标签:
一,Hash Index的结构
Hash Index 由buckets集合构成,Index Key 经过 Hash 函数的映射,产生Hash Value,填充到相应的bucket中,每个bucket的Hash Value不同。SQL Server 提供一个hash 函数,用于将 index key 隐射到相应的bucket中。该hash函数是确定性的,对于相同的index key,Hash函数产生hash value是固定的,隐射到相同的bucket上。
A hash index consists of a collection of buckets organized in an array. A hash function maps index keys to corresponding buckets in the hash index. The following figure shows three index keys that are mapped to three different buckets in the hash index.For illustration purposes the hash function name is f(x).
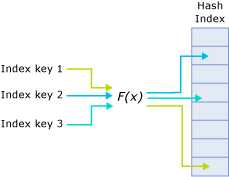
The hashing function used for hash indexes has the following characteristics:
SQL Server has one hash function that is used for all hash indexes.
The hash function is deterministic. The same index key is always mapped to the same bucket in the hash index.
Multiple index keys may be mapped to the same hash bucket.
The hash function is balanced, meaning that the distribution of index key values over hash buckets typically follows a Poisson distribution.
Poisson distribution is not an even distribution. Index key values are not evenly distributed in the hash buckets. For example, a Poisson distribution of n distinct index keys over n hash buckets results in approximately one third empty buckets, one third of the buckets containing one index key, and the other third containing two index keys. A small number of buckets will contain more than two keys.
由于不同的Index Key经过hash函数隐射之后,可能生成相同的Hash value,隐射到相同的bucket中,这就是 Hash 冲突。如果多个Index Key 隐射到相同的bucket中,那么这些Index key会组成一个链表。链表越长,查找性能越差。如果为Hash Index拥有足够数量的bucket,那么能在一定程度上减少Hash 冲突,提高 Hash Index的seek性能。
If two index keys are mapped to the same hash bucket, there is a hash collision. A large number of hash collisions can have a performance impact on read operations.
The in-memory hash index structure consists of an array of memory pointers. Each bucket maps to an offset in this array. Each bucket in the array points to the first row in that hash bucket. Each row in the bucket points to the next row, thus resulting in a chain of rows for each hash bucket, as illustrated in the following figure.
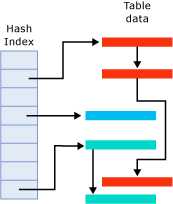
The figure has three buckets with rows. The second bucket from the top contains the three red rows. The fourth bucket contains the single blue row. The bottom bucket contains the two green rows. These could be different versions of the same row.
二,Memory Optimized Index
在SQL Server 2014中,根据Table是否驻留在内存中,将Table分为两类:memory-optimized table 和 disk-based table。创建在table的index相应的分为两类:memory-optimized index 和 disk-based index。disk-based index 是BTree 结构,有clustered 和nonclustered 两种类型。
memory-optimized index 独特的特点:
在Memory-Optimized table上创建的Index,叫做Memory-Optimized Index,共有两种类型:Nonclustered hash index 和 Nonclustered index。
1,Memory-Optimized nonclustered index的特点
2,Hash Index的特点
三,Hash Table
Hash Index实际上是使用Hash Table来存储Index key和Value的的,通过在内存中构建HashTable来实现Hash Index对memory optimized table中数据的快速访问。HashTable 主要有Hash Function ,Bucket集合和元素链表组成。Hash Table的查找优势是不需要排序,搜寻速度与数据多少无关。
引用《Linux内核中的hash与bucket》:
Hashtable是存储索引键(Key)和值(Value)配对的集合,Hashtable 对象是由包含集合中元素的哈希桶(Bucket)所组成的,而Bucket是Hashtable内元素的虚拟子群组。一个由5个buckets组成的哈希表,里面有7个元素:
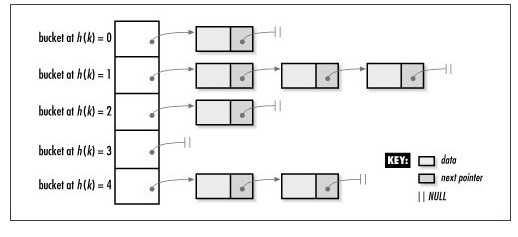
哈希函数(Hash Function)为根据索引键来返回数值哈希程序代码的算法。索引键(Key)是被存储对象的某些属性值(Value)。当对象加入至 Hashtable时,它存储在与对象哈希程序代码相符的哈希程序代码相关的Bucket中。当在Hashtable内搜寻值时,哈希程序代码会为该值产生,并且会搜寻与该哈希程序代码相关的Bucket。例如,student和teacher会放在不同的Bucket中,而dog和god会放在相同的 Bucket中。所以当索引键是唯一从Hashtable获取元素的性能时表现会较好。
bucket的英文解释:
Hash table lookup operations are often O(n/m) (where n is the number of objects in the table and m is the number of buckets), which is close to O(1), especially when the hash function has spread the hashed objects evenly through the hash table, and there are more hash buckets than objects to be stored.
四,Hash Index Key Columns
In contrast, ordered indexes like the disk-based nonclustered indexes and the memory-optimized nonclustered indexes support index seek on a subset of the index key columns, as long as they are the leading columns in the index.
The hash index requires a key (to hash) to seek into the index. If an index key consists of two columns and you only provide the first column, SQL Server does not have a complete key to hash. This will result in an index scan query plan. Usage determines which columns should be indexed.
For a nonclustered memory-optimized index, the full key is not required to perform an index seek. Although, given the column order of the index key, a scan will occur if a value for a column comes after a missing column.
Appendix:
引用《Guidelines for Using Indexes on Memory-Optimized Tables》:
SELECT c1, c2 FROM t WHERE c1 = 1;
If there is no index on column c1, SQL Server will need to scan the entire table t, and then filter on the rows that satisfy the condition c1=1. However, if t has an index on column c1, SQL Server can seek directly on the value 1 and retrieve the rows.
When searching for records that have a specific value, or range of values, for one or more columns in the table, SQL Server can use an index on those columns to quickly locate the corresponding records. Both disk-based and memory-optimized tables benefit from indexes. There are, however, certain differences between index structures that need to be considered when using memory-optimized tables. (Indexes on memory-optimized tables are referred to as memory-optimized indexes.) Some of the key differences are:
Memory-optimized indexes must be created with CREATE TABLE (Transact-SQL). Disk-based indexes can be created with CREATE TABLE and CREATE INDEX.
Memory-optimized indexes exist only in memory. Index structures are not persisted to disk and index operations are not logged in the transaction log. The index structure is created when the memory-optimized table is created in memory, both during CREATE TABLE and during database startup.
Memory-optimized indexes are inherently covering. Covering means that all columns are virtually included in the index and bookmark lookups are not needed for memory-optimized tables. Rather than a reference to the primary key, memory-optimized indexes simply contain a memory pointer to the actual row in the table data structure.
Fragmentation and fillfactor do not apply to memory-optimized indexes. In disk-based indexes, fragmentation refers to pages in the B-tree being written to disk out-of-order. Memory-optimized indexes are not written to or read from disk. Fillfactor in disk-based B-tree indexes refers to the degree to which the physical page structures are filled with actual data. The memory-optimized index structures do not have fixed-size pages.
There are two types of memory-optimized indexes:
Nonclustered hash indexes, which are made for point lookups.
Nonclustered indexes, which are made for range scans and ordered scans.
With a hash index, data is accessed through an in-memory hash table. Hash indexes do not have pages and are always of a fixed size. However, a hash index can have empty hash buckets, which result in limited wasted space. The values returned from a query using a hash index are not sorted. Hash indexes are optimized for index seeks on equality predicates and also support full index scans.
Nonclustered indexes (not hash indexes) support everything that hash indexes supports plus seek operations on inequality predicates such as greater than or less than, as well as sort order. Rows can be retrieved according to the order specified with index creation. If the sort order of the index matches the sort order required for a particular query, for example if the index key matches the ORDER BY clause, there is no need to sort the rows as part of query execution. Memory-optimized nonclustered indexes are unidirectional; they do not support retrieving rows in a sort order that is the reverse of the sort order of the index. For example, for an index specified as (c1 ASC), it is not possible to scan the index in reverse order, as (c1 DESC).
Each index consumes memory. Hash indexes consume a fixed amount of memory, which is a function of the bucket count. For nonclustered indexes, memory consumption is a function of the row count and the size of the index key columns, with some additional overhead depending on the workload. Memory for memory-optimized indexes is in addition to and separate from the memory used to store rows in memory-optimized tables.
Duplicate key values always share the same hash bucket. If a hash index contains many duplicate key values, the resulting long hash chains will harm performance. Hash collisions, which occur in any hash index, will further reduce performance in this scenario. For that reason, if the number of unique index keys is at least 100 times smaller than the row count, you can reduce the risk of hash collisions by making the bucket count much larger (at least eight times the number of unique index keys; see Determining the Correct Bucket Count for Hash Indexes for more information) or you can eliminate hash collisions entirely by using a nonclustered index.
参考文档:
Guidelines for Using Indexes on Memory-Optimized Tables
Troubleshooting Common Performance Problems with Memory-Optimized Hash Indexes
标签:
原文地址:http://www.cnblogs.com/ljhdo/p/5762701.html