标签:
1.简介
现在很少用到使用MR计算框架来实现功能,通常的做法是使用hive等工具辅助完成。
但是对于其底层MR的原理还是有必要做一些了解。
2.MR客户端程序实现套路
这一小节总结归纳编写mr客户端程序的一般流程和套路。将以wordcount为例子进行理解。
运行一个mr程序有三种模式,分别为:本地模式,本地集群模式,命令行集群模式
3.代码实现
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * 新API中对job提交类的建议写法 * */ public class WordCountDriver extends Configured implements Tool{ /** * 在run方法中对job进行封装 */ @Override public int run(String[] args) throws Exception { Configuration conf = new Configuration(); //先构造一个用来提交我们的业务程序的一个信息封装对象 Job job = Job.getInstance(conf); //指定本job所采用的mapper类 job.setMapperClass(WordCountMapper.class); //指定本job所采用的reducer类 job.setReducerClass(WordCountReducer.class); //指定我们的mapper类输出的kv数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //指定我们的reducer类输出的kv数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定我们要处理的文件所在的路径 FileInputFormat.setInputPaths(job, new Path("/Users/apple/Desktop/temp/data/input/")); //指定我们的输出结果文件所存放的路径 FileOutputFormat.setOutputPath(job, new Path("/Users/apple/Desktop/temp/data/output")); return job.waitForCompletion(true)? 0:1; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCountDriver(), args); System.exit(res); } //在hadoop中,普通的java类不适合做网络序列化传输,hadoop对java的类型进行了封装,以便于利用hadoop的序列化框架进行序列化传输 public static class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { /** * map方法是每读一行调用一次 */ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //拿到一行的内容 String line = value.toString(); //切分出一行中所有的单词 String[] words = line.split(" "); //输出<word,1>这种KV对 for(String word:words){ //遍历单词数组,一对一对地输出<hello,1> <tom,1> ....... context.write(new Text(word), new LongWritable(1)); } } } public static class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ /** * reduce方法是每获得一个<key,valueList>,执行一次 */ //key : 某一个单词 ,比如 hello //values: 这个单词的所有v, 封装在一个迭代器中,可以理解为一个list{1,1,1,1.....} @Override protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { long count = 0; //遍历该key的valuelist,将所有value累加到计数器中去 for(LongWritable value:values){ count += value.get(); } context.write(key, new LongWritable(count)); } } }
3. 本地模式运行
使用eclipse编完代码后直接即可运行,但是此种运行只发生在本地,并不会被提交到集群环境运行,换句话说在yarn的web上是无法查询到这个任务的。
这种模式的好处在于可以方便的debug。
在此种模式下输入和输出的路径可以指定为本地路径,也可以指定为hdfs路径。如果使用本地路径则上述代码即可执行。当指定为hdfs路且hdfs集群的配置为hadoop2.x的主备
模式的话则需要引入hdfs-site.xml文件(因为主备模式下hdfs的url是一个service,需要通过配置文件才能解析这个url):
下述例子为指定hdfs路径为输入输出源头,需要引入xml文件到classpath
//指定我们要处理的文件所在的路径 FileInputFormat.setInputPaths(job, new Path("hdfs://ns1/wordcountData/input")); //指定我们的输出结果文件所存放的路径 FileOutputFormat.setOutputPath(job, new Path("hdfs://ns1/wordcountData/output"));
input路径下的文件内容为:
[hadoop@xufeng-1 temp]$ hadoop fs -cat /wordcountData/input/words.txt 16/07/28 18:09:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable aaa bbb ccc ddd aaa ccc ddd eee eee ggg ggg hhh aaa [hadoop@xufeng-1 temp]$
通过eclipse启动的时候会有权限问题,可以在vm中指定用户名:
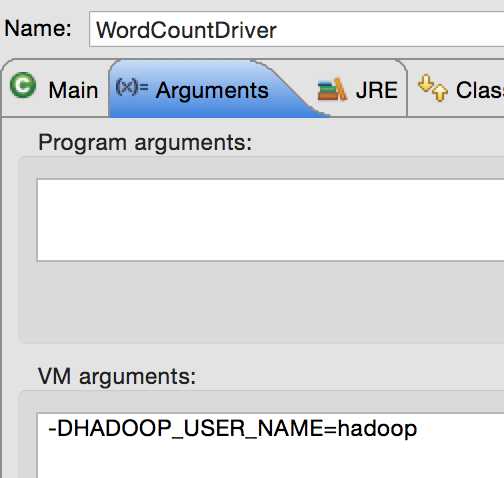
启动程序,在日志中我们可以看到当前mr是通过本地模式执行的,在查看yarn的监控web,并没有这个任务的记录。
2016-08-17 11:54:02,291 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks
在输出文件夹中查看结果:
[hadoop@xufeng-1 temp]$ hadoop fs -ls /wordcountData/output 16/07/28 18:22:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items -rw-r--r-- 1 hadoop supergroup 0 2016-07-28 17:58 /wordcountData/output/_SUCCESS -rw-r--r-- 1 hadoop supergroup 42 2016-07-28 17:58 /wordcountData/output/part-r-00000 [hadoop@xufeng-1 temp]$ hadoop fs -cat /wordcountData/output/part-r-00000 16/07/28 18:22:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable aaa 3 bbb 1 ccc 2 ddd 2 eee 2 ggg 2 hhh 1 [hadoop@xufeng-1 temp]$
4. 本地集群模式运行
在eclipse中我们可以直接让程序在集群中运行(如yarn集群)上运行,免去打包等繁琐工作,要想让本地运行的关键需要引入mapred-site.xml 和yarn-site.xml文件
目的是让本地程序知道当前mr是在什么框架下执行的,并且要知道集群的信息。
由于如下原因暂未解决:
Diagnostics: File file:/tmp/hadoop-yarn/staging/apple/.staging/job_1469738198989_0009/job.splitmetainfo does not exist java.io.FileNotFoundException: File file:/tmp/hadoop-yarn/staging/apple/.staging/job_1469738198989_0009/job.splitmetainfo does not exist at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:534) at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:747) at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:524) at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:409)
5. 命令行集群模式运行
这种模式的运行既是将程序打成jar文件后,放到集群环境上去,通过hadoop jar命令来运行,这模式下运行的任务将运行在集群上。
这种模式非常简单,但是需要在run()方法中指定:
job.setJarByClass(WordCountDriver.class);
否则会出现mapper类无法找到的错误。通过这个模式我们无需使用任何配置文件,在eclipse中将程序打包后传上集群主机。使用如下命令即可执行:
hadoop jar wordcount.jar WordCountDriver
运行日志:
16/07/28 22:31:21 INFO mapreduce.Job: map 0% reduce 0% 16/07/28 22:31:28 INFO mapreduce.Job: map 100% reduce 0% 16/07/28 22:31:39 INFO mapreduce.Job: map 100% reduce 100% 16/07/28 22:31:39 INFO mapreduce.Job: Job job_1469738198989_0014 completed successfully 16/07/28 22:31:39 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=188 FILE: Number of bytes written=221659 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=157
查看yarn上的监控web:
![]()
集中模式的介绍完毕。
标签:
原文地址:http://www.cnblogs.com/ios123/p/5769281.html