标签:
转发请注明本文链接
准备工作:
VMware-workstation (网络统一设置为桥接)
Xshell或者putty (方便在Windows下进行操作,复制粘贴命令方便,更推荐用第一个,以后不需要输入IP地址和帐号密码了)
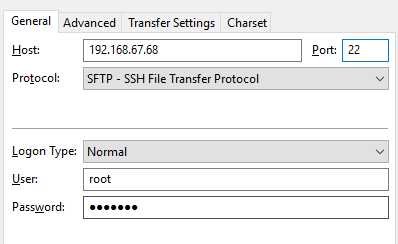
FileZilla (传输文件,端口22,使用SFTP协议)
环境为
Centos6.5 X86 minimal
Hadoop1.2.1
jdk-8u73-linux-i586
先配置伪分布式,把伪分布式跑起来再升级为完全分布模式
注:192.168.67.57 是Master节点主机。
以下操作在root用户下进行
一、在linux系统创建目录
mkdir /opt
把hadoop-1.2.1-bin.tar 、jdk-8u73-linux-i586.rpm上传到/opt目录下
在/opt目录下安装hadoop会减少不必要麻烦
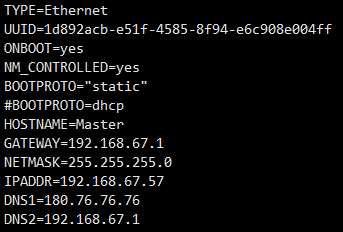
二、设置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
三、关闭防火墙
vi /etc/selinux/config 设置 SELINUX=disabled
此外,输入以下命令
service iptables status --查看防火墙状态
service iptables stop --关闭防火墙
service ip6tables stop --关闭防火墙
chkconfig ip6tables off --设置防火墙开机自关闭
chkconfig iptables off --设置防火墙开机自关闭
chkconfig iptables --list --查看防火墙服务状态列表
chkconfig ip6tables --list --查看防火墙服务状态列表
#iptables 和 ip6tables一样,都是linux防火墙软件,不同的是ip6tables采用的TCP/ip协议为IP6.
四、修改hosts,该主机设置为Master
vi /etc/hosts 添加
192.168.67.57 Master
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=Master
五、 增加用户组,用户
groupadd hadoop
useradd –g hadoop hadoop
passwd hadoop
六、安装java,并且配置java环境
我使用的是rpm安装包,简化安装
rpm -ivh jdk-8u73-linux-i586.rpm
安装目录为 /usr/java/jdk1.8.0_73
将该安装目录复制出来,方便后面配置环境
vi /etc/profile
在最下面加入
export JAVA_HOME=/usr/java/jdk1.8.0_73
export JRE_HOME=/usr/java/jdk1.8.0_73/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
保存退出,执行以下命令使配置生效!
[root@localhost ~]#chmod +x /etc/profile ;增加执行权限
[root@localhost ~]#source /etc/profile;使配置生效!
以上操作都在root用户下完成。
七、设置SSH免密码登陆,切换到hadoop用户
先检查一下是否有ssh和rsync工具
rpm -qa |grep ssh
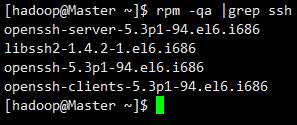
rpm -qa |grep rsync(可有可无,有更好)
没有ssh和rsync工具的话使用下面命令进行安装:
yum install ssh #安装SSH
yum install rsync #(rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
service sshd restart #启动SSH服务
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限,否则无法免密码登陆
chmod 700 ~/.ssh #修改目录权限
八、安装hadoop
cd /opt #进入opt目录
tar -zxf /opt/hadoop-1.2.1-bin.tar.gz -C /opt #解压
mv hadoop-1.2.1 hadoop #重命名
chown -R hadoop:hadoop hadoop #更改所属用户,十分重要
九、尝试单机模式
hadoop默认的模式就是非分布式模式,只需配置java环境,无需hadoop配置就可以运行
cd /opt/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output ‘dfs[a-z.]+‘
cat ./output/*
hadoop不能覆盖结果文件,所以先删除 ./output ,下次运行上面的例子就不会报错。
rm -r ./output
十、配置hadoop
(1)vi /etc/profile
添加下面内容
# Hadoop Environment Variables
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
————————————————————————————————
下面进入hadoop的配置文件夹
cd /opt/hadoop/conf/
(2)配置 hadoop-env.sh
vi hadoop-env.sh 在最下面添加
export JAVA_HOME=/usr/java/jdk1.8.0_73
export HADOOP_HOME_WARN_SUPPRESS=1 #我的环境在格式化namenode时出现过Warning: $HADOOP_HOME is deprecated.,这句根据情况
(3)配置 core-site.xml
vi core-site.xml
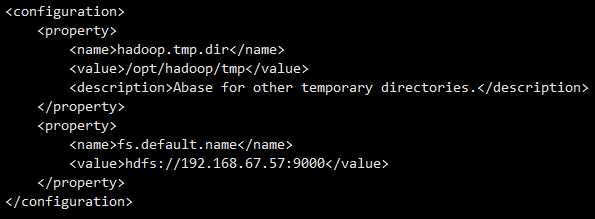
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.67.57:9000</value>
</property>
</configuration>
(4)配置hdfs-site.xml
vi hdfs-site.xml
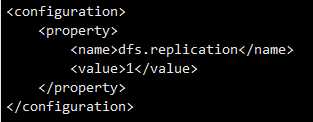
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(5)配置mapred-site.xml
vi mapred-site.xml
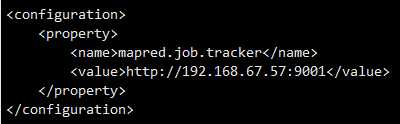
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.67.57:9001</value>
</property>
</configuration>
(6)配置masters 和 slaves文件(这部可以省略)
全部清空,再添加Master的ip地址
(7)格式化
cd /opt/hadoop
hadoop namenode -format
start-all.sh
(8)查看运行状态
jps
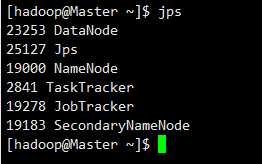
这样就启动成功了
十一、执行示例程序
hadoop基本操作命令
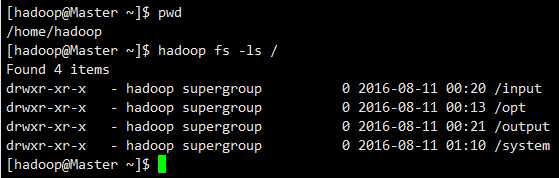
(1)列出文件(hdfs是系统中的系统)
hadoop fs -ls /
(2)关闭hadoop
stop-all.sh
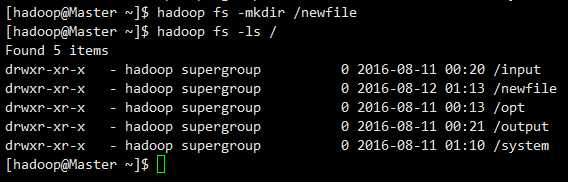
(3)新建文件夹
hadoop fs -mkdir /newfile
(4)添加文件到hdfs
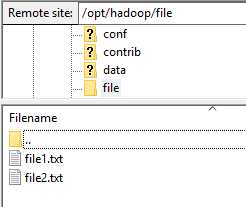
上图是在FileZilla查看文件,我已经在file1.txt和file2.txt输入了两句英文句子。
注意,file文件夹和里面的文件都要是hadoop用户组,否则会失败
hadoop fs -put /opt/hadoop/file/* /newfile

(5)执行示例程序wordcount
先看下程序包在哪里
ll /opt/hadoop | grep jar
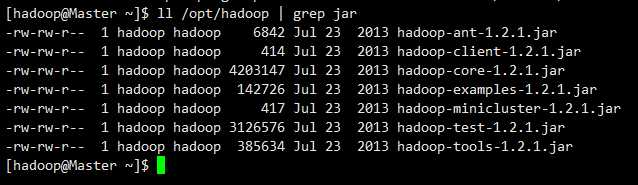
hadoop jar /opt/hadoop/hadoop-examples-1.2.1.jar wordcount /newfile /output/file
/newfile 为输入文件
/output/file 为输出文件
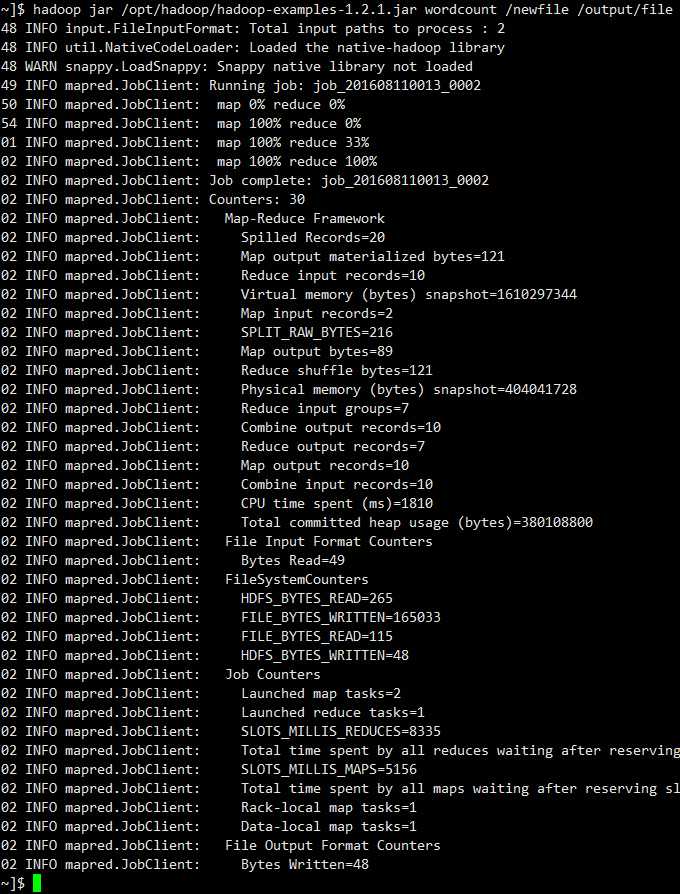
(6)查看执行结果
hadoop fs -cat /output/file/part-r-00000
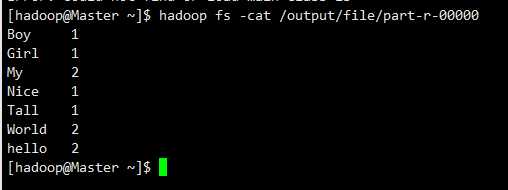
(7)其他常用命令
下载文件
hadoop fs -get /output/file/part-r-00000 /home/hadoop/

(8)删除文件
hadoop fs -rmr /output/file
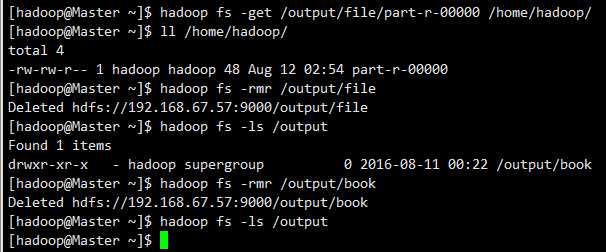
问题总结
在使用这个
环境为
Centos6.5 X86 minimal
Hadoop1.2.1
jdk-8u73-linux-i586
配置之前,我使用的配置是
Centos6.5 X64 minimal
hadoop2.6.0
jdk-8u101-linux-x64
但是遇到了
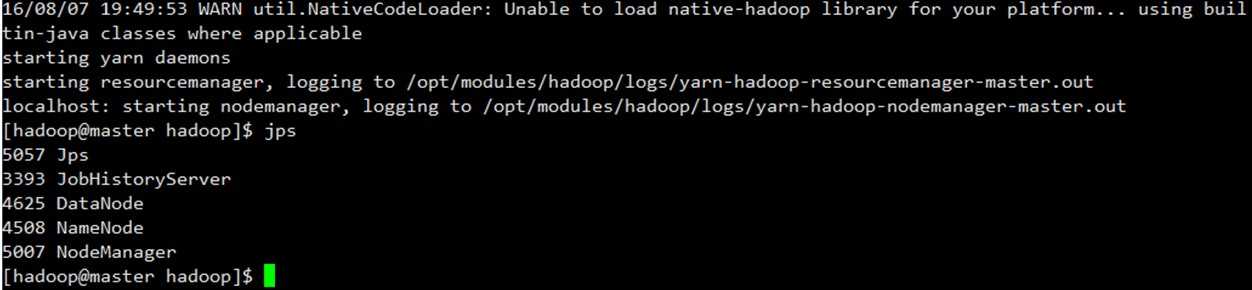
“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable”

虽然NameNode,DataNode等都启动了,但是在hdfs下新建文件夹失败
hadoop fs –mkdir input
无法对hdfs进行任何操作

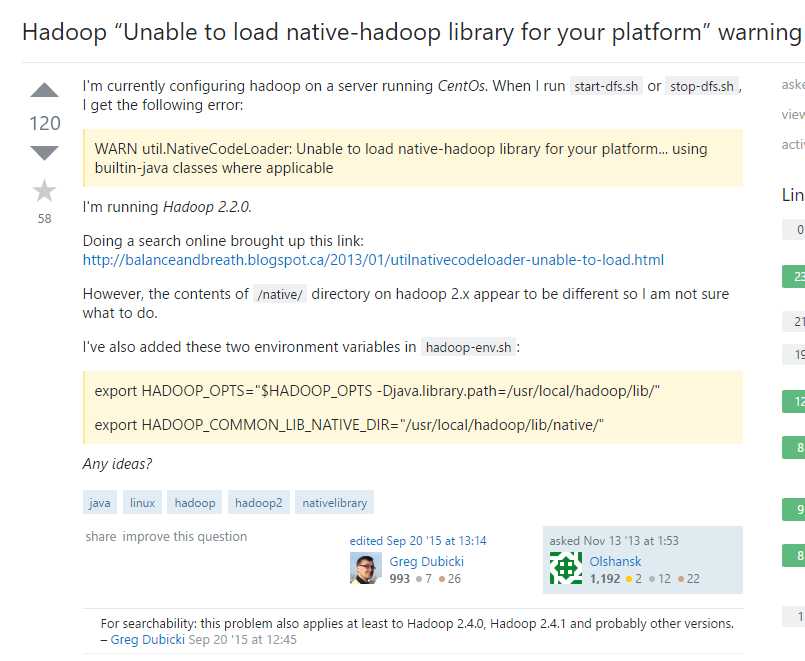
后来换成
Centos6.5 X86 minimal
hadoop2.6.0
jdk-8u101-linux-x64

http://f.dataguru.cn/thread-542396-1-1.html
再后来,把hadoop降级
Centos6.5 X86 minimal
Hadoop1.2.1
jdk-8u73-linux-i586
启动时候遇到Warning: $HADOOP_HOME is deprecated.,加入一条命令搞掂,前面有提到。
————————————————————————————————————————————
下面介绍如何将其升级为完全分布式
一、
在刚才成功运行伪分布式的情况下,关机,克隆出另外的三台虚拟机。centos6.5静态ip克隆出来的话是不能上网的,设置参考!!!
修改好每个虚拟机的ip,设置为静态ip,接着修改hostname,修改hosts,至于/etc/profile则不用再配置了。
需要修改的有:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network
vi /etc/hosts
二、ssh配置
因为克隆出来的,每台虚拟机的ssh文件都一致
只需要在hadoop用户下,Master与Slave都互相ssh一下,就可以了。
三、配置hadoop
需要修改的只有masters 和 slaves
(1)在Master节点下
vi /opt/hadoop/conf/masters
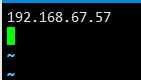
192.168.67.57是我Master的ip地址
(2)在Master节点下
vi /opt/hadoop/conf/slaves
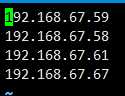
为什么是四个ip呢,因为我后来在集群运行时动态地加入了一个Slave。有多少个Slave就写多少个IP就行了。
(3)把slaves,masters文件发送到其他三个slaves上
scp /opt/hadoop/conf/slaves 192.168.67.58:/opt/hadoop/conf/
scp /opt/hadoop/conf/masters 192.168.67.58:/opt/hadoop/conf/
(4) 格式化
执行格式化之前,把/opt/hadoop/tmp下面的东西删掉
并且把/opt/hadoop/logs 里面的日志清空
四、动态添加slave节点
建议直接克隆虚拟机,参考伪分布式编程完全分布式时候的设置进行修改配置文件。
第一步,修改虚拟机的基本信息。
需要修改的有:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network
vi /etc/hosts
第二步,SSH,参照上文
第三步,修改Master主机上 /opt/hadoop/conf/下的masters文件和slaves文件,并发送到所有的Slaves节点
第四步,因为其他节点正在运行,并不需要再次进行格式化hdfs
只需要在新的slave节点上,启动datanode和tasktracker进程
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
通过jps可以查看到运行情况,也可以通过网页端查看新添加的节点
第四步,如果有必要,进行负载均衡
在master节点上运行start-balancer.sh进行数据负载均衡
start-balancer.sh
CentOS 6.5安装hadoop1.2.1经验(由伪分布式到完全分布式)
标签:
原文地址:http://www.cnblogs.com/wuyushen/p/5764194.html