标签:
Hive是一个基于Hadoop的数据仓库,最初由Facebook提供,使用HQL作为查询接口、HDFS作为存储底层、mapReduce作为执行层,设计目的是让SQL技能良好,但Java技能较弱的分析师可以查询海量数据,2008年facebook把Hive项目贡献给Apache。Hive提供了比较完整的SQL功能(本质是将SQL转换为MapReduce),自身最大的缺点就是执行速度慢。Hive有自身的元数据结构描述,可以使用MySql\ProstgreSql\oracle 等关系型数据库来进行存储,但请注意Hive中的所有数据都存储在HDFS中。虽然 hive 可能存在这样那样的问题,但它作为后续研究 sparkSql 的基础,值得重点研究。
解释一下经常遇到的 hiveServer1、hiveServer2 ? 早期版本的 hiveServer(即 hiveServer1)因使用Thrift接口的限制,不能处理多于一个客户端的并发请求,在hive-0.11.0版本中重写了hiveServer代码(即 hiveServer2),支持了多客户端的并发和认证,并且为开放API客户端如JDBC、ODBC提供了更好的支持。
目录:
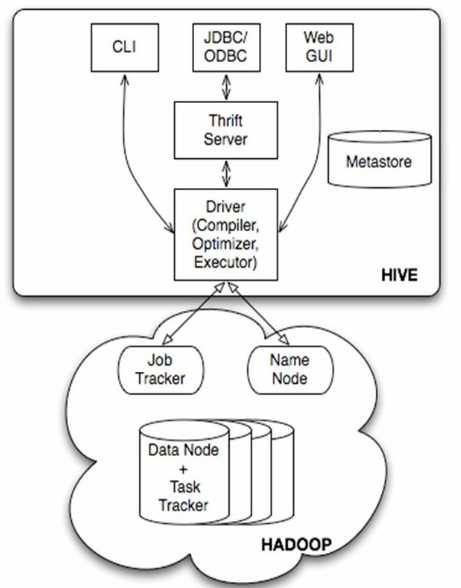
hive架构:
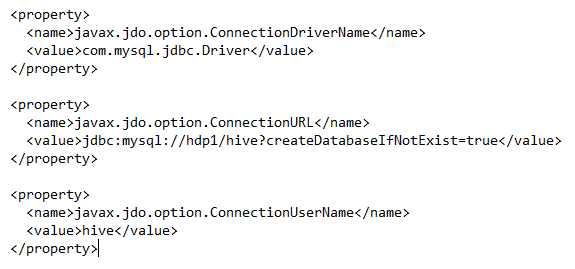
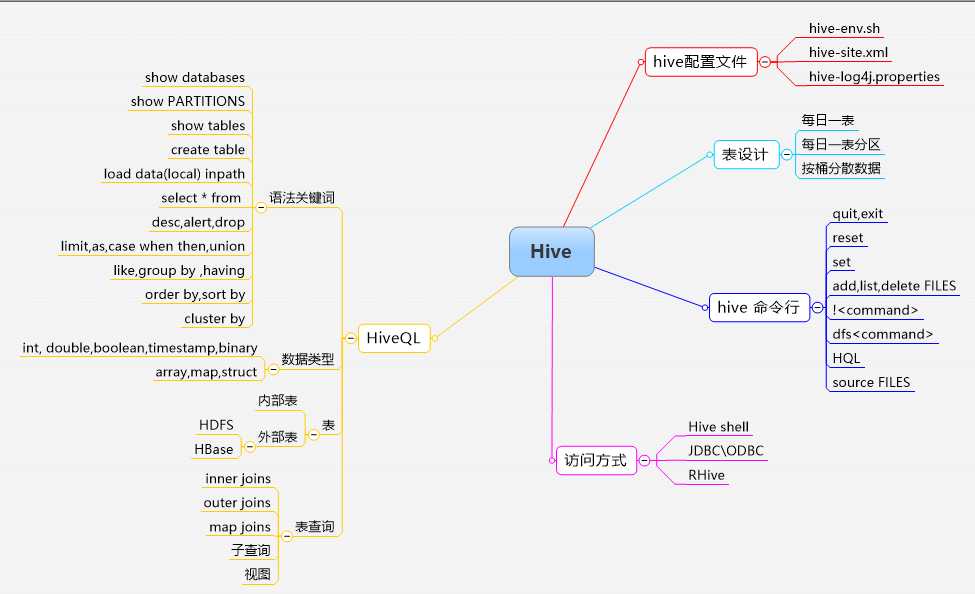
知识体系:
标签:
原文地址:http://www.cnblogs.com/tgzhu/p/5759610.html