标签:
声明:本内容是博主在牛客网上看到的网友发表的答案,因为感觉总结的比较好,所以摘抄过来供大家学习。
内容:
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),其中Method Area 和 Heap 是线程共享的 ,VM Stack,Native Method Stack 和Program Counter Register 是非线程共享的。为什么分为 线程共享和非线程共享的呢?请继续往下看。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM初始运行的时候都会分配好 Method Area(方法区) 和Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么我把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说发生在Heap上)的原因。
如图下图所示:
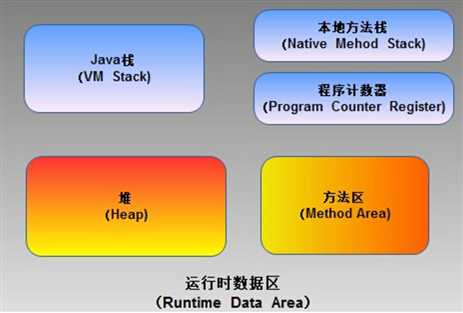
下面总结一下各区域的作用:
a) 程序计数器(PC寄存器)
由于在JVM中,多线程是通过线程轮流切换来获得CPU执行时间的,因此,在任一具体时刻,一个CPU的内核只会执行一条线程中的指令,因此,为了能够使得每个线程都在线程切换后能够恢复在切换之前的程序执行位置,每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序。因此,可以这么说,程序计数器是每个线程所私有的。由于程序计数器中存储的数据所占空间的大小不会随程序的执行而发生改变,因此,对于程序计数器是不会发生内存溢出现象(OutOfMemory)的。
b) java栈
Java栈中存放的是一个个的栈帧,每个栈帧对应一个被调用的方法,在栈帧中包括局部变量表(Local Variables) 、 操作数栈(Operand Stack) 、指向当前方法所属的类的运行时常量池的引用 (Reference to runtime constant pool)、方法返回地址(Return Address)和一些额外的附加信息。当线程执行一个方法时,就会随之创建一个对应的栈帧,并将建立的栈帧压栈。当方法执行完毕之后,便会将栈帧出栈。

c)本地方法栈
本地方法栈与Java栈的作用和原理非常相似。区别只不过是Java栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的
d)堆
Java中的堆是用来存储对象本身的以及数组(数组引用是存放在Java栈中的)。堆是被所有线程共享的,在JVM中只有一个堆。
e)方法区
与堆一样,是被线程共享的区域。在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。在Class文件中除了类的字段、方法、接口等描述信息外,还有一项信息是常量池,用来存储编译期间生成的字面量和符号引用。
标签:
原文地址:http://www.cnblogs.com/superpang/p/5772395.html