标签:style blog class ext color width
前面提到了YV12转RGB的各种实现方法和优化方法,主要是CPU上的实现。本文主要介绍基于GPU的YV12转RGB的实现。
<!--[if !supportLists]-->1. <!--[endif]-->基于OpenGL的实现
利用OpenGL shader实现将YV12转RGB,将Y、U、V分量数据作为纹理数据,并构造YUV转RGB的shader代码,最终纹理数据在shader代码作用下,实现YV12转RGB。该方法适合于将YV12转RGB后直接显示,若YV12转化成RGB后,还需要进行图像处理操作,则利用OpenGL进行纹理数据的图像处理操作不方便。说明:由于本文着重于基于Cuda的实现,因而未验证基于OpenGL的代码实现。
具体资料可参考:
http://blog.csdn.net/xiaoguaihai/article/details/8672631
http://www.fourcc.org/source/YUV420P-OpenGL-GLSLang.c
<!--[if !supportLists]-->2. <!--[endif]-->基于Cuda的实现
YV12转RGB的过程是逐一获取像素的Y、U、V分量,然后通过转换公式计算得RGB。基于CUDA的实现关键在于两个步骤:Y、U、V分量的获取,RGB的计算。Y、U、V分量的获取与YUV的内存布局有关,RGB的计算公式一般是固定不变。具体的代码实现如下所示,主要参考NV12ToARGB.cu的代码,在该代码的基础上,保持RGB的计算方法不变,修改了Y、U、V分量的获取方法。
|
#include "cuda.h" #include "cuda_runtime_api.h"
#define COLOR_COMPONENT_BIT_SIZE 10 #define COLOR_COMPONENT_MASK 0x3FF
__constant__ float constHueColorSpaceMat[9]={1.1644f,0.0f,1.596f,1.1644f,-0.3918f,-0.813f,1.1644f,2.0172f,0.0f};
__device__ staticvoid YUV2RGB(constint* yuvi,float* red,float* green,float* blue) { float luma, chromaCb, chromaCr;
// Prepare for hue adjustment luma =(float)yuvi[0]; chromaCb =(float)((int)yuvi[1]-512.0f); chromaCr =(float)((int)yuvi[2]-512.0f);
// Convert YUV To RGB with hue adjustment *red =(luma * constHueColorSpaceMat[0])+ (chromaCb * constHueColorSpaceMat[1])+ (chromaCr * constHueColorSpaceMat[2]);
*green =(luma * constHueColorSpaceMat[3])+ (chromaCb * constHueColorSpaceMat[4])+ (chromaCr * constHueColorSpaceMat[5]);
*blue =(luma * constHueColorSpaceMat[6])+ (chromaCb * constHueColorSpaceMat[7])+ (chromaCr * constHueColorSpaceMat[8]); }
__device__ staticint RGBA_pack_10bit(float red,float green,float blue,int alpha) { int ARGBpixel =0;
// Clamp final 10 bit results red =::fmin(::fmax(red, 0.0f),1023.f); green =::fmin(::fmax(green,0.0f),1023.f); blue =::fmin(::fmax(blue, 0.0f),1023.f);
// Convert to 8 bit unsigned integers per color component ARGBpixel =(((int)blue >>2)| (((int)green >>2)<<8) | (((int)red >>2)<<16)| (int)alpha);
return ARGBpixel; }
__global__ void YV12ToARGB_FourPixel(constunsignedchar* pYV12,unsignedint* pARGB,int width,int height) { // Pad borders with duplicate pixels, and we multiply by 2 because we process 4 pixels per thread constint x = blockIdx.x *(blockDim.x <<1)+(threadIdx.x <<1); constint y = blockIdx.y *(blockDim.y <<1)+(threadIdx.y <<1);
if((x +1)>= width ||(y +1)>= height) return;
// Read 4 Luma components at a time int yuv101010Pel[4]; yuv101010Pel[0]=(pYV12[y * width + x ])<<2; yuv101010Pel[1]=(pYV12[y * width + x +1])<<2; yuv101010Pel[2]=(pYV12[(y +1)* width + x ])<<2; yuv101010Pel[3]=(pYV12[(y +1)* width + x +1])<<2;
constunsignedint vOffset = width * height; constunsignedint uOffset = vOffset +(vOffset >>2); constunsignedint vPitch = width >>1; constunsignedint uPitch = vPitch; constint x_chroma = x >>1; constint y_chroma = y >>1;
int chromaCb = pYV12[uOffset + y_chroma * uPitch + x_chroma]; //U int chromaCr = pYV12[vOffset + y_chroma * vPitch + x_chroma]; //V
yuv101010Pel[0]|=(chromaCb <<( COLOR_COMPONENT_BIT_SIZE +2)); yuv101010Pel[0]|=(chromaCr <<((COLOR_COMPONENT_BIT_SIZE <<1)+2)); yuv101010Pel[1]|=(chromaCb <<( COLOR_COMPONENT_BIT_SIZE +2)); yuv101010Pel[1]|=(chromaCr <<((COLOR_COMPONENT_BIT_SIZE <<1)+2)); yuv101010Pel[2]|=(chromaCb <<( COLOR_COMPONENT_BIT_SIZE +2)); yuv101010Pel[2]|=(chromaCr <<((COLOR_COMPONENT_BIT_SIZE <<1)+2)); yuv101010Pel[3]|=(chromaCb <<( COLOR_COMPONENT_BIT_SIZE +2)); yuv101010Pel[3]|=(chromaCr <<((COLOR_COMPONENT_BIT_SIZE <<1)+2));
// this steps performs the color conversion int yuvi[12]; float red[4], green[4], blue[4];
yuvi[0]=(yuv101010Pel[0]& COLOR_COMPONENT_MASK ); yuvi[1]=((yuv101010Pel[0]>> COLOR_COMPONENT_BIT_SIZE) & COLOR_COMPONENT_MASK); yuvi[2]=((yuv101010Pel[0]>>(COLOR_COMPONENT_BIT_SIZE <<1))& COLOR_COMPONENT_MASK);
yuvi[3]=(yuv101010Pel[1]& COLOR_COMPONENT_MASK ); yuvi[4]=((yuv101010Pel[1]>> COLOR_COMPONENT_BIT_SIZE) & COLOR_COMPONENT_MASK); yuvi[5]=((yuv101010Pel[1]>>(COLOR_COMPONENT_BIT_SIZE <<1))& COLOR_COMPONENT_MASK);
yuvi[6]=(yuv101010Pel[2]& COLOR_COMPONENT_MASK ); yuvi[7]=((yuv101010Pel[2]>> COLOR_COMPONENT_BIT_SIZE) & COLOR_COMPONENT_MASK); yuvi[8]=((yuv101010Pel[2]>>(COLOR_COMPONENT_BIT_SIZE <<1))& COLOR_COMPONENT_MASK);
yuvi[9]=(yuv101010Pel[3]& COLOR_COMPONENT_MASK ); yuvi[10]=((yuv101010Pel[3]>> COLOR_COMPONENT_BIT_SIZE) & COLOR_COMPONENT_MASK); yuvi[11]=((yuv101010Pel[3]>>(COLOR_COMPONENT_BIT_SIZE <<1))& COLOR_COMPONENT_MASK);
// YUV to RGB Transformation conversion YUV2RGB(&yuvi[0],&red[0],&green[0],&blue[0]); YUV2RGB(&yuvi[3],&red[1],&green[1],&blue[1]); YUV2RGB(&yuvi[6],&red[2],&green[2],&blue[2]); YUV2RGB(&yuvi[9],&red[3],&green[3],&blue[3]);
pARGB[y * width + x ]= RGBA_pack_10bit(red[0], green[0], blue[0],((int)0xff<<24)); pARGB[y * width + x +1]= RGBA_pack_10bit(red[1], green[1], blue[1],((int)0xff<<24)); pARGB[(y +1)* width + x ]= RGBA_pack_10bit(red[2], green[2], blue[2],((int)0xff<<24)); pARGB[(y +1)* width + x +1]= RGBA_pack_10bit(red[3], green[3], blue[3],((int)0xff<<24)); }
bool YV12ToARGB(unsignedchar* pYV12,unsignedchar* pARGB,int width,int height) { unsignedchar* d_src; unsignedchar* d_dst; unsignedint srcMemSize =sizeof(unsignedchar)* width * height *3/2; unsignedint dstMemSize =sizeof(unsignedchar)* width * height *4;
cudaMalloc((void**)&d_src,srcMemSize); cudaMalloc((void**)*d_dst,dstMemSize); cudaMemcpy(d_src,pYV12,srcMemSize,cudaMemcpyHostToDevice);
dim3 block(32,8); int gridx =(width +2*block.x -1)/(2*block.x); int gridy =(height +2*block.y -1)/(2*block.y); dim3 grid(gridx,gridy);
YV12ToARGB<<<grid,block>>>(d_src,(unsignedint*)d_dst,width,height); cudaMemcpy(pARGB,d_dst,dstMemSize,cudaMemcpyDeviceToHost); returntrue; } |
线程内存访问示意图如下所示,每个线程访问4个Y、1个U、1个V,最终转换得到4个ARGB值。由于YV12属于YUV4:2:0采样,每四个Y共用一组UV分量,即Y(0,0)、Y(0,1)、Y(1,0)、Y(1,1)共用V(0,0)和U(0,0),如红色框标注所示。
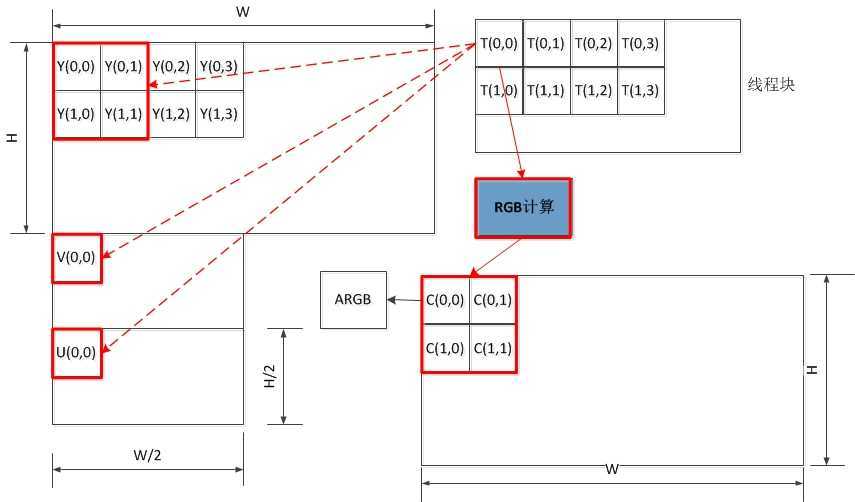
<!--[endif]-->
<!--[if !supportLists]-->3. <!--[endif]-->基于Cuda的实现优化
优化主要关注于两个方面:单个线程处理像素粒度和数据传输。单个线程处理粒度分为:OnePixelPerThread,TwoPixelPerThread,FourPixelPerThread。数据传输优化主要采用Pageable Memory,Pinned Memory,Mapped Memory(Zero Copy)。经测试,不同实现版本的转换效率如下表所示,测试序列:1920*1080,时间统计包括内核函数执行时间和数据传输时间,单位为ms。
|
|
OnePixel |
TwoPixel |
FourPixel |
|
Pageable |
6.91691 |
6.64319 |
6.2873 |
|
Pinned |
5.31999 |
5.01890 |
4.71937 |
|
Mapped |
3.39043 |
48.5298 |
23.8327 |
由上表可知,不使用Mapped Memory(Zero Copy)时,单个线程处理像素的粒度越大,内核函数执行的时间越小,转换效率越好。使用Mapped Memory(Zero Copy)时,单线程处理单像素时,转换效率最好。
单个线程处理四个像素时,内核函数执行时间最少;使用Pinned Memory会减少数据传输时间;使用Mapped Memory消除数据传输过程,但会增加内核函数执行时间,最终优化效果与内核函数访问内存的方式有关。建议使用Pinned Memory+FourPixelPerThread的优化版本。
【视频处理】YV12ToARGB,布布扣,bubuko.com
标签:style blog class ext color width
原文地址:http://www.cnblogs.com/dwdxdy/p/3714034.html