标签:
1、RAC的架构
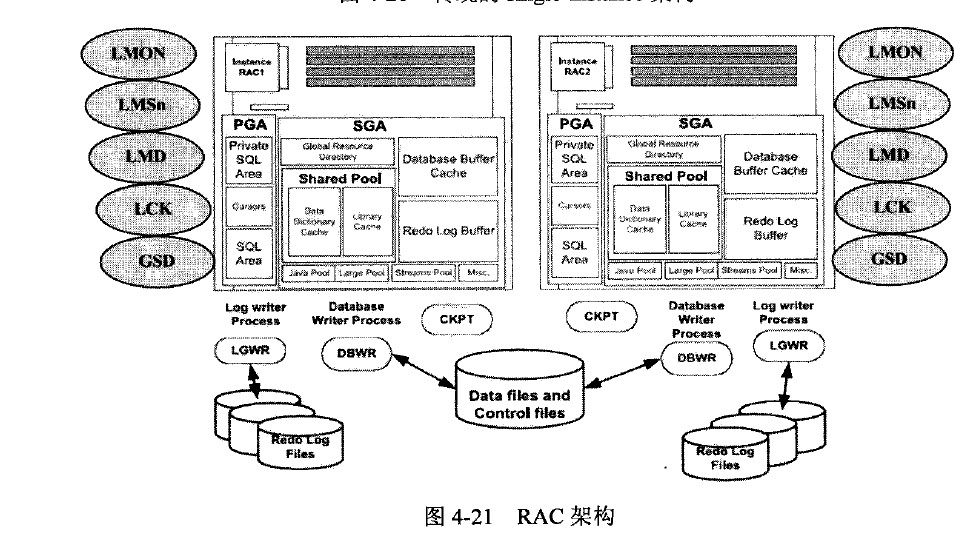
2、由单实例变RAC的变化
1、SGA的变化:
和传统的单实例相比,RAC 实例中SGA最显著的变化时多了一个GRD(Global resource directory)部分。
2、后台进程的变化:
1) LMSn进程:这个进程是cache fusion 的主要进程,负责数据块在实例间的传递,对应的服务叫做GCS(global cache service ),这个进程的名称来源于Lock Manager Service。从oracle9开始,oracle对这个服务重新命名成global cache service ,但是进程名字却没有调整。此进程的数量通过一个参数:GCS_SERVER_PROCESSES来控制,缺省值是2,取值范围是0-9。
2)LMD进程:这个进程负责的是global enqueue service (GES)具体来说,这个进程负责在多个实例之间秀条对数据块的访问顺序,保证数据的一致性访问。他和前面的LMSn进程的GCS服务还有GRD共同构成了RAC核心功能cache fusion。
3.LMD: Global Enqueue Service Daemon
oracle官方文档的描述
Global Enqueue Service Daemon (LMD)
The resource agent process that manages requests for resources to control access to blocks. The LMD process also handles deadlock detection and remote resource requests. Remote resource requests are requests originating from another instance.
LMD进程主要管理对全局队列和资源的访问,并更新相应队列的状态,处理来自于其他实例
的资源请求。每一个全局队列的当前状态存储在相应的实例共享内存中,该状态表明该实例
具有相应的权利使用该资源。一个实例(master)的共享内存中存在一个特殊的队列,该队
列纪录来自其他远程实例的资源请求,当远程实例的LMD进程发出一个资源请求时,该请求
指向master实例的LMD,当master实例的LMD进程受到该请求后,在共享内存中的特殊队列
中监测该资源是否无效,如果有效则LMD进程更新该资源对列的状态,并通知请求资源的
LMD进程该资源队列可以使用了,如果资源队列正在被其他实例使用或者当前无效,则
LMD进程通知正在使用中的实例的LMD进程应该释放该资源,等资源释放变得有效时,
MASTER实例的LMD进程更新该资源队列的状态并通知请求资源实例的LMD进程该资源
队列可以使用了。另外LMD进程也负责队列的死锁问题。。。
3)LCK进程:这个进程负责non-cache-fusion 资源的同步访问,每个实例有一个LCK进程。
4)LMON进程(lock monitor Prosesses):各个实例的LMON进程会进行定期通信,以检查集群中各节点的健康状态,当某个节点出现故障时,负责进群重构、GRD恢复等操作,它提供的服务叫做Cluster Group Services(CGS)。
前面的章节已经介绍了集群环境中脑裂的危害和解决办法。但是,在关键应用中只靠集群软件的健康监测是不够的。比如某个节点的Instance异常挂起,导致其不能对外提供服务,如果单从network、os、clusterware 几个层面看,可能监测不到这种异常。因此,脱离了应用程序的集群状态监测是没有意义的,数据库必须有自我监控机制。
oracle RAC的LMON进程,被赋予了自检功能,这个功能就是LMON提供 的CGS服务,总的来说,这个服务有以下几个要点。
*** LMON提供了节点监控(node Montior)功能,这个功能是用来记录应用层各个节点的健康状态,节点的健康状态是通过一个保存在GRD中的位图(bitmap)来记录的。每个节点一位,0代表节点关闭,1代表节点正常运行。各个节点间的lmon会相互通信,确认这个位图的一致性。
***节点上的LMON进程间会定期进行通信,这个通信可以在CM层完成,也可以不通过CM层,直接通过网络层完成。
***LMON可以和下层的clusterware合作也可以单独工作。当LMON检测到实例级别的脑裂时,LMON会先通知下层的clusterware,期待借助于clusterware解决脑裂问题。但是rac并不假设clusterware肯定能解决问题。因此,LMON进程不会无尽等待clusterware层的处理结果,如果发生等待超时,LMON进程会自动触发IMR(instance membership recovery) 也叫 instance membership reconfiguration 。 LMON进程提供的IMR功能可以看做是oracle在数据库层提供的脑裂。io隔离机制。LMON主要也是借助两种心跳机制来完成健康监测。分别是如下两种:
节点间的网络心跳(network heartbeat):可以想象成节点间定时发送ping包监测节点的状态;如果能够在规定时间内收到响应。就认为对方状态正常。
通过控制文件的磁盘心跳(controlfile heartbeat):每个节点的ckpt进程每隔3秒钟更新一次控制文件的一个数据块,这个数据块叫做checkpoint progress record;控制文件是共享的,因此实例间可以相互检查对方是否及时更新以判断状态。
5)DIAG进程:控制实例的健康状态,并在实例出现运行错误时收集诊断数据记录到alert.log中。。
6)GSD进程:这个进程负责从客户端工具(如,srvctl)接受用户命令,为用户提供管理接口。
3、文件
1)spfile:需要被所有节点访问,需要放在共享存储上。
2)redo thread:RAC环境下有多个实例,每个实例都需要自己的一套redo log文件来记录日志,这套redo log就叫做redo thread。其实单实例下也是redo thread,只是thread这个词很少被提及,每个实例一套redo thread的设计也是为了避免资源竞争造成性能瓶颈。redo thread有两种,一中是private的,创建语法是“alter database add logfile ... thread n ”另一种是public的,创建语法是“later database add logfile”没有thread 关键字。RAC中每个实例要设置thread参数,该参数默认值是0.如果设置了该参数,则实例启动时,会使用该thread的private redo thread;如果没有设置该参数,则使用缺省值0,实例启动后会使用public redo thread,并且该实例会用独占的方式使用 redo thread。
因为RAC中每个实例都需要一个redo thread 。因此原来单实例中对redo文件的要求也同样适用于rac中对每个实例的要求。这些要求包括:每个redolog thread至少要有两个redo log组;每个组成员大象相等,每组至少有两个以上成员;这些成员应该放在不同的磁盘上,以避免单点失败。
还需要注意的是,在rac环境下,redo log 组是在整个数据库级别进行编号的,比如实例1有1、2、3、个日志组,那么实例2的日志组就应该从4开始编号,不能在使用1、2、3这三个编号。
在RAC环境下,所有实例的联机日志必须放在共享存储上,这是因为,如果某个节点异常关闭,剩下的节点就要进行crash recovery,执行crash recovery的这个节点必须能够访问到故障节点的联机日志,只有吧联机日志放到共享存储上才能满足这个要求。
3)undo tablespace
和redo log 一样,在rac环境下,每个实例都需要有一个单独的回滚表空间。这一点是通过参数sid.undo_tablespace来配置的。
4)SCN
在RAC环境下,每个节点都有自己的scn发生器,每个节点都会修改数据库。必须有某种机制保证这些scn在时间排序上的精确。如果仅靠计算机的系统时钟肯定不够的,必须引入额外的算法。
在rac中,由GCS负责全局维护scn的产生,默认用的是lamport SCN生成算法,该算法的大致原理就是,在所有节点间通信内容中都携带SCN,每个节点把接收到的scn和本机scn对比,如果本机的scn小,则调整本机的scn和接收到的一致。如果节点间通信不多,还会主动定期相互通报。因此即使节点处于IDLE状态,还是会有一些redo log产生。还有一种广播算法,这个方法是在每个commit操作之后,节点要向其他节点广播scn。虽然这种方式会对系统造成一定的负载,但是确保每个节点在commit之后,都能立即看到scn号。
这两种算法各有优缺点,lamport虽然负载小,但是节点间会有延迟。广播虽然有负载,但是没有延迟。
4、cache fusion,GCS,GES关系
Cache Fusion(内存融合)是通过高速的 Private Interconnect t,在实例间进行数据块传递,它是 RAC 最核心的 工作机制,它把所有实例SGA 虚拟成一个 大的 SGA。每当不同的实例请求相数据块时,这个数据块就通过 Private Interconnect 在实例间进行传递。
整个 Cache Fusion 有两个服务组成: GCS 和 GES 。 GCS负责数据库在实例间的传递, GES 负责锁管理。
5、Clusterware
在单机环境下,Oracle 是运行在 OS Kernel 之上的。 OS Kernel 负责管理硬件设备,并提供硬访问接口。 Oracle不会直接操作硬件,而是有 OS Kernel 代替它来完成对硬件的调用请求。
在集群环境下, 存储设备是共享的。 OS Kernel 的设计都是针对单机, 只能控制单机上多个进程间的访问。 如果还依赖 OS Kernel 的服务,就无法保证多个主机间的协调工作。 这时就需要引入额外的控制机,在 RAC中,这个机制就是位于 Oracle和 OS Kernel 之间的 Clusterware,它会在 OS Kernel 之前截获请求,然后和其他结点上的 Clusterware 协商,最终完成上层的请求。
在 Oracle 10G 之前, RAC 所需要的集群件依赖与硬厂商,比如 SUN,HP,Veritas. 从 Oracle 10.1 版本中, Oracle 推出了自己的集群产品 . Cluster Ready Service(CRS), 从此 RAC 不在依赖与任何厂商的集群软件。 在 Oracle 10.2版本中,这个产品改名为: Oracle Clusterware
所以我们可看出, 在整个 RAC 集群中,实际上有 2个集群环境的存在, 一个是由 Clusterware 软件组成的集群,另一个是由 Database 组成的集群。
标签:
原文地址:http://www.cnblogs.com/andy6/p/5759303.html