标签:
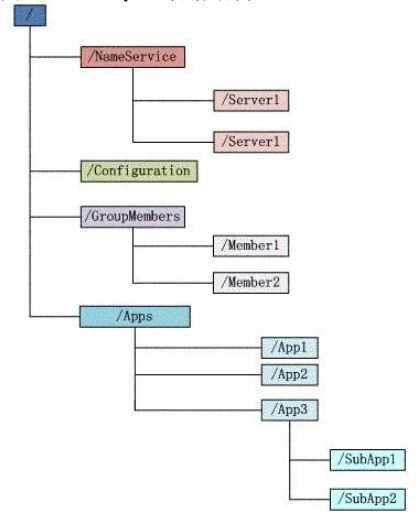
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每个ZNode都可以通过其路径唯一标识,在每个ZNode上可存储少量数据(默认是1M, 可以通过配置修改, 通常不建议在ZNode上存储大量的数据)。另外,每个ZNode上还存储了其Acl信息,这里需要注意,虽说ZNode的树形结构跟Unix文件系统很类似,但是其Acl与Unix文件系统是完全不同的,每个ZNode的Acl是独立的,子结点不会继承父结点的。
ZNode根据其本身的特性,可以分为下面两类:
Zookeeper这种数据结构有如下这些特点:
1)每个子目录项如NameService都被称作为znode,这个znode是被它所在的路径唯一标识,如Server1这个znode的标识为/NameService/Server1。
2)znode可以有子节点目录,并且每个znode可以存储数据,注意EPHEMERAL(临时的)类型的目录节点不能有子节点目录。ZNode一个Sequential的特性,如果创建的时候指定的话,该ZNode的名字后面会自动Append一个不断增加的SequenceNo。
3)znode是有版本的(version),每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据,version号自动增加。
4)znode可以是临时节点(EPHEMERAL),可以是持久节点(PERSISTENT)。如果创建的是临时节点,一旦创建这个EPHEMERALznode的客户端与服务器失去联系,这个znode也将自动删除,Zookeeper的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为session,如果znode是临时节点,这个session失效,znode也就删除了。
5)znode的目录名可以自动编号,如App1已经存在,再创建的话,将会自动命名为App2。
6)znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是Zookeeper的核心特性,Zookeeper的很多功能都是基于这个特性实现的。Watcher ZooKeeper支持一种Watch操作,Client可以在某个ZNode上设置一个Watcher,来Watch该ZNode上的变化。如果该ZNode上有相应的变化,就会触发这个Watcher,把相应的事件通知给设置Watcher的Client。需要注意的是,ZooKeeper中的Watcher是一次性的,即触发一次就会被取消,如果想继续Watch的话,需要客户端重新设置Watcher。这个跟epoll里的oneshot模式有点类似。
7)ZXID:每次对Zookeeper的状态的改变都会产生一个zxid(ZooKeeper Transaction Id),zxid是全局有序的,如果zxid1小于zxid2,则zxid1在zxid2之前发生。
8)Session: Client与ZooKeeper之间的通信,需要创建一个Session,这个Session会有一个超时时间。因为ZooKeeper集群会把Client的Session信息持久化,所以在Session没超时之前,Client与ZooKeeper Server的连接可以在各个ZooKeeper Server之间透明地移动。在实际的应用中,如果Client与Server之间的通信足够频繁,Session的维护就不需要其它额外的消息了。否则,ZooKeeper Client会每t/3 ms发一次心跳给Server,如果Client 2t/3 ms没收到来自Server的心跳回应,就会换到一个新的ZooKeeper Server上。这里t是用户配置的Session的超时时间。
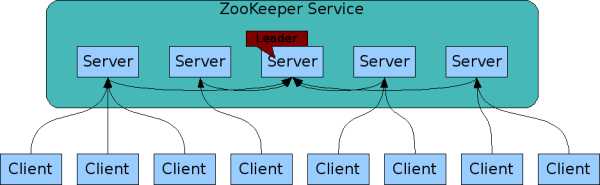
(client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。)
ACL分为两个维度,一个是属组,一个是权限,子目录/文件默认继承父目录的ACL。而在Zookeeper中,node的ACL是没有继承关系的,是独立控制的。Zookeeper的ACL,可以从三个维度来理解:一是scheme; 二是user; 三是permission,通常表示为scheme:id:permissions。
(1)scheme: scheme对应于采用哪种方案来进行权限管理,zookeeper实现了一个pluggable的ACL方案,可以通过扩展scheme,来扩展ACL的机制。zookeeper-3.4.4缺省支持下面几种scheme:
另外,zookeeper-3.4.4的代码中还提供了对sasl的支持,不过缺省是没有开启的,需要配置才能启用。
(2)id: id与scheme是紧密相关的。
(3)permission: zookeeper目前支持下面一些权限:
具体来说就是每种scheme对应于一种ACL机制,可以通过扩展scheme来扩展ACL的机制。在具体的实现中,每种scheme对应一种AuthenticationProvider。每种AuthenticationProvider实现了当前机制下authentication的检查,通过了authentication的检查,然后再进行统一的permission检查,如此便实现了ACL。所有的AuthenticationProvider都注册在ProviderRegistry中,新扩展的AuthenticationProvider可以通过配置注册到ProviderRegistry中去。下面是实施检查的具体实现:
void checkACL(ZooKeeperServer zks, List<acl> acl, int perm, List<id> ids) throws KeeperException.NoAuthException { if (skipACL) { return; } if (acl == null || acl.size() == 0) { return; } for (Id authId : ids) { if (authId.getScheme().equals("super")) { return; } } for (ACL a : acl) { Id id = a.getId(); if ((a.getPerms() & perm) != 0) { if (id.getScheme().equals("world") && id.getId().equals("anyone")) { return; } AuthenticationProvider ap = ProviderRegistry.getProvider(id .getScheme()); if (ap != null) { for (Id authId : ids) { if (authId.getScheme().equals(id.getScheme()) && ap.matches(authId.getId(), id.getId())) { return; } } } } } throw new KeeperException.NoAuthException(); } </id></acl>
可以通过下面两种方式把新扩展的AuthenticationProvider注册到ProviderRegistry:
配置文件:在zookeeper的配置文件中,加入authProvider.$n=$classname即可
JVM参数:启动Zookeeper的时候,通过-Dzookeeper.authProvider.$n=$classname的方式,把AuthenticaitonProvider传入
在上面的配置中, $n是为了区分不同的provider的一个序号,只要保证不重复即可,没有实际的意义,通常用数字1,2,3等
可以通过zookeeper client来管理ACL, zookeeper的发行包中提供了一个cli工具zkcli.sh,可以通过它来进行acl管理(使用自行百度)
在ZooKeeper集群中,读可以从任意一个ZooKeeper Server读,这一点是保证ZooKeeper比较好的读性能的关键;写的请求会先Forwarder到Leader,然后由Leader来通过ZooKeeper中的原子广播协议,将请求广播给所有的Follower,Leader收到一半以上的写成功的Ack后,就认为该写成功了,就会将该写进行持久化,并告诉客户端写成功了。
和大多数分布式系统一样,ZooKeeper也有WAL(Write-Ahead-Log),对于每一个更新操作,ZooKeeper都会先写WAL, 然后再对内存中的数据做更新,然后向Client通知更新结果。另外,ZooKeeper还会定期将内存中的目录树进行Snapshot,落地到磁盘上,这个跟HDFS中的FSImage是比较类似的。这么做的主要目的,一当然是数据的持久化,二是加快重启之后的恢复速度,如果全部通过Replay WAL的形式恢复的话,会比较慢。
对于每一个ZooKeeper客户端而言,所有的操作都是遵循FIFO顺序的,这一特性是由下面两个基本特性来保证的:一是ZooKeeper Client与Server之间的网络通信是基于TCP,TCP保证了Client/Server之间传输包的顺序;二是ZooKeeper Server执行客户端请求也是严格按照FIFO顺序的。
在ZooKeeper中,所有的更新操作都有严格的偏序关系,更新操作都是串行执行的,这一点是保证ZooKeeper功能正确性的关键。
ZooKeeper Client Library提供了丰富直观的API供用户程序使用,下面是一些常用的API:
分布式应用中,通常需要一套完备的命令机制,既能产生唯一的标识,又方便人识别和记忆。 我们知道,每个ZNode都可以由其路径唯一标识,路径本身也比较简洁直观,另外ZNode上还可以存储少量数据,这些都是实现统一的NameService的基础。
下面以在HDFS中实现NameService为例,来说明实现NameService的基本布骤:
在分布式系统中,常会遇到这样的场景: 某个Job的很多个实例在运行,它们在运行时大多数配置项是相同的,如果想要统一改某个配置,一个个实例去改,是比较低效,也是比较容易出错的方式。通过ZooKeeper可以很好的解决这样的问题,下面的基本的步骤:
在典型的Master-Slave结构的分布式系统中,Master需要作为“总管”来管理所有的Slave, 当有Slave加入,或者有Slave宕机,Master都需要感知到这个事情,然后作出对应的调整,以便不影响整个集群对外提供服务。以HBase为例,HMaster管理了所有的RegionServer,当有新的RegionServer加入的时候,HMaster需要分配一些Region到该RegionServer上去,让其提供服务;当有RegionServer宕机时,HMaster需要将该RegionServer之前服务的Region都重新分配到当前正在提供服务的其它RegionServer上,以便不影响客户端的正常访问。下面是这种场景下使用ZooKeeper的基本步骤:
我们知识,在传统的应用程序中,线程、进程的同步,都可以通过操作系统提供的机制来完成。但是在分布式系统中,多个进程之间的同步,操作系统层面就无能为力了。这时候就需要像ZooKeeper这样的分布式的协调(Coordination)服务来协助完成同步,下面是用ZooKeeper实现简单的互斥锁的步骤,这个可以和线程间同步的mutex做类比来理解:
上一节的例子中有一个问题,每次抢锁都会有大量的进程去竞争,会造成羊群效应(Herd Effect),为了解决这个问题,我们可以通过下面的步骤来改进上述过程:
这里需要补充一点,通常在分布式系统中用ZooKeeper来做Leader Election(选主)就是通过上面的机制来实现的,这里的持锁者就是当前的“主”。
读写锁(Read/Write Lock)
我们知道,读写锁跟互斥锁相比不同的地方是,它分成了读和写两种模式,多个读可以并发执行,但写和读、写都互斥,不能同时执行行。利用ZooKeeper,在上面的基础上,稍做修改也可以实现传统的读写锁的语义,下面是基本的步骤:
在分布式系统中,屏障是这样一种语义: 客户端需要等待多个进程完成各自的任务,然后才能继续往前进行下一步。下用是用ZooKeeper来实现屏障的基本步骤:
双屏障是这样一种语义: 它可以用来同步一个任务的开始和结束,当有足够多的进程进入屏障后,才开始执行任务;当所有的进程都执行完各自的任务后,屏障才撤销。下面是用ZooKeeper来实现双屏障的基本步骤:
标签:
原文地址:http://www.cnblogs.com/wade-luffy/p/5767811.html