标签:
一.DL基础理论
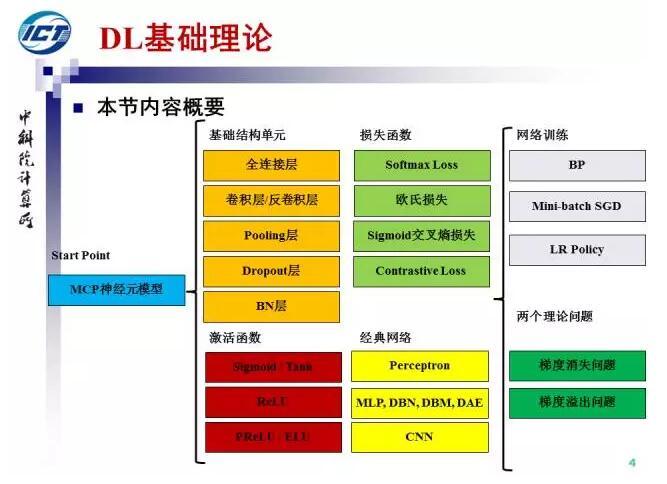 本页PPT给出了本节内容概要,我们从MCP神经元模型开始,首先回顾全连接层、卷积层等基础结构单元,Sigmoid等激活函数,Softmax等损失函数,以及感知机、MLP等经典网络结构。接下来,将介绍网络训练方法,包括BP、Mini-batch SGD和LR Policy。最后我们会介绍深度网络训练中的两个理论问题:梯度消失和梯度溢出。
本页PPT给出了本节内容概要,我们从MCP神经元模型开始,首先回顾全连接层、卷积层等基础结构单元,Sigmoid等激活函数,Softmax等损失函数,以及感知机、MLP等经典网络结构。接下来,将介绍网络训练方法,包括BP、Mini-batch SGD和LR Policy。最后我们会介绍深度网络训练中的两个理论问题:梯度消失和梯度溢出。
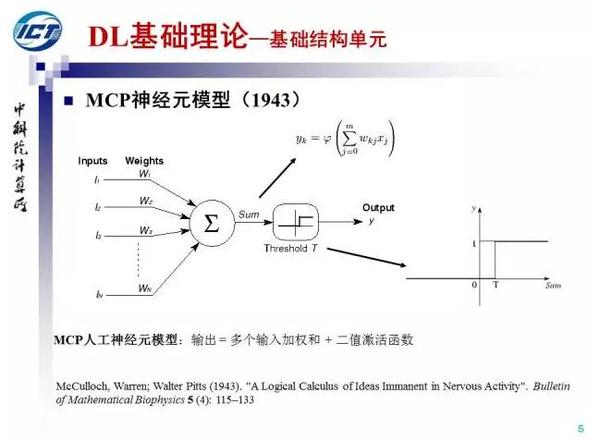 MCP神经元模型提出于1943年,可以看作是人工神经网络研究的起点。MCP是作者名字的缩写。MCP模型中包括多个输入参数和权重、内积运算和二值激活函数等人工神经网络的基础要素。MCP模型的提出甚至早于1946年第一台计算机的发明。
MCP神经元模型提出于1943年,可以看作是人工神经网络研究的起点。MCP是作者名字的缩写。MCP模型中包括多个输入参数和权重、内积运算和二值激活函数等人工神经网络的基础要素。MCP模型的提出甚至早于1946年第一台计算机的发明。
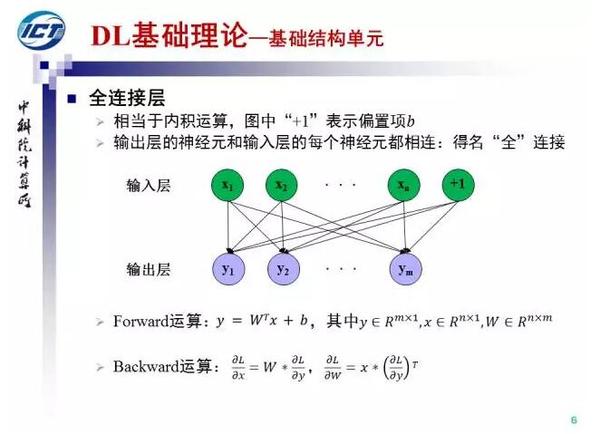 在MCP神经元模型的基础上,我们可以得到全连接结构。输入层神经元和输入层神经两两相连,故名全连接。全连接层实际上是内积运算,我们也给出了全连接层前向和后向计算的公式。
在MCP神经元模型的基础上,我们可以得到全连接结构。输入层神经元和输入层神经两两相连,故名全连接。全连接层实际上是内积运算,我们也给出了全连接层前向和后向计算的公式。
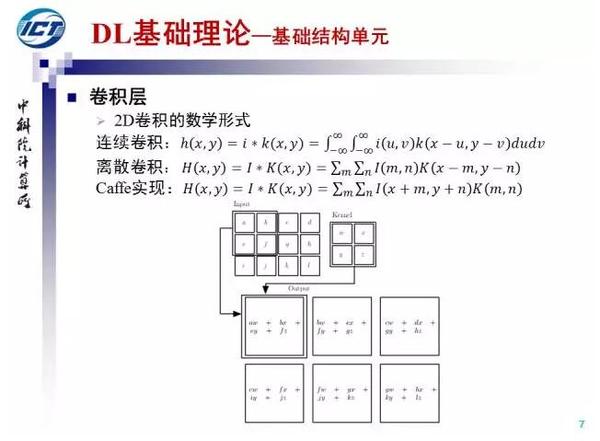 下面我们介绍卷积层,卷积是深度网络的重要结构单元之一。我们给出了2D卷积的连续和离散形式,注意卷积核需要做中心翻转。在Caffe实现中,卷积核假设已经翻转,所以卷积运算可以看作当前窗口和卷积核的一个内积(不考虑bias项),上图我们给出了一个卷积运算的示意。
下面我们介绍卷积层,卷积是深度网络的重要结构单元之一。我们给出了2D卷积的连续和离散形式,注意卷积核需要做中心翻转。在Caffe实现中,卷积核假设已经翻转,所以卷积运算可以看作当前窗口和卷积核的一个内积(不考虑bias项),上图我们给出了一个卷积运算的示意。
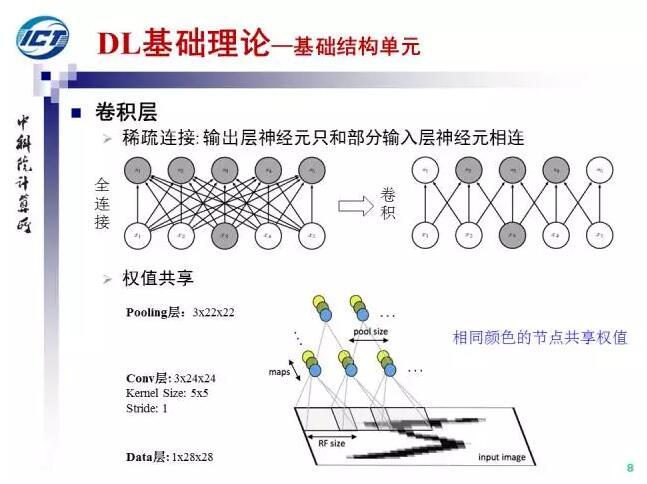 与全连接层相比,卷积层的输出神经元只和部分输入层神经元连接,同时相同响应图内,不同空间位置共享卷积核参数,因此卷积层大大降低了要学习的参数数量。
与全连接层相比,卷积层的输出神经元只和部分输入层神经元连接,同时相同响应图内,不同空间位置共享卷积核参数,因此卷积层大大降低了要学习的参数数量。
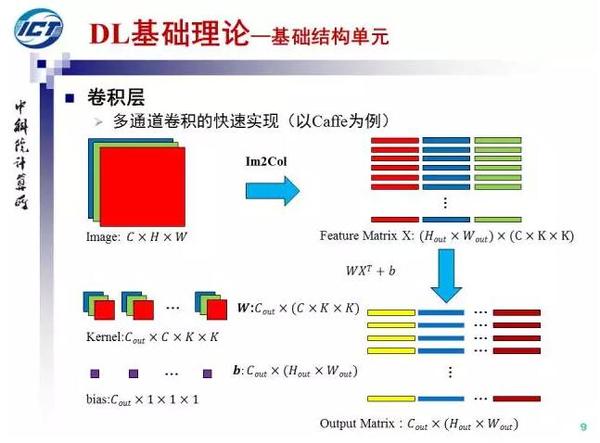 Caffe当中,为了避免卷积运算中频繁的内存访问和过深的循序嵌套,对卷积运算进行了以下加速:通过Im2Col操作一次取出所有的patch并组成矩阵,与kernel矩阵做乘法运算直接得到卷积结果。
Caffe当中,为了避免卷积运算中频繁的内存访问和过深的循序嵌套,对卷积运算进行了以下加速:通过Im2Col操作一次取出所有的patch并组成矩阵,与kernel矩阵做乘法运算直接得到卷积结果。
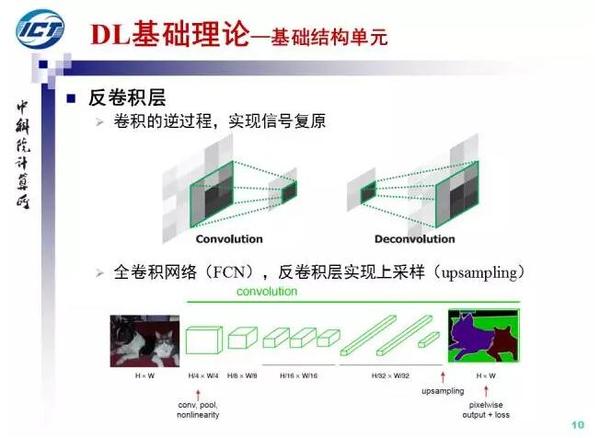 有卷积就有反卷积,反卷积是卷积的逆运算,实现了信号的复原。在全卷积网络中,反卷积层实现了图像的上采样,从而得到如输入图像大小相同的输出。
有卷积就有反卷积,反卷积是卷积的逆运算,实现了信号的复原。在全卷积网络中,反卷积层实现了图像的上采样,从而得到如输入图像大小相同的输出。
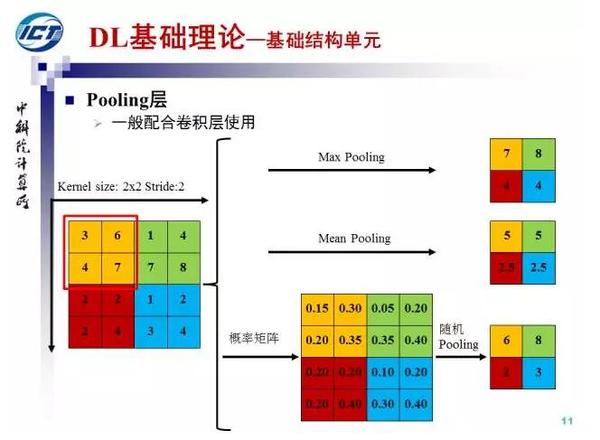
Pooling层一般配合卷积层使用,可以获得特征的不变性。常见的Pooling操作有max pooling、mean pooling和随机pooling。其中max pooling取最大值,mean pooling取均值,随机pooling按响应值的大小依概率选择。
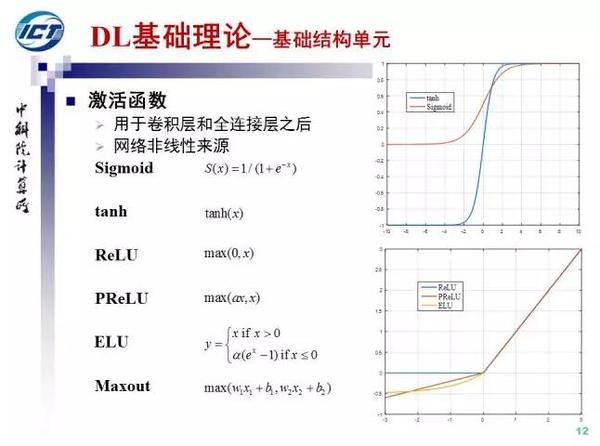 激活函数一般用于卷积层和全连接层之后,激活函数是深度网络非线性的主要来源。常见的激活函数Sigmoid, 双曲正切,ReLU(生物启发,克服了梯度消失问题), PReLU(alpha可学习), ELU和maxout。 其中PReLU和ELU都是ReLU的改进。
激活函数一般用于卷积层和全连接层之后,激活函数是深度网络非线性的主要来源。常见的激活函数Sigmoid, 双曲正切,ReLU(生物启发,克服了梯度消失问题), PReLU(alpha可学习), ELU和maxout。 其中PReLU和ELU都是ReLU的改进。
 Dropout由Hinton组提出于2012年,Dropout随机将比例为p的神经元输出设置为0,是一种避免深度网络过拟合的随机正则化策略,同时Dropout也可以看作是一种隐式的模型集成。
Dropout由Hinton组提出于2012年,Dropout随机将比例为p的神经元输出设置为0,是一种避免深度网络过拟合的随机正则化策略,同时Dropout也可以看作是一种隐式的模型集成。
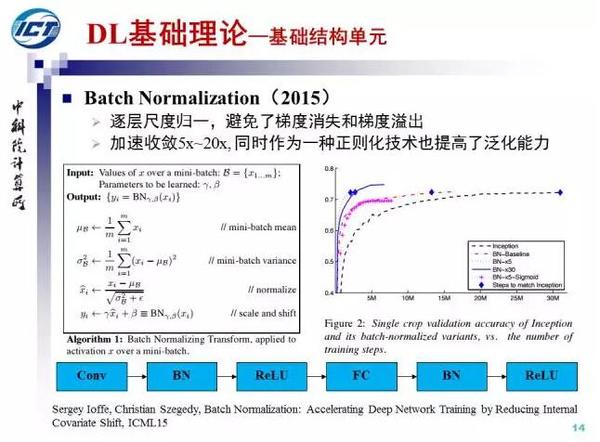 Batch Normalization提出于2015年,通过逐层尺度归一(零均值方差归一,scale和shift),BN避免了梯度消失和梯度溢出。BN可以加速收敛5x~20x, 作为一种正则化技术也提高了泛化能力。
Batch Normalization提出于2015年,通过逐层尺度归一(零均值方差归一,scale和shift),BN避免了梯度消失和梯度溢出。BN可以加速收敛5x~20x, 作为一种正则化技术也提高了泛化能力。

下面我们介绍损失函数:用于单标签分类问题的Softmax损失函数,用于实值回归问题的欧式损失函数,用于多标签分类的Sigmoid交叉熵损失和用于深度测度学习的Contrastive损失。
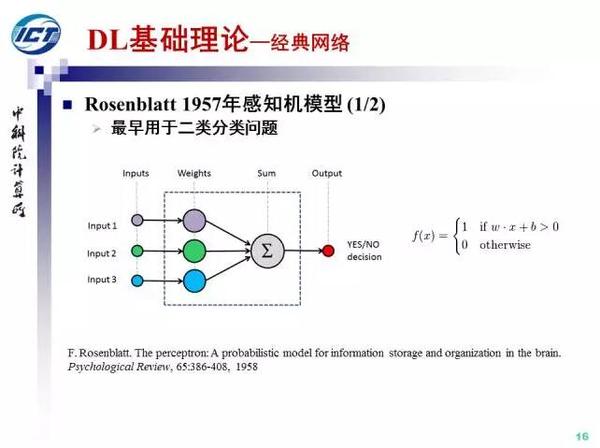 下面我们介绍经典网络结构。1957年,Rosenblatt提出了感知机模型。最早感知机模型用于解决二分类问题,在MCP模型的基础上增加了一个损失函数。随后,感知机也被扩展到多分类问题和回归问题,成为解决机器学习问题的一个通用学习器。
下面我们介绍经典网络结构。1957年,Rosenblatt提出了感知机模型。最早感知机模型用于解决二分类问题,在MCP模型的基础上增加了一个损失函数。随后,感知机也被扩展到多分类问题和回归问题,成为解决机器学习问题的一个通用学习器。
 1969年,Minsky在一本名为感知机的专著中指出,感知机不能解决XOR问题,从而宣告了感知机甚至人工神经网络研究的死刑,造成了NN长达十几年的寒冬,这也是NN研究的第一次寒冬。遗憾的是,Rosenblatt 1971年死于意外,没有等到春天的到来(下图是Rosenblatt的墓碑)。
1969年,Minsky在一本名为感知机的专著中指出,感知机不能解决XOR问题,从而宣告了感知机甚至人工神经网络研究的死刑,造成了NN长达十几年的寒冬,这也是NN研究的第一次寒冬。遗憾的是,Rosenblatt 1971年死于意外,没有等到春天的到来(下图是Rosenblatt的墓碑)。

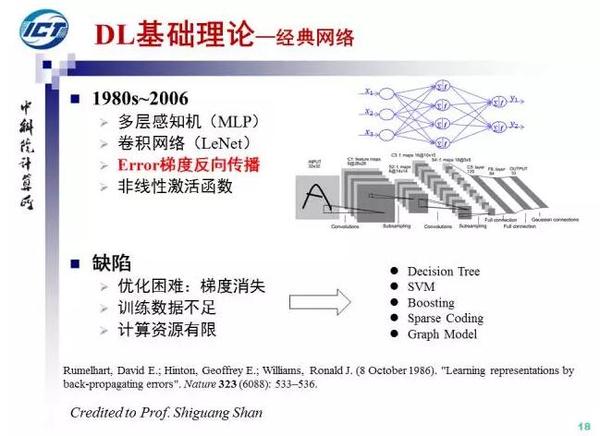 1986年之后,随着误差反向传导算法的再次发明并在Nature上发表,多层感知机和卷积神经网络成为NN研究新亮点。然而由于多层网络训练困难:梯度消失问题,训练数据和计算资源不足,NN研究在20世纪末再次进入寒冬,这段时间更为流行的方法包括决策树,SVM等,八卦一下,NN研究曾长期是一门“显学”,SVM引用次数最多的那篇文章的题目叫Support Vector Network。
1986年之后,随着误差反向传导算法的再次发明并在Nature上发表,多层感知机和卷积神经网络成为NN研究新亮点。然而由于多层网络训练困难:梯度消失问题,训练数据和计算资源不足,NN研究在20世纪末再次进入寒冬,这段时间更为流行的方法包括决策树,SVM等,八卦一下,NN研究曾长期是一门“显学”,SVM引用次数最多的那篇文章的题目叫Support Vector Network。
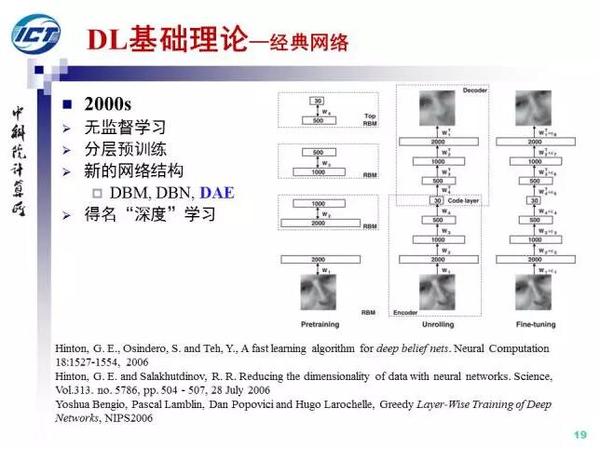 2006年,NN的研究迎来转机,Hinton、Bengio等人经过跨世纪的努力,提出了通过分层无监督预训练的策略来解决多层网络收敛困难的问题,深度学习也因此得名。
2006年,NN的研究迎来转机,Hinton、Bengio等人经过跨世纪的努力,提出了通过分层无监督预训练的策略来解决多层网络收敛困难的问题,深度学习也因此得名。
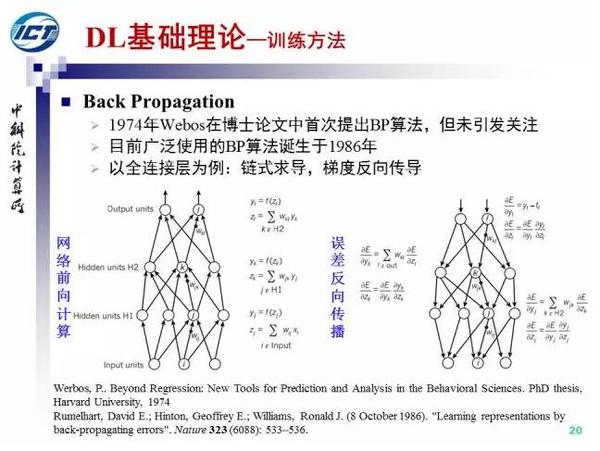 下面我们介绍优化方法。首先误差反向传导,实际上在1974年,Webos在其博士论文中就提出来BP的思想,今天我们广为使用的BP算法则由Hinton等人“重新”发明于1986年。
下面我们介绍优化方法。首先误差反向传导,实际上在1974年,Webos在其博士论文中就提出来BP的思想,今天我们广为使用的BP算法则由Hinton等人“重新”发明于1986年。
 有了BP算法传递的梯度,基于梯度下降方法,就可以对网络参数进行更新。梯度下降方法的缺点是速度慢且数据量大的时候内存不足,随机梯度下降方法的缺点是方差大导致损失函数震荡严重。两者折中的Mini-batch SGD,我们也给出了基于Mini-batch SGD的NN训练流程。
有了BP算法传递的梯度,基于梯度下降方法,就可以对网络参数进行更新。梯度下降方法的缺点是速度慢且数据量大的时候内存不足,随机梯度下降方法的缺点是方差大导致损失函数震荡严重。两者折中的Mini-batch SGD,我们也给出了基于Mini-batch SGD的NN训练流程。
 进一步的,在Mini-batch SGD中,有两个关键技术细节:weight decay和momentum. Weight decay是一种避免过拟合的正则化手段,而Momentum通过对历史梯度的moving average来避免陷入局部最优。
进一步的,在Mini-batch SGD中,有两个关键技术细节:weight decay和momentum. Weight decay是一种避免过拟合的正则化手段,而Momentum通过对历史梯度的moving average来避免陷入局部最优。
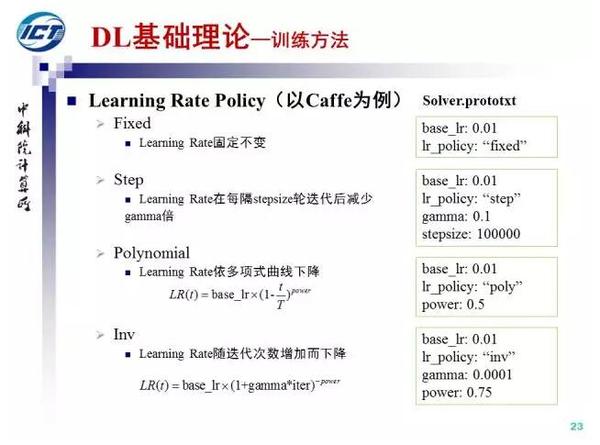 Learning rate的控制是网络收敛的关键,Caffe中支持四种策略,其中使用较多的是step和polynomial。
Learning rate的控制是网络收敛的关键,Caffe中支持四种策略,其中使用较多的是step和polynomial。
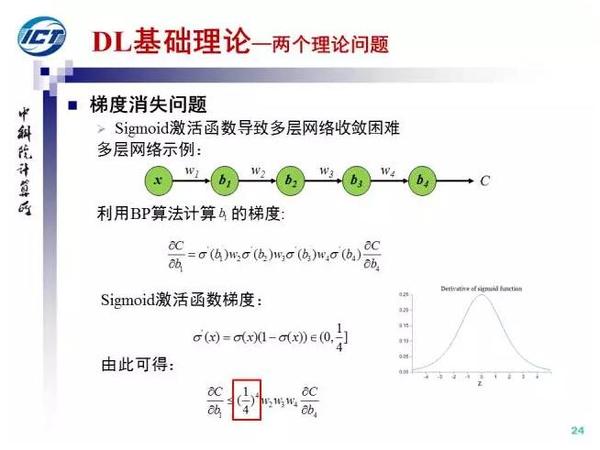 下面我介绍网络训练中的两个理论问题。首先是梯度消失,梯度消失的主要原因是sigmoid激活函数“糟糕”的解析性质,一阶梯度的取值范围是[0,1/4],梯度向下传导一次最少会减小1/4,随着深度的增加,梯度传导的过程中不断减小从而引发所谓的“梯度消失”问题。
下面我介绍网络训练中的两个理论问题。首先是梯度消失,梯度消失的主要原因是sigmoid激活函数“糟糕”的解析性质,一阶梯度的取值范围是[0,1/4],梯度向下传导一次最少会减小1/4,随着深度的增加,梯度传导的过程中不断减小从而引发所谓的“梯度消失”问题。
 为了解决梯度消失问题,学术界提出了多种策略,例如,LSTM中的选择性记忆和遗忘机制,Hinton等提出的无监督pre-train方法,新的激活函数ReLU, 辅助损失函数和Batch Normalization.
为了解决梯度消失问题,学术界提出了多种策略,例如,LSTM中的选择性记忆和遗忘机制,Hinton等提出的无监督pre-train方法,新的激活函数ReLU, 辅助损失函数和Batch Normalization.
 为了解决这个问题,Bengio等人提出了Xavier初始化策略,其基本思想是保持网络的尺度不变。
为了解决这个问题,Bengio等人提出了Xavier初始化策略,其基本思想是保持网络的尺度不变。
下面我们介绍CNN的结构演化。
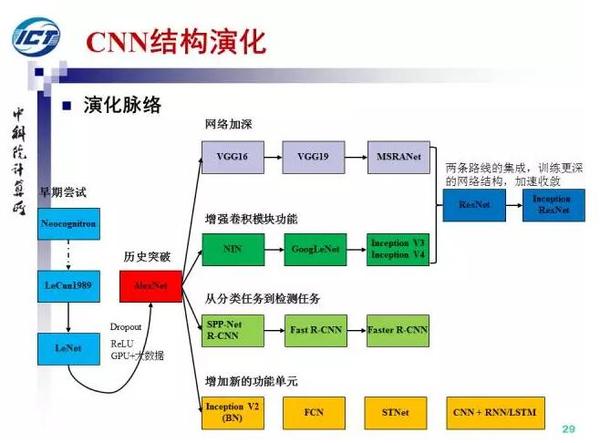 历史奔流向前,往事并不如烟。上图所示是我总结的CNN结构演化的历史,起点是神经认知机模型,已经出现了卷积结构,但是第一个CNN模型诞生于1989年,1998年诞生了LeNet。随着ReLU和dropout的提出,以及GPU和大数据带来的历史机遇,CNN在12年迎来了历史突破。12年之后,CNN的演化路径可以总结为四条:1)更深的网络,2)增强卷积模的功能以及上诉两种思路的融合,3)从分类到检测,4)增加新的功能模块。
历史奔流向前,往事并不如烟。上图所示是我总结的CNN结构演化的历史,起点是神经认知机模型,已经出现了卷积结构,但是第一个CNN模型诞生于1989年,1998年诞生了LeNet。随着ReLU和dropout的提出,以及GPU和大数据带来的历史机遇,CNN在12年迎来了历史突破。12年之后,CNN的演化路径可以总结为四条:1)更深的网络,2)增强卷积模的功能以及上诉两种思路的融合,3)从分类到检测,4)增加新的功能模块。
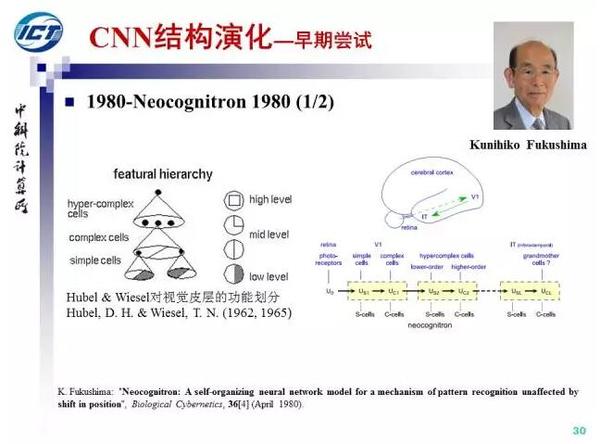 首先,我们介绍CNN的早期探索,1962年,Hubel和Wiesel提出了视觉皮层的功能模型,从简单细胞到复杂细胞再到超复杂细胞。受此启发,1980年,神经认知及提出,简单细胞被实现为卷积,复杂细胞被实现为pooling。
首先,我们介绍CNN的早期探索,1962年,Hubel和Wiesel提出了视觉皮层的功能模型,从简单细胞到复杂细胞再到超复杂细胞。受此启发,1980年,神经认知及提出,简单细胞被实现为卷积,复杂细胞被实现为pooling。
 神经认知机采用自组织的方式进行无监督的卷积核训练,因此并不是CNN(通过BP端到端训练)。
神经认知机采用自组织的方式进行无监督的卷积核训练,因此并不是CNN(通过BP端到端训练)。
 第一个CNN模型诞生于1989年,发明人LeCun。需要指出的是,从诞生的第一天起,CNN自带deep属性。
第一个CNN模型诞生于1989年,发明人LeCun。需要指出的是,从诞生的第一天起,CNN自带deep属性。
 LeCun同时研究了四个问题,这也是文章中留下的四枚彩蛋,其中问题3)和Xavier初始化之间有神秘的联系。
LeCun同时研究了四个问题,这也是文章中留下的四枚彩蛋,其中问题3)和Xavier初始化之间有神秘的联系。
 1998年,LeCun提出LeNet,并成功应用于美国手写数字识别。但很快,CNN的锋芒被SVM和手工设计的局部特征盖过。
1998年,LeCun提出LeNet,并成功应用于美国手写数字识别。但很快,CNN的锋芒被SVM和手工设计的局部特征盖过。
 历史的转折在2012年到来,AlexNet, 在当年的ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点。AlexNet的成功既得益研究者的自我奋斗:Relu和Dropout的提出, 也是大历史进程的结果:大数据训练和GPU并行计算。
历史的转折在2012年到来,AlexNet, 在当年的ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点。AlexNet的成功既得益研究者的自我奋斗:Relu和Dropout的提出, 也是大历史进程的结果:大数据训练和GPU并行计算。
2012年之后,CNN朝着不同方向演化。
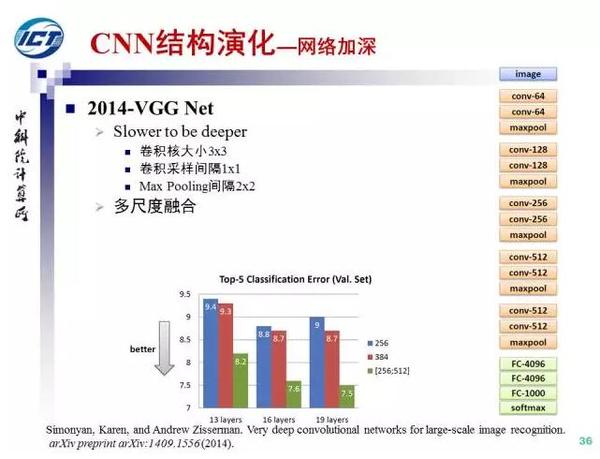
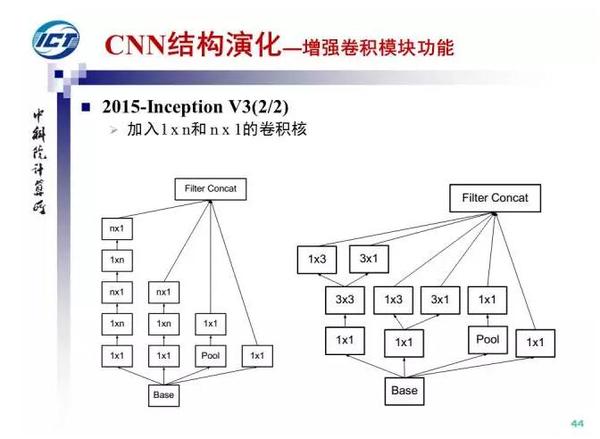
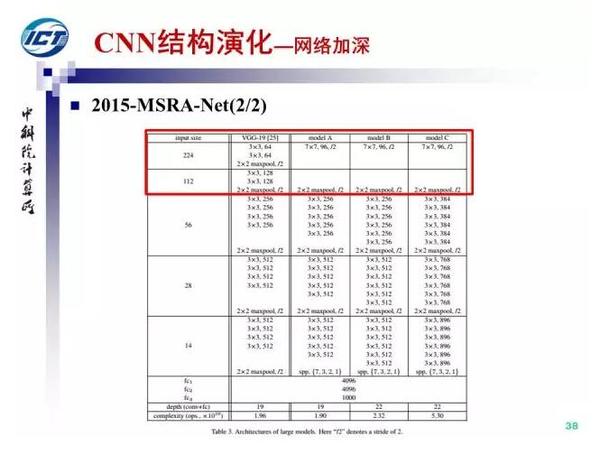 第二条演化路径,增强卷积模块的功能。
第二条演化路径,增强卷积模块的功能。
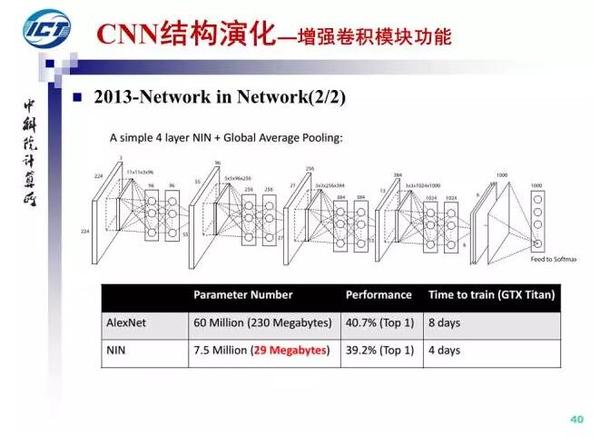
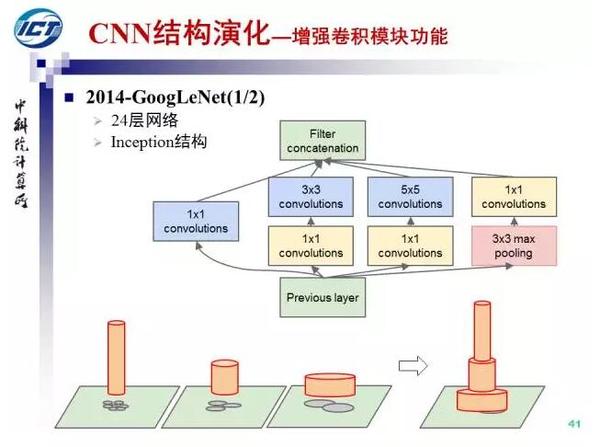
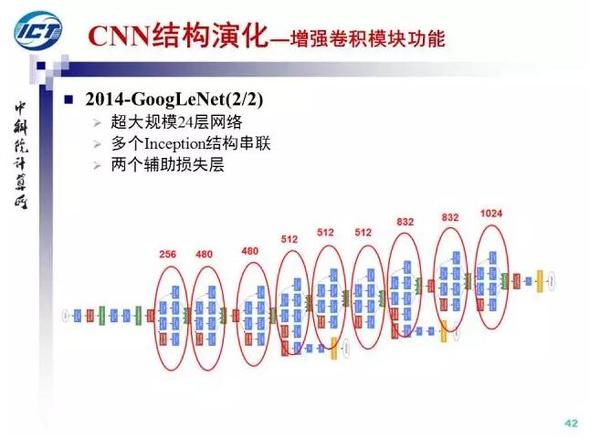
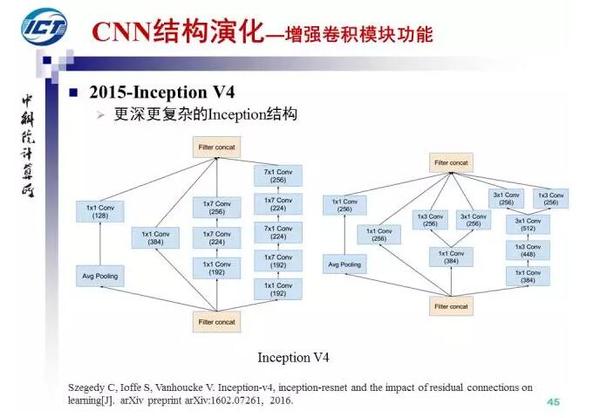
在NIN的基础上,Google于2014年提出了GoogLeNet(Inception V1),并随后改进出Inception V3和V4。
 Residual Net可以看作是前两条演化路径的集成。何凯明等人发现,单纯增加深度会导致网络退化,例如CIFAR-10数据集,网络从20层到56层性能反而会下降。为此ResNet中引入了一个shortcut结构,将输入跳层传递与卷积的结果相加。ReNet可以训练深达152层的网络,是15年ILSVRC不依赖外部数据的物体检测与物体识别竞赛的双料冠军。
Residual Net可以看作是前两条演化路径的集成。何凯明等人发现,单纯增加深度会导致网络退化,例如CIFAR-10数据集,网络从20层到56层性能反而会下降。为此ResNet中引入了一个shortcut结构,将输入跳层传递与卷积的结果相加。ReNet可以训练深达152层的网络,是15年ILSVRC不依赖外部数据的物体检测与物体识别竞赛的双料冠军。

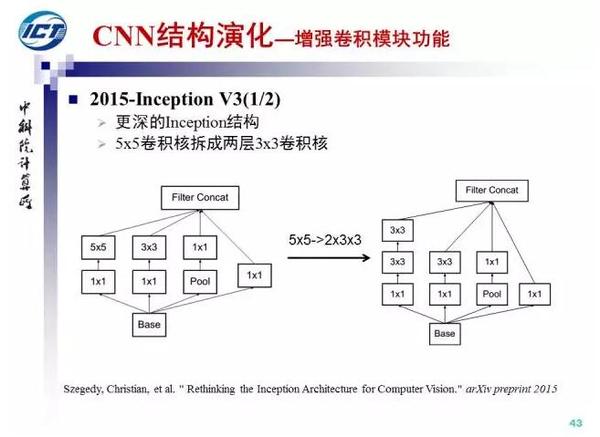
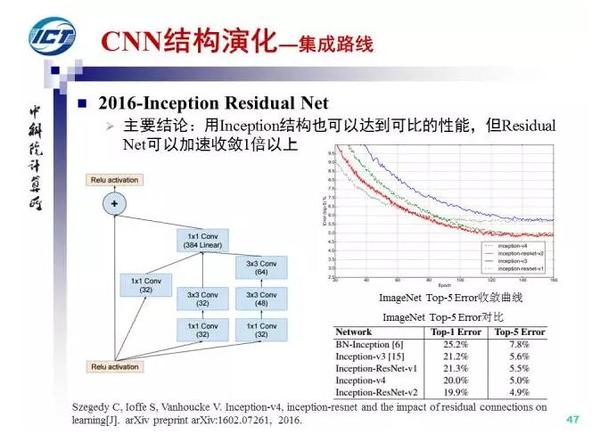 进一步的,Google将Inception结构与Residual Net结合,提出了Inception-Residual Net结构,实验表明,虽然采用Inception V4结构能够得到与ResNet可比的性能,但是残差结构能够加速收敛1倍以上。
进一步的,Google将Inception结构与Residual Net结合,提出了Inception-Residual Net结构,实验表明,虽然采用Inception V4结构能够得到与ResNet可比的性能,但是残差结构能够加速收敛1倍以上。
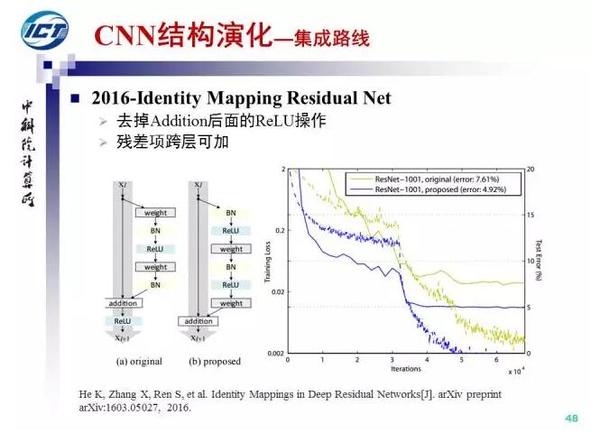
第三条演化路径:从物体识别到物体检测。

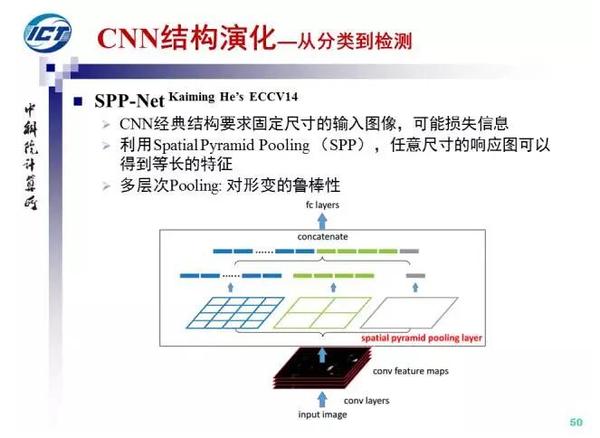 R-CNN的缺点是速度慢,Fast R-CNN是R-CNN和SPP Pooling的融合,这样每张图像只需要通过卷积网络一次同时支持端到端训练而不需要保存中间结果。
R-CNN的缺点是速度慢,Fast R-CNN是R-CNN和SPP Pooling的融合,这样每张图像只需要通过卷积网络一次同时支持端到端训练而不需要保存中间结果。

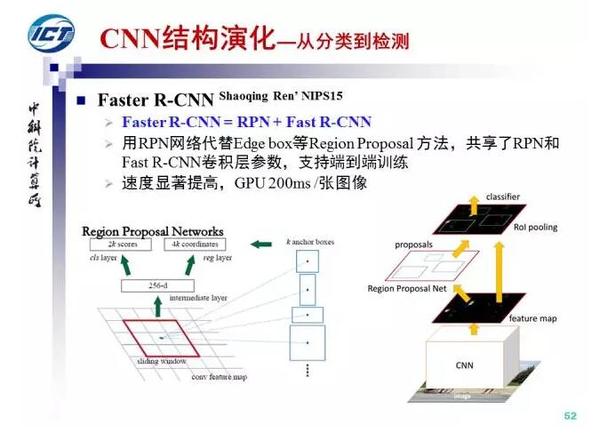
Faster R-CNN支持多类物体的同时检测而只需要一个网络,目前基于Faster R-CNN的行人与车辆检测技术是汽车高级辅助驾驶系统的关键技术之一。
第四条演化路径:增加新的功能模块。
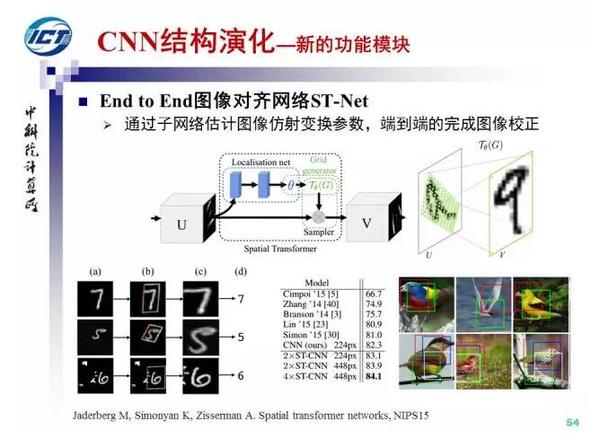
本节介绍三个工作:反卷积层、ST-Net和CNN与RNN/LSTM的混合架构。


标签:
原文地址:http://www.cnblogs.com/laiqun/p/5753179.html