标签:
前言
前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题。
技术准备
VMware虚拟机、CentOS 6.8 64 bit
安装流程
因为我的笔记本是Window7操作系统,然后内存配置,只有8G,内存配置太低了,当然为了演示,我会将Hadoop集群中的主节点分配2GB内存,然后剩余的三个节点都是1GB配置。
所有的节点存储我都设置为50GB。
在安装操作系统之前,我们需要提前规划好操作系统的分区如何设置,我们知道,在 Linux系统中,它的磁盘分区并不同于Windows系统,它是通过目录挂载的方式进行分区,简单点说的话就是将不同的系统内置目录进行分配到不同的逻 辑分区中,然后我们在进行存储的时候只需要根据目录进行存放就可以了。
上面的这种分区方式是和Windows操作系统有区别的,当然在Linux操作系统中还存在磁盘格式的不同,比如一般常见的格式为:ext2,ext3,ext4等,我们当前最常用的就是ext3,关于每种格式的不同点和应用场景大家有兴趣的可以网上查阅,这里不再赘述。
那么我们来分析一下Linux系统中最常见的几种目录分区方式
以上为我基于我们的50GB的存储空间做的一个规划,如果生产或者物理机大家可以根据需要成比例递增。
我们完成了CentOS的基础配置,确保了计算机能够联网,下面我们就需要下载Hadoop安装包,然后进入Hadoop集群的搭建工作。
首先,我们需要下载安装Hadoop集群环境中需要的Jdk包,因为Java编写的嘛,然后下载Hadoop安装包,所以我们切换到CentOS的Downloads目录下:
cd /home/hadoop/Downloads
然后,下载我们所需要的安装包,到这个目录下:
cd /home/hadoop/Downloads/
我们找到相关的版本的java JDK和Hadoop版本包,这里我们选择Hadoop 最新的安装包,记住下载安装包的时候一定要上Hadoop官网上下载,能避免很多不必要的麻烦。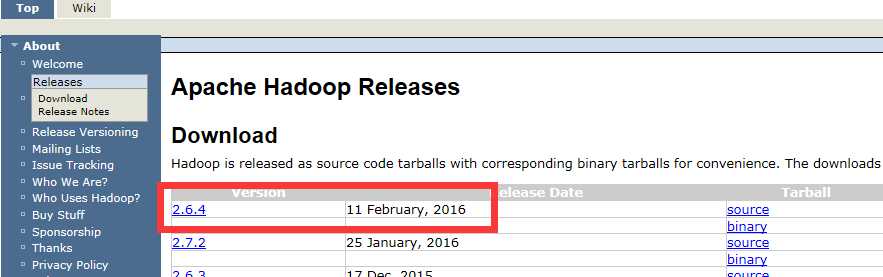
CentOS中下载脚本如下:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
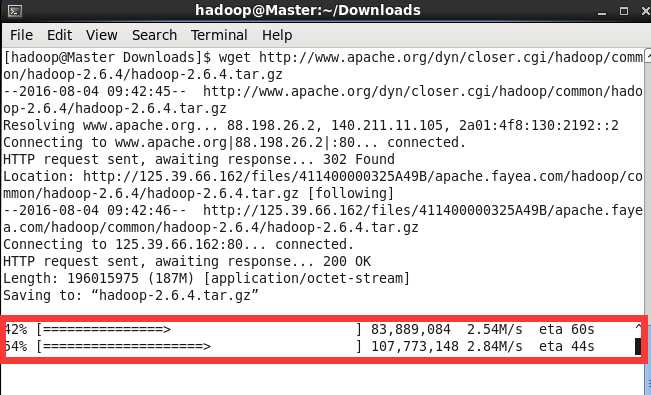
然后,我们下载JDK,这个上Oracle官网上,找到最新版本的JDK下载就可以了,同样我们也保存到Downloads目录中。
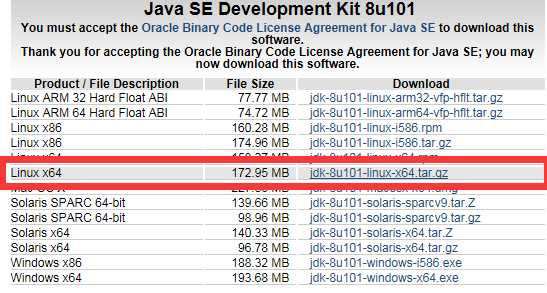
JDK下载脚本如下:
wget http://download.oracle.com/otn-pub/java/jdk/8u101-b13/jdk-8u101-linux-x64.tar.gz
到此,我们已经准备好了相关的安装包,有图有真相:
当然了,如果感觉这种方式比较麻烦,就直接下载到本地,然后拷贝到CentOS系统中就可以了,文章的最后我也会给出相关的下载包文件,再次提醒:一定要上官网下载!
8、上面完成了安装包的下载,下面就是Hadoop配置了。
其实,关于Hadoop环境的配置分为两步:1、Java环境配置;2、Hadoop配置。原因很简单,因为Hadoop就是Java语言编写的,所以一定要先配置好Java环境。
首先,我们来解压刚才我们下载的JDK文件,然后配置环境变量。
解压脚本如下,记住一点要在刚才咱们下载的Downloads文件夹下进行:
tar -zxvf jdk-8u101-linux-x64.tar.gz
如果这里一直报错,或者没法解压,那说明你下载的JDK安装包不完整,需要从新下载,或者你直接Windows环境下确保下载完成,顺便解压了。
所以,这里我就用了之前已经下载的jdk版本,直接解压就好了。
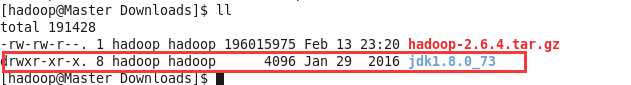
然后,上面我们已经介绍过,一般将安装的程序存入到系统的/usr目录中,所以这里在usr目录中创建一个Java目录,然后配置环境变量。
mkdir /usr/java
上面的脚本需要在root超级用户下进行创建,所以在执行命令的需要先用su命令进行提权。创建完成之后,记得更改一下这个java新建目录的权限。
chown hadoop:hadoop /usr/java/
上面的脚本就是将这个新建的java目录,变更Owner,直接赋权给hadoop用户。因为我们需要用这个用户进行环境的搭建。我们来验证下: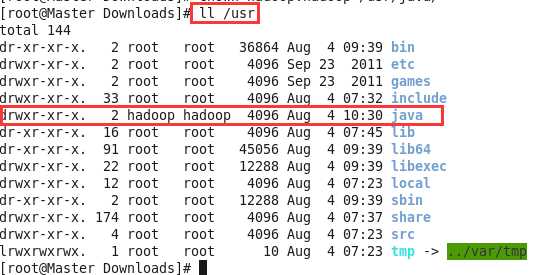
这里重点提示下:权限配置在linux系统中是一个很重的流程,一定要确保当前用户能够拥有文件的执行权限,要不会出现各种莫名其妙的问题!!!
下面,我们来更改一下系统的环境变量,记得使用root用户,编辑脚本:
vim /etc/profile
添加,如下脚本:
# set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_73
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
然后,将我们解压好的java文件夹拷贝至我们新创建的文件夹,刷新该文件,验证是否生效,脚本如下:
[root@Master Downloads]# cp -r jdk1.8.0_73 /usr/java/
[root@Master Downloads]# java -version

至此,我们的Java运行环境已经配置完成。
Hadoop的安装其实很简单的,因为只需要配置好相应的几个关键我文件就可以了。
首先,和上面的java配置类似,我们现在/usr目录下创建一个hadoop文件夹,然后赋权给hadoop用户,然后将我们下载的hadoop安装包进行解压,拷贝至我们新建的hadoop目录,脚本如下:

--解压Hadoop安装包
tar -zxvf hadoop-2.6.4.tar.gz
--/usr目录下,创建hadoop目录
mkdir /usr/hadoop
--拷贝解压后的hadoop安装包
cp -r hadoop-2.6.4 /usr/hadoop
--赋权给Hadoop用户
chown hadoop:hadoop /usr/hadoop/
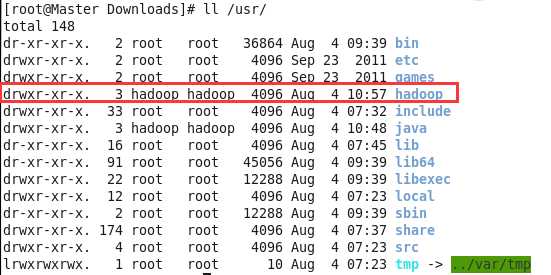
我们下面就是需要对几个关键的文件进行配置了,详细步骤如下:
首先,我们先进入到我们要配置的hadoop安装目录中:
cd /usr/hadoop/hadoop-2.6.4/
这里提示一下,所有的咱们需要配置的文件都存放于hadoop安装目录的/etc/hadoop中,首先咱们来配置第一个文件core-site.xml
vim etc/hadoop/core-site.xml
添加以下内容:
<configuration>
<!-- HDFS file path -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.50:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.4/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
</configuration>
上面的配置项很简单,首先配置HDFS默认的连接地址,然后流文件的配置大小,默认是4K太小了,这里我们将这个值改的大一点,然后最后就是生成临时结果的配置路径,这里需要根据你的配置结果手动创建。
下面,我们就来创建该目录,如果在生产环境中,我们需要将该配置的目录指定到一个固定的配置目录下,这里咱们方便演示就直接配置到Hadoop安装目录里面了。
脚本如下:
mkdir tmp
然后,咱来配置第二个文件hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.50:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.4/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.4/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
这几个参数解释下含义:
<1>dfs.namenode.secondary.http-address 这个含义就是SecondName的地址,在上一篇文章中我就分析过,这个是作为NameNode的一个备份,目的就是灾备之用了。因为我们这个就一个机器所以都配置了相同的机器,只是用了不同的端口。
<2>dfs.namenode.name.dir 和 dfs.namenode.data.dir两个配置指的是NameNode存储的DataNode元数据的信息,这里需要配置两个目录一个是存放Name和Data目录,稍后我们需要手动创建出这两个目录
<3>dfs.replication这个含义是数据文件块(black)复制备份的个数,我们知道在HDFS分布式文件系统中,为了保证数据的完整性,底层的机制是需要多拷贝几份数据分不到不同的计算机上的,目的同样是灾备。
<4>dfs.webhdfs.enabled这个指的是是否可以通过web站点进行Hdfs管理,后面我们会演示,如何通过页面打开HDFS文件。
好,我们下面手动来创建上面的Name和Data的两个目录:
mkdir dfs
mkdir dfs/name
mkdir dfs/data
至此,我们第二个文件配置完成。
然后,咱来配置第三个文件mapred-site.xml
前面的两个文件,都有现成的文件进行配置,但是,这第三个文件需要我们自己来创建,当然,Hadoop系统给我们提供了一个模板文件,所以我们拷贝形成一份新的就行了。
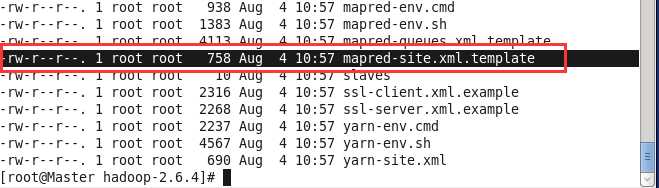
我们执行cp命令,来创建一个新的mapred-site.xml文件。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
然后,修改该文件。脚本如下:
vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.50:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.50:19888</value>
</property>
</configuration>
我们来解释这几个参数的含义:第一个就是制定当前Hadoop的并行运行计算架构,这里为yarn,当然还有其它的运行架构比如:spark等,第二个就是Job运行的历史记录Server,第三个就是历史运行记录的Web服务器。
然后,咱来配置第四个文件yarn-site.xml。
vim etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.50:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.50:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.50:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.50:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.50:8088</value>
</property>
这个yarn的配置参数我就不怎么解释了,因为我们后续的调优会一直围绕这个文件进行。
至此,我们已经完成了Hadoop四个配置文件的配置,然后,不要忘记了最重要的一点:配置Hadoop的jdk路径,不指定是不能运行的。
hadoop-env.sh 和 yarn-env.sh 在开头添加如下java环境变量:
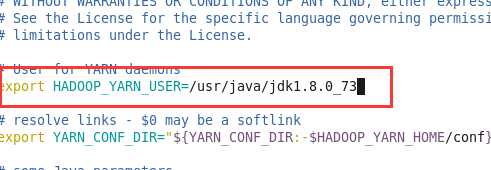
export JAVA_HOME=/usr/java/jdk1.8.0_73
vim etc/hadoop/hadoop-env.sh
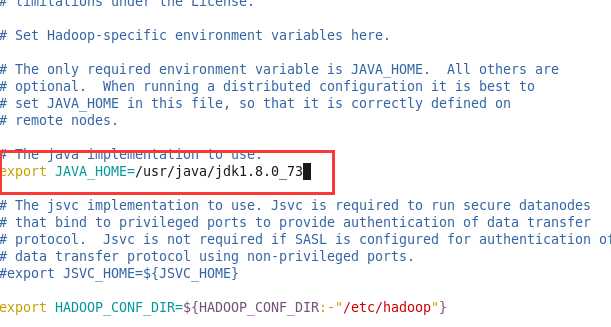
同样的道理,我们来配置yarn-env.sh 文件。
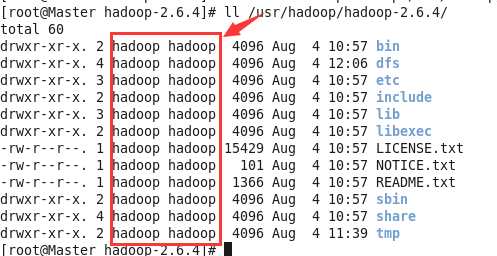
好了,到此,我们已经完成了Hadoop所有的配置文件,这个过程一定要小心认真。然后在最后放一个大招,我们知道我们需要制定这所有的文件Hadoop用户都有执行权限,所以我们将通过如下命令将Hadoop文件夹下所有的文件,进行Owner变更。
chown -R hadoop:hadoop /usr/hadoop/hadoop-2.6.4/
我再强调一遍,已经要把权限配置好,要不后面的运行故障足够把你玩死!!!
8、上面我们完成了Hadoop基础配置,然后我们格式化文件,来启动这个单节点的Hadoop集群。
到此,我们已经完成了Hadoop的配置了,下面要做的就是格式化HDFS文件,然后启动单节点的Hadoop集群。
bin/hadoop namenode -format
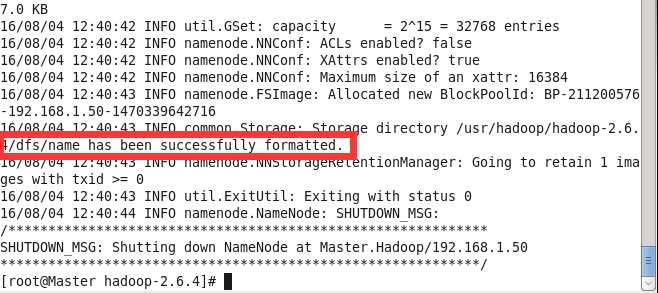
看到上面现实的信息,那就说明你已经成功执行了,否则报什么错误,解决什么错误。一般错误的原因都是配置文件粗心导致的错误,自己仔细检查就得了。
好了,如果没有任何异常,那面所有准备工作已经完成了,下面就可以开始启动
注:为了防止其他问题建议关闭防火墙和selinux
1)关闭防火墙(每个节点)
|
1
2
|
service iptables stopchkconfig iptables off |
|
1
|
vim /etc/selinux/config |

这里的验证方式有两点,第一点就是保证HDFS完整没问题,验证方式如下:
首先,启动HDFS
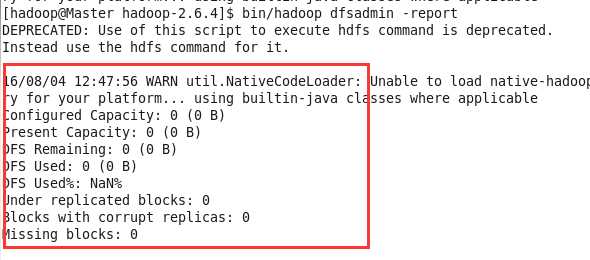
sbin/start-dfs.sh
然后,查看状态
bin/hadoop dfsadmin -report
还有一种更直接的方式,直接打开浏览器查看:http://192.168.1.50:50070/dfshealth.html#tab-overview
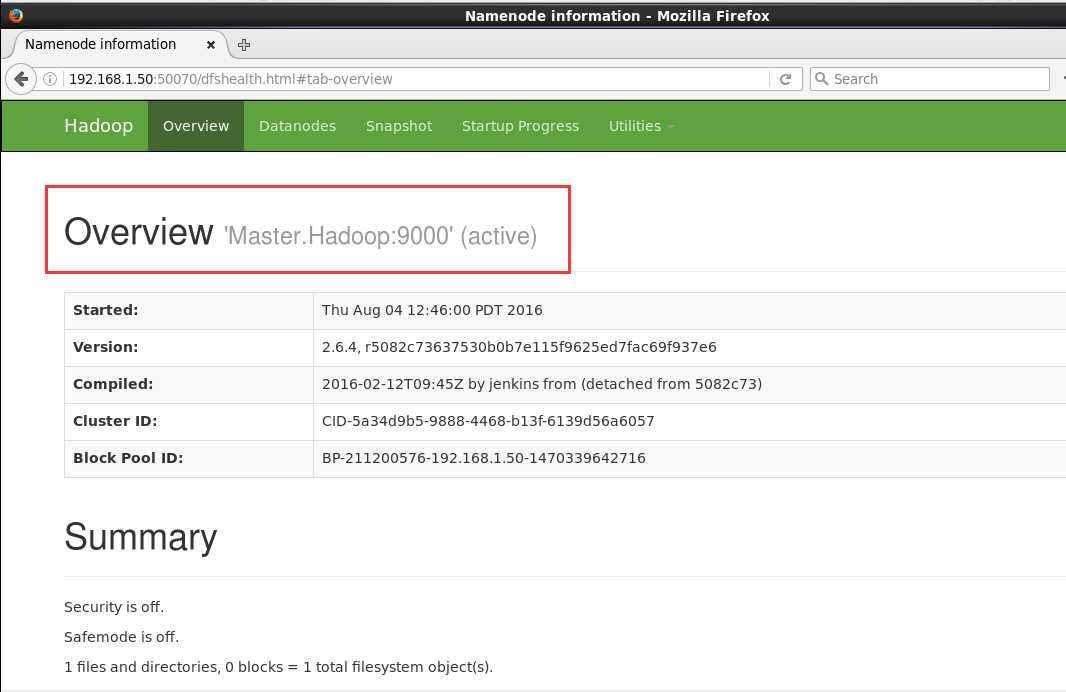
是不是很酷,这里可以直接查看分布式文件系统HDFS的各个状态。有兴趣的自己查看吧...我们接着验证其它的内容。
首先,我来启动Hadoop集群,然后查看其状态,脚本如下:
sbin/start-yarn.sh
这次来个大招,直接打来浏览器瞅瞅,地址为:
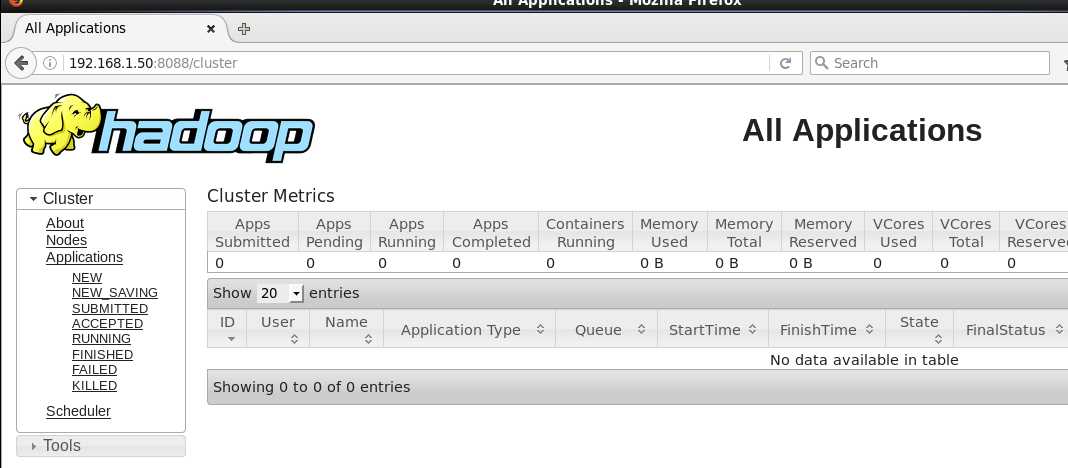
至此,一款单机版的装X神器Hadoop已经被我们搭建成功,当然这只是单机版的后面我们会逐渐完善它,并且,将节点完全配置成功。
在完成到此的时候,已经可以进行集群搭建了,然后后面的文章我将教你怎么搭建所谓的伪分布式...全分布式的大数据平台。....淡定....不要着急.....
结语
此篇篇幅已经超长度了,先到此吧,关于Hadoop大数据集群的搭建后续依次介绍,比如利用Zookeeper搭建Hadoop高可用平台、 Map-Reducer层序的开发、Hive产品的数据分析、Spark的应用程序的开发、Hue的集群坏境的集成和运维、Sqoop2的数据抽取等,有 兴趣的童鞋可以提前关注。
本篇主要介绍了搭建一个Hadoop单机集群,后面我们会逐渐完善它,我会教你如何一步步的搭建起完全分布式的Hadoop集群,然后教你如何使用它,骚年...不要捉急...让思维飞一会...
有问题可以留言或者私信,随时恭候有兴趣的童鞋加大数据平台深入研究。共同学习,一起进步。
标签:
原文地址:http://www.cnblogs.com/fanlinglong/p/5774938.html