标签:
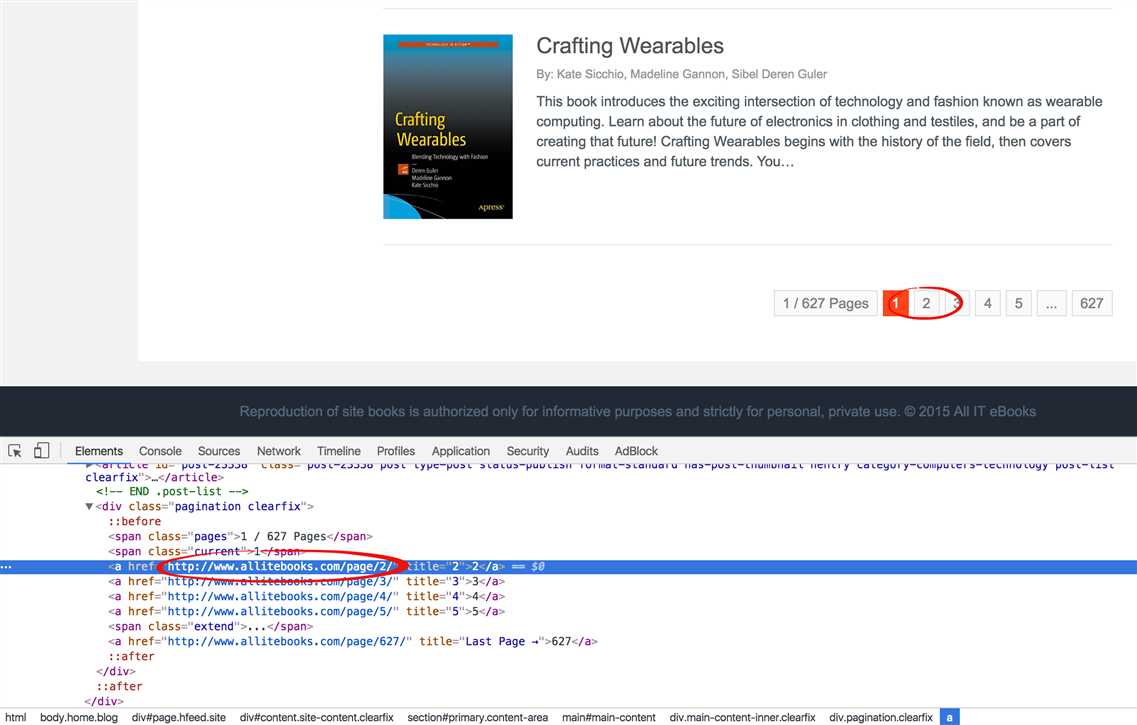
# Get the next page url from the current page url def get_next_page_url(url): page = urlopen(url) soup_page = BeautifulSoup(page, ‘lxml‘) page.close() # Get current page and next page tag current_page_tag = soup_page.find(class_="current") next_page_tag = current_page_tag.find_next_sibling() # Check if the current page is the last one if next_page_tag is None: next_page_url = None else: next_page_url = next_page_tag[‘href‘] return next_page_url
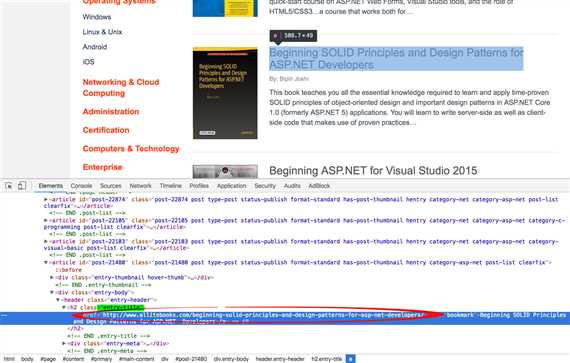
# Get the book detail urls by page url def get_book_detail_urls(url): page = urlopen(url) soup = BeautifulSoup(page, ‘lxml‘) page.close() urls = [] book_header_tags = soup.find_all(class_="entry-title") for book_header_tag in book_header_tags: urls.append(book_header_tag.a[‘href‘]) return urls
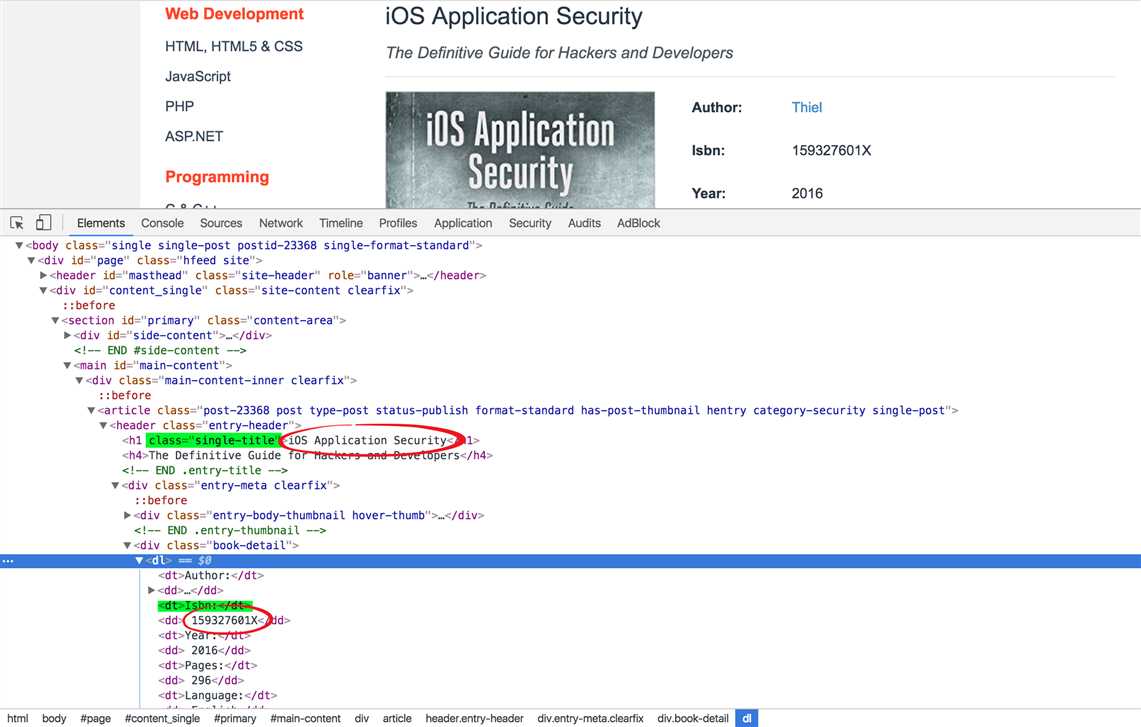
# Get the book detail info by book detail url def get_book_detail_info(url): page = urlopen(url) book_detail_soup = BeautifulSoup(page, ‘lxml‘) page.close() title_tag = book_detail_soup.find(class_="single-title") title = title_tag.string isbn_key_tag = book_detail_soup.find(text="Isbn:").parent isbn_tag = isbn_key_tag.find_next_sibling() isbn = isbn_tag.string.strip() # Remove the whitespace with the strip method return { ‘title‘: title, ‘isbn‘: isbn }
def run(): url = "http://www.allitebooks.com/programming/net/page/1/" book_info_list = [] def scapping(page_url): book_detail_urls = get_book_detail_urls(page_url) for book_detail_url in book_detail_urls: # print(book_detail_url) book_info = get_book_detail_info(book_detail_url) print(book_info) book_info_list.append(book_info) next_page_url = get_next_page_url(page_url) if next_page_url is not None: scapping(next_page_url) else: return scapping(url)
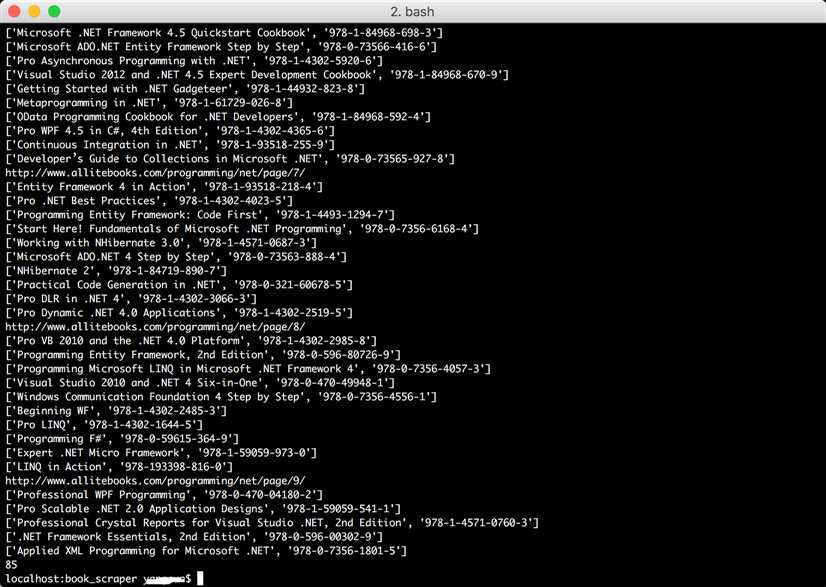
def save_to_csv(list): with open(‘books.csv‘, ‘w‘, newline=‘‘) as fp: a = csv.writer(fp, delimiter=‘,‘) a.writerow([‘title‘,‘isbn‘]) a.writerows(list)
未完待续...
网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
标签:
原文地址:http://www.cnblogs.com/sirkevin/p/5783748.html