标签:
从上节已经知道perceptron 不是什么智能算法,在它的基础上我们需要去解决调参的问题。既然是调节参数,总要有个目标和手段吧,看看这些大神怎么搞的。首先建立目标,对于生活里面常常会面对分类的问题,比如:在人群中把流氓分子找出来,我们已经有3000个强奸犯和7000个普通的人的档案记录. 大家希望找到一个办法,给出新的档案,按照这个档案的情况识别第10001个人是不是是不是流氓。好吧,这很不道德,流氓好像也显得太多,但我们姑且这么干吧。首先我们先用人的模式干一次这个事情。先把应用题要求梳理一下。
1.有10000个样本。
2.每个样本有2条属性 贪吃程度 X (对应P1)和 好色程度 Y(对应P2)以及是否是流氓A。
3.找个新的人来看看,是不是流氓。
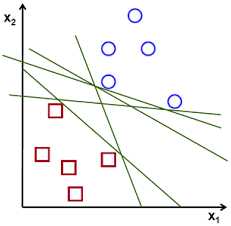
如果运气好,我们可以得到右边的图(蓝色是流氓)。这时同学们立马就发现,哎呀原来又贪吃又好色的基本都是流氓啊。所以简单在中间画条线就能把这两类人区分开来。新人一来就根据这条线一分就搞定。通过这个例子马上可以总结出来基本工作的逻辑。
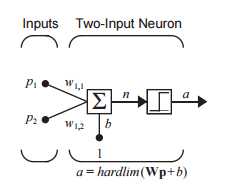
perceptron 能干啥?他不是最喜欢划线么,按照上一节的方式把perceptron拉进来.尝试着找个办法让perceptron 自己来划划这条线。先来个笨的,计算机最爱搞循环,写个loop吧所有的可能性都试试看,最后把线画出来,这行么?这当然可以,到这里这个perceptron已经具备"智能",而你刚才也实现了第一个学习算法.在下很满意,以后同类问题它都可以用这个法子解决。
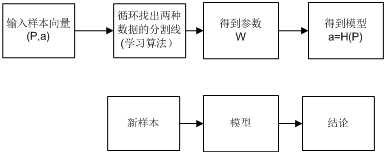
所以这个“机器学习”本质上在猜规则,“学习”就是具体的方法中猜的过程。对10001个来说,误判为流氓的可能任然存在。再看看刚才我们用人的划线不也一样么,在中间位置都是可以的,4条线段对于这10000个样本都是正取结果,既然有这么多可能性,他们之间必然有所差异,能不能找一个好点的出来呢。所以,这里就提出来第二个要求,那就是如何有效的评估猜测的结果,然后按照评估结果把最好的留下来。具体一点,我们用方差来评估吧(事实上你爱怎么评估都可以,这取决于你的具体场景),我们就按照最靠中间的来。这个基本逻辑倒是很符合“认知神经学”的基本模式。这样一个基本的“机器学习”的框架和算法就有了。
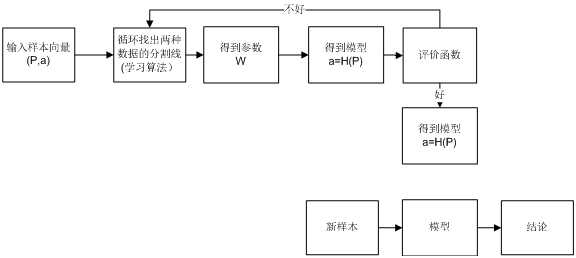
这种工作模式就是一类“机器学习“的基本模式。它有个高大上的名字”监督学习( supervised learning)“.也就是:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程.循环里面的过程加到一起叫做”训练“.

从下往上看--新皮层资料的读后感 第五部分 从perceptron 感知机学习自动调参开始
标签:
原文地址:http://www.cnblogs.com/nasiry/p/5774952.html