T(y))_{1}log(\phi_{1}) + (T(y))_{2}log(\phi_{2}) + \cdots + (1-\sum_{i=1}^{k-1}(T(y))_{i})log(\phi_{k}))$
$p(y;\phi) =exp((T(y))_{1}log(\phi_{1}/\phi_{k})+ (T(y))_{2}log(\phi_{2}/\phi_{k})+\cdots+(T(y))_{k-1}log(\phi_{k-1}/\phi_{k})+log(\phi_{k}))$
$p(y;\phi) = b(y)exp( \eta^{T}T(y)-a(\eta))$
其中:
$ \eta =\begin{bmatrix} log(\phi_{1}/\phi_{k})\\ log(\phi_{2}/\phi_{k})\\ \vdots \\log(\phi_{k-1}/\phi_{k}) \end{bmatrix}$
$a(\eta)=-log(\eta_{k})$
$b(y)=1$
因此有以下函数关系式:
$\eta_{i}= \frac{\phi_{i}}{\phi_{k}}$
为了方便,我们定义:
$\eta_{k} = 0$
因此我们得到以下关系式:
$e^{\eta_{i}}= \frac{\phi_{i}}{\phi_{k}}$
$\phi_{k}e^{\eta_{i}} = \phi_{i}$
$\phi_{k}\sum_{i=1}{k}e^{\eta_{i}}=1$
因此我们得到以下响应函数:
$\phi_{i}= \frac{e^{\eta_{i}}}{\sum_{j=1}^{k}e^{\eta_{j}}}$
这种$\eta$到$\phi$的映射函数称为softmax函数。
令$\eta_{i}=\theta_{i}^{T}x ~~(i=1,2,...,k-1),\theta_{1},...,\theta_{k-1}\in R^{n+1}$
因此有以下条件分布:
$p(y=1 \mid x;\theta) = \phi_{i}$
$p(y=1 \mid x;\theta) = \frac{e^{\eta_{i}}}{\sum_{j=1}^{k}e^{\eta_{j}}}$
$p(y=1 \mid x;\theta) = \frac{e^{\theta_{i}^{T}x}}{\sum_{j=1}^{k}e^{\theta_{j}^{T}x}}$
损失函数:

最大似然估计:
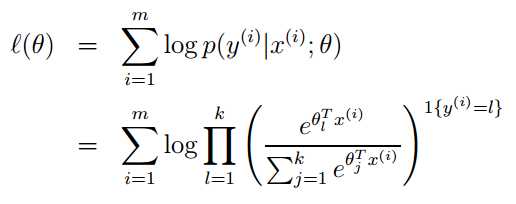
标签:
原文地址:http://www.cnblogs.com/wuchaodzxx/p/5734542.html