标签:
简介
自2007年发布以来,scikit-learn已经成为Python重要的机器学习库了。scikit-learn简称sklearn,支持包括分类、回归、降维和聚类四大机器学习算法。还包含了特征提取、数据处理和模型评估三大模块。
sklearn是Scipy的扩展,建立在NumPy和matplotlib库的基础上。利用这几大模块的优势,可以大大提高机器学习的效率。
sklearn拥有着完善的文档,上手容易,具有着丰富的API,在学术界颇受欢迎。sklearn已经封装了大量的机器学习算法,包括LIBSVM和LIBINEAR。同时sklearn内置了大量数据集,节省了获取和整理数据集的时间。
机器学习基础
定义:针对经验E和一系列的任务T和一定表现的衡量P,如果随着经验E的积累,针对定义好的任务T可以提高表现P,就说明机器具有学习能力。
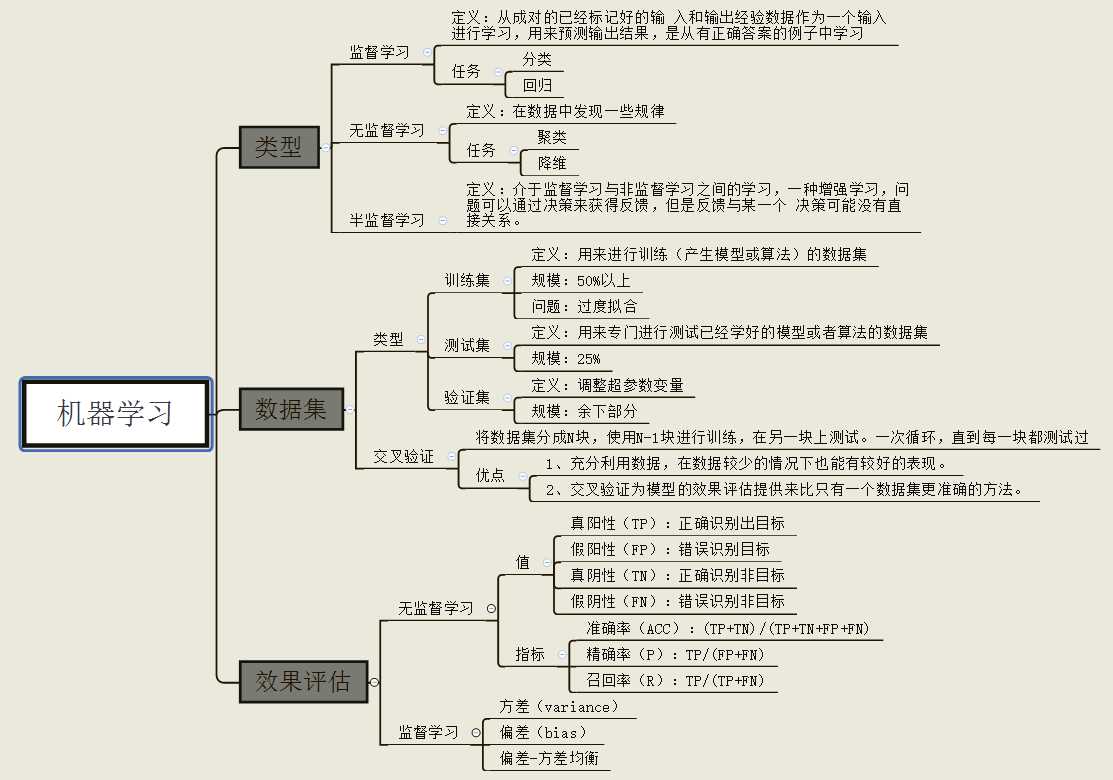
sklearn安装
sklearn目前的版本是0.17.1,可以使用pip安装。在安装时需要进行包依赖检查,具体有以下几个要求:
如果满足上述条件,就能使用pip进行安装了:
1 pip install -U scikit-learn
当然,使用pip安装会比较麻烦,推荐使用Anaconda科学计算环境,里面已经内置了NumPy、SciPy、sklearn等模块,直接可用。或者使用conda进行包管理。conda安装与pip类似:
1 conda install scikit-learn
安装完sklearn以后,可以检查以下版本:
1 >>> import sklearn 2 >>> sklearn.__version__ 3 ‘0.17.1‘
标签:
原文地址:http://www.cnblogs.com/magle/p/5638409.html