标签:
1、什么是HashMap?
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。
2、与HashMap相关的HashTable表
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。
#HashTable的思路:
Hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址。
#HashTable函数的设计:
1)直接定址法
取关键字或者关键字的某个线性函数为Hash地址,即address(key)=a*key+b;如知道学生的学号从2000开始,最大为4000,则可以将address(key)=key-2000作为Hash地址。
2)平方取中法
对关键字进行平方运算,然后取结果的中间几位作为Hash地址。假如有以下关键字序列{421,423,436},平方之后的结果为{177241,178929,190096},那么可以取{72,89,00}作为Hash地址。
3)折叠法
将关键字拆分成几部分,然后将这几部分组合在一起,以特定的方式进行转化形成Hash地址。假如知道图书的ISBN号为8903-241-23,可以将address(key)=89+03+24+12+3作为Hash地址。
4)除留取余法
如果知道Hash表的最大长度为m,可以取不大于m的最大质数p,然后对关键字进行取余运算,address(key)=key%p。在这里p的选取非常关键,p选择的好的话,能够最大程度地减少冲突,p一般取不大于m的最大质数。
#HashTable表大小的确定:
Hash表大小的确定也非常关键,如果Hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
#HashTable冲突的解决:
1)开放定址法:
即当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。比较常用的探测方法有线性探测法。比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为 14,Hash函数为address(key)=key%11,当插入12,13,25时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1 依次往下探测(探测步长可以根据情况而定),直到探测到地址4,发现为空,则将23插入其中。
2)链地址法:
采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。如上述例子中,采用链地址法形成的Hash表存储表示为:
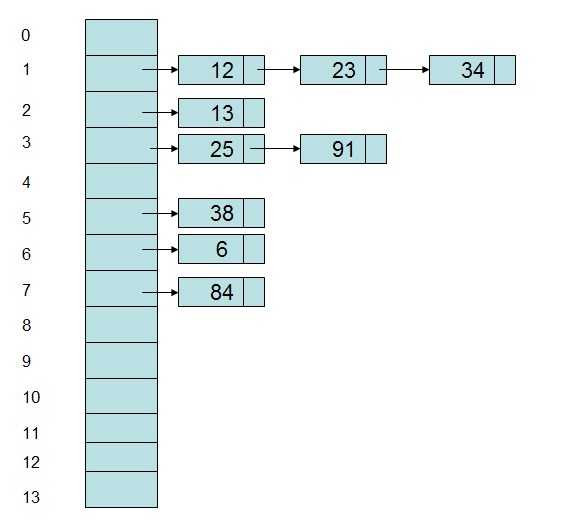
#HashTable表的优缺点:
Hash表存在的优点显而易见,能够在常数级的时间复杂度上进行查找,并且插入数据和删除数据比较容易。但是它也有某些缺点,比如不支持排序,一般比用线性表存储需要更多的空间,并且记录的关键字不能重复。
3、HashMap与HashTable的区别
1)Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
2)HashMap可以让你将空值作为一个表的条目的key或value。HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。
3)Hashtable的方法是同步①的,而HashMap的方法不是,所以在多线程场合要手动同步HashMap,而在单线程程序中,使用HashMap则相比HashTable更节省资源。
*HashMap 是Hashtable 的轻量级实现(非线程安全的实现)
①关于程序的同步与异步:
#线程同步:同步是指只有一个线程可以调用,如果其它线程想调用,默认等待,等第前一个线程释放了,然后才能进行调用,并且同步也会耗费额外的资源。————synchronized机制:synchronized用来修饰一个方法或者一个代码块,它用来保证在同一时刻最多只有一个线程执行该段代码。可以使用同步机制较好地解决并发问题,在一定程度上可以避免出现资源抢占、竞争条件和死锁的情况,但其副作用是同步锁可导致线程阻塞。这要求同步方法的执行时间不能太长(上锁)。
#线程异步:与线程同步相反,即可以满足多个线程同时调用(解锁)。
4、HashMap工作原理
#存储方式:Java中的HashMap是以键值对(key-value)的形式存储元素。
#调用原理:当往HashMap中存入key-value时,先对key对象调用hashcode()方法取得hash值作为内存地址存储value。get(key)方法则采用相同的步骤,用key得hash值找到value的位置。
5、HashMap常用方法
put(k, v) 放入键值对数据
get(k) 用键获得对应的值
remove(k) 移除指定的键和它的值
containsKey(key) 是否包含指定的键
containsValue(value)是否包含指定的值
size() 有多少对数据
clear() 清空
keySet() 获得一个 Set 类型集合,包含所有的键
map.entrySet() 获得一个 Set 类型结合,包含所有
Entry
values() 获得集合,包含所有的值
申明:
本文作者:逍破孩
未经许可,不得转载。转载请注明出处。
注:新晋菜鸟欢迎大家纠错,讨论。
原文参考出处:
标签:
原文地址:http://www.cnblogs.com/xiaopohai97/p/5778226.html