标签:
比对梯度下降和随机梯度下降:
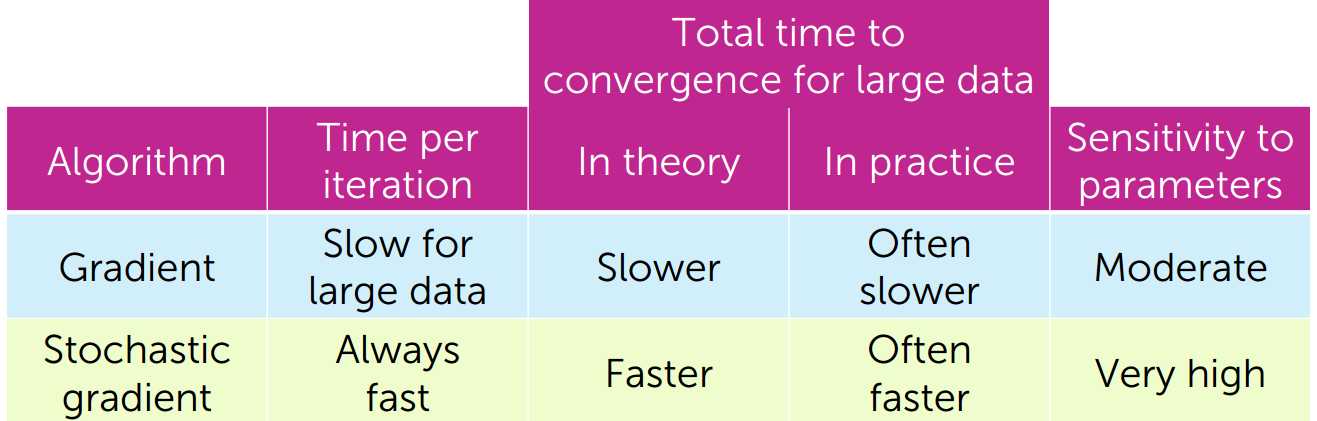
梯度下降:每一次迭代耗时长,在大数据集上处理速度慢,对参数敏感性适中
随机梯度下降:每一次迭代耗时短,在大数据集上处理速度较快,但对参数非常敏感
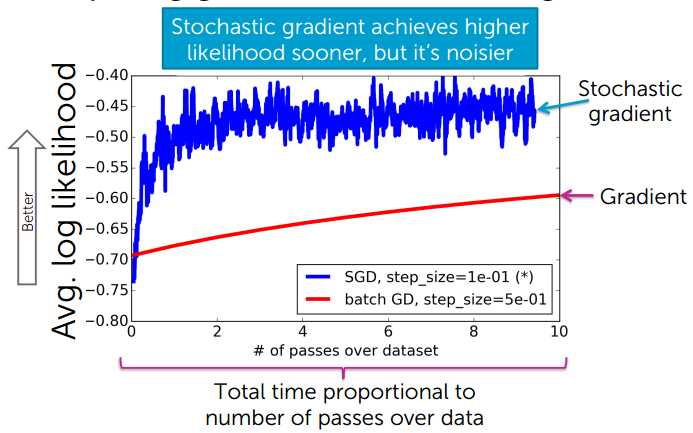
随机梯度下降能更快地达到较大的对数似然值,但噪声更大
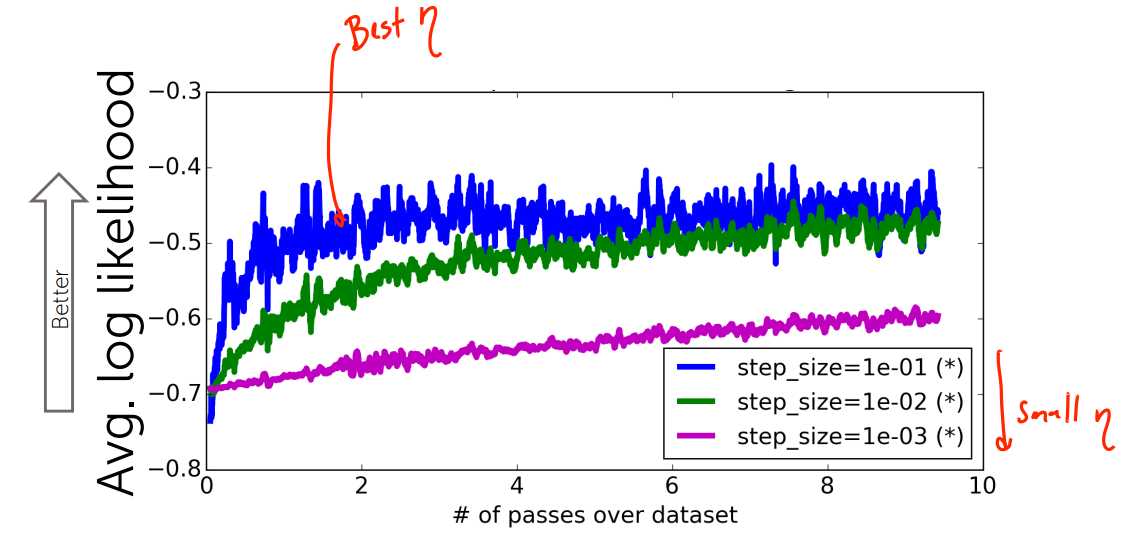
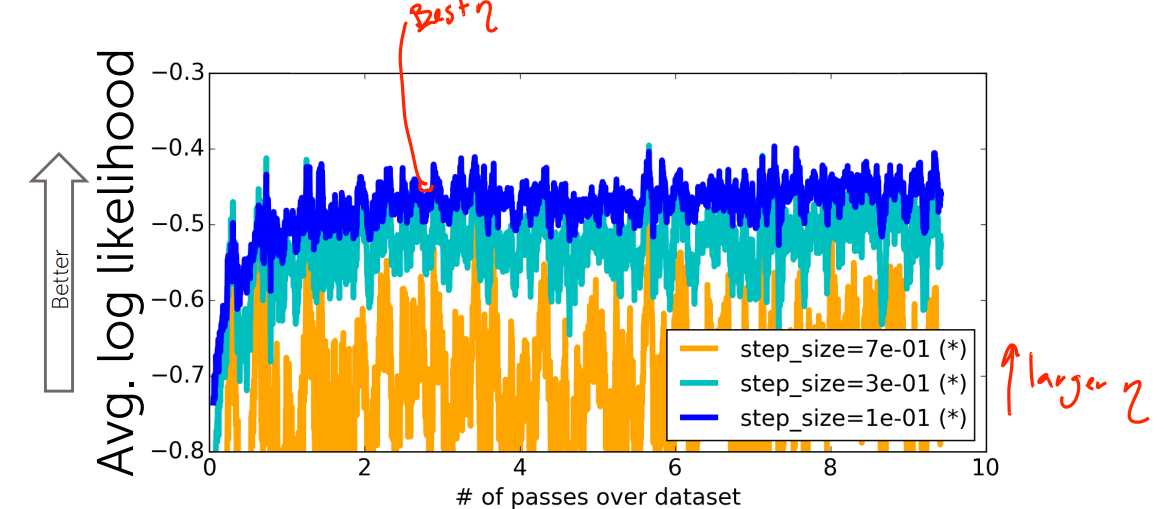
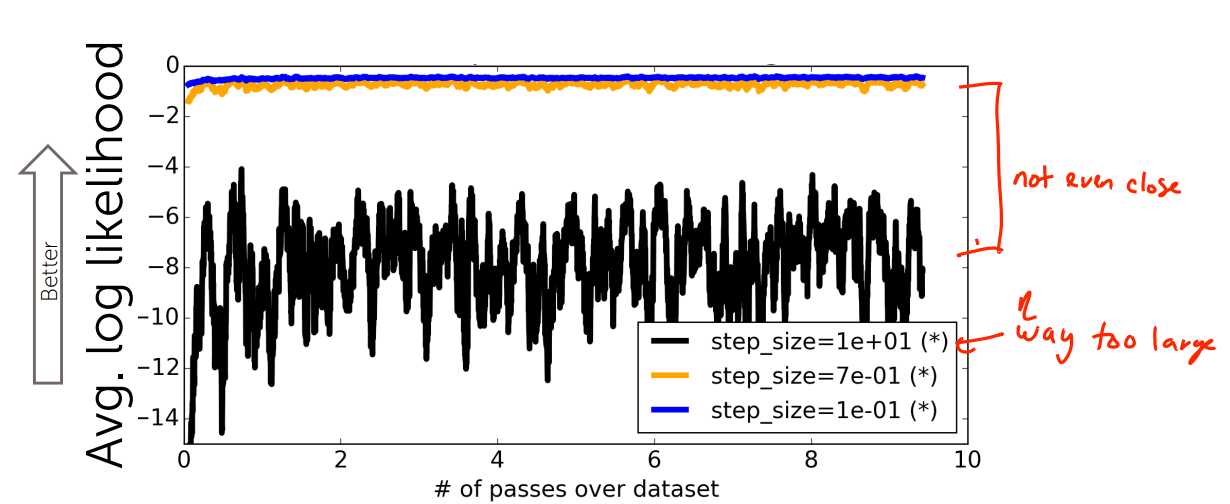
步长太小,收敛速度太慢;步长较大,震荡较大;步长异常大,不收敛
ML_Scaling to Huge Datasets & Online Learning
标签:
原文地址:http://www.cnblogs.com/sxbjdl/p/5772446.html