标签:
脏读 dirty reads:当事务读取还未被提交的数据时,就会发生这种事件。举例来说:Transaction 1修改了一行数据,然后Transaction 2在Transaction 1还未提交修改操作之前读取了被修改的行。如果Transaction 1回滚了修改操作,那么Transaction 2读取的数据就可以看作是从未存在过的。
不可重复的读 non-repeatable reads:当事务两次读取同一行数据,但每次得到的数据都不一样时,就会发生这种事件。举例来说:Transaction 1读取一行数据,然后Transaction 2修改或删除该行并提交修改操作。当 Transaction 1试图重新读取该行时,它就会得到不同的数据值(如果该行被更新)或发现该行不再存在(如果该行被删除)。
虚读(幻读)phantom read:指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入新的记录,当之前事务再次读取该范围记录时,会产生幻行。
事务场景是这样的:
对于同一个银行帐户A内有200元,甲进行提款操作100元,乙进行转帐操作100元到B帐户。如果事务没有进行隔离可能会并发如下问题:
在多个事务并发做数据库操作的时候,如果没有有效的避免机制,就会出现种种问题。大体上有三种问题,归结如下:
1.丢失更新.如果两个事务都要更新数据库一个字段X,x=100
事务A 事务B
读取X=100
读取X=100
写入x=X+100
写入x=X+200
事务结束x=200
事务结束x=300
最后x==300
这种情况事务A的更新就被覆盖掉了、丢失了。丢失更新说明事务进行数据库写操作的时候可能会出现的问题。
2.不可重复读.一个事务在自己没有更新数据库数据的情况,同一个查询操作执行两次或多次的结果应该是一致的;如果不一致,就说明为不可重复读。还是用上面的例子
事务A 事务B
读取X=100
读取X=100
读取X=100
写入x=X+100
读取X=200
事务结束x=200
事务结束x=200
这种情况事务A多次读取x的结果出现了不一致,即为不可重复读。再有一情况就是幻影事务A读的时候读出了15条记录,事务B在事务A执行的过程中删除(增加)了1条,事务A再读的时候就变成了14(16)条,这种情况就叫做幻影读。不可重复读说明了做数据库读操作的时候可能会出现的问题。
3.脏读(未提交读)防止一个事务读到另一个事务还没有提交的记录。如:
事务A 事务B
读取X=100
写入x=X+100
读取X=200
事务回滚x=100
读取X=100
事务结束x=100
x锁(排他锁):被加锁的对象只能被持有锁的事务读取和修改,其他事务无法在该对象上加其他锁,也不能读取和修改该对象.s锁(共享锁):被加锁的对象可以被持锁事务读取,但是不能被修改,其他事务也可以在上面再加s锁。
封锁协议
三级封锁协议: 在运用X锁和S锁对数据对象加锁时,还需要约定一些规则 ,例如何时申请X锁或S锁、持锁时间、何时释放等。称这些规则为封锁协议(Locking Protocol)。对封锁方式规定不同的规则,就形成了各种不同的封锁协议。
三级协议的主要区别在于什么操作需要申请封锁,以及何时释放。
数据库锁的粒度
所谓粒度,即细化的程度。锁的粒度越大,则并发性越低且开销大;锁的粒度越小,则并发性高且开销小。锁的粒度主要有以下几种类型:
悲观锁和乐观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示: 下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:id int;num int.两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:id int;num int.两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
1.将A的隔离级别设置为read uncommitted(未提交读)
在B未更新数据之前:客户端A: B更新数据客户端B:
B更新数据客户端B: 客户端A:
客户端A: 经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
2.将客户端A的事务隔离级别设置为read committed(已提交读)
在B未更新数据之前。客户端A: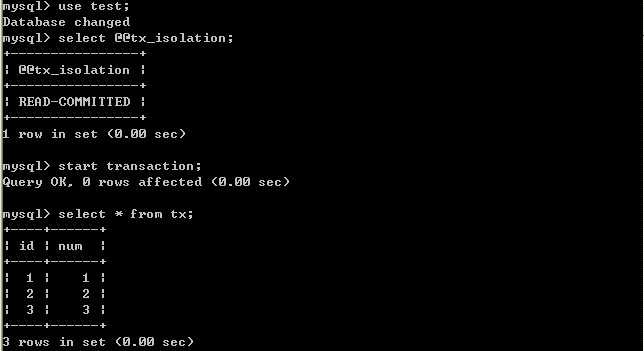 B更新数据。客户端B:
B更新数据。客户端B: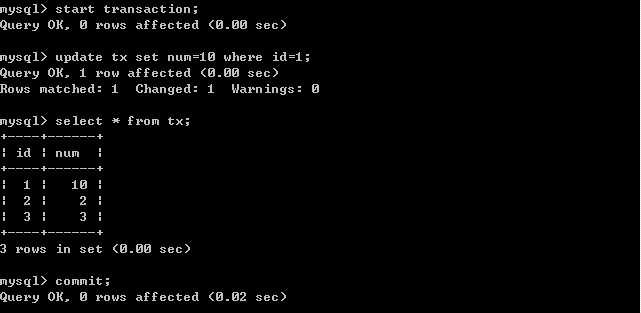 客户端A:
客户端A: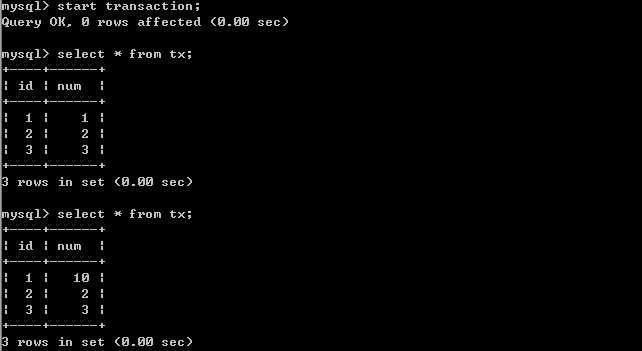 经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
3.将A的隔离级别设置为repeatable read(可重复读)
在B未更新数据之前.客户端A:
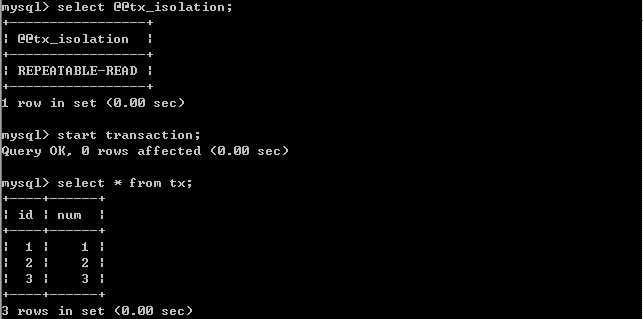 B更新数据.客户端B:
B更新数据.客户端B: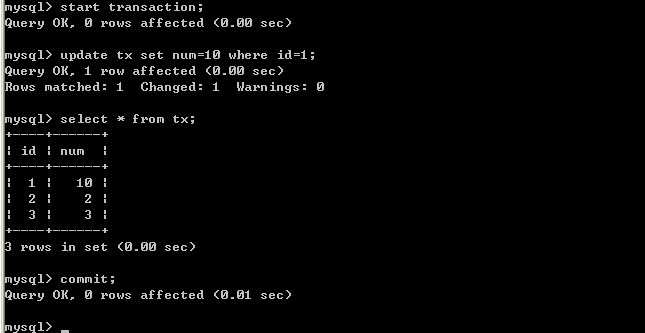 客户端A:
客户端A: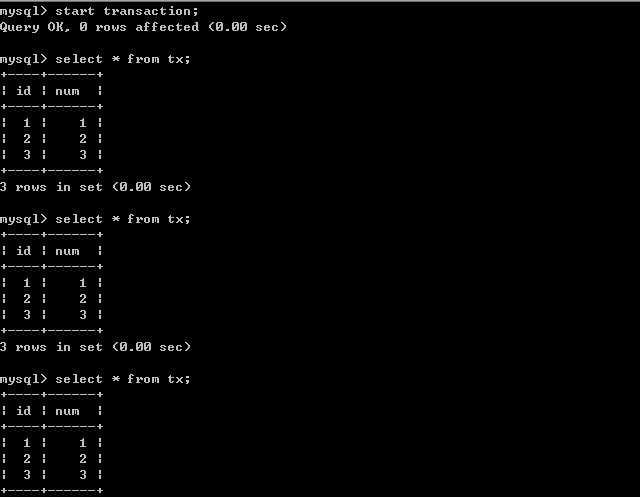 B插入数据.客户端B:
B插入数据.客户端B: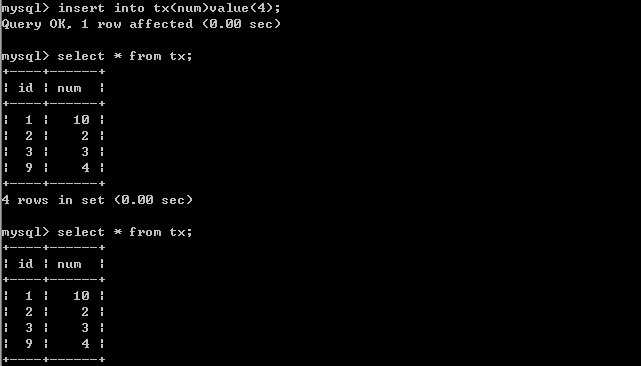 客户端A:
客户端A:
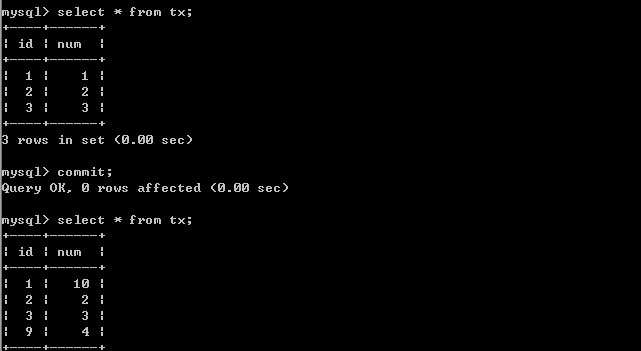 由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上的实验,就没有出现数据幻读的问题。
由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上的实验,就没有出现数据幻读的问题。
4.将A的隔离级别设置为 可串行化 (Serializable)
A端打开事务,B端插入一条记录.事务A端:
 事务B端:
事务B端: 因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
事务A提交事务。事务A端:
事务B端
serializable完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止 。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。
标签:
原文地址:http://www.cnblogs.com/wxgblogs/p/5745996.html