标签:
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。 这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
传统的日志分析系统提供了一种离线处理日志信息的可扩展方案,但若要进行实时处理,通常会有较大延迟。而现有的消(队列)系统能够很好的处理实时或者近似实时的应用,但未处理的数据通常不会写到磁盘上,这对于Hadoop之类(一小时或者一天只处理一部分数据)的离线应用而言,可能存在问题。Kafka正是为了解决以上问题而设计的,它能够很好地离线和在线应用。
设计目标:
(1)数据在磁盘上存取代价为O(1)。一般数据在磁盘上是使用BTree存储的,存取代价为O(lgn)。
(2)高吞吐率。即使在普通的节点上每秒钟也能处理成百上千的message。
(3)显式分布式,即所有的producer、broker和consumer都会有多个,均为分布式的。
(4)支持数据并行加载到Hadoop中。
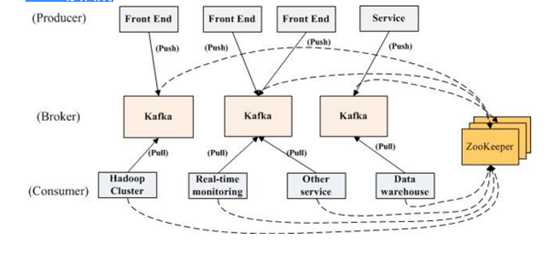
Kafka的部署结构:
首先新建一个目录kafka:

将下载好的软件包kafka_2.9.2-0.8.1.1.tgz放到kafka目录下进行解压:

修改配置文件config/server.properties:
broker.id=0
host.name=10.100.5.9(ip修改为自己主机ip)
zookeeper.connect=10.100.5.9:2181可逗号分隔配置多个(ip修改为自己主机ip)
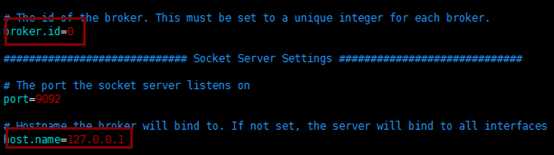

修改完成后保存并退出。
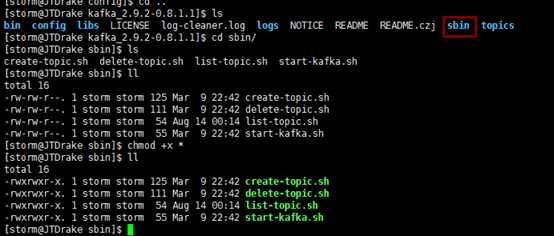
为了确保之后的执行不出现权限问题进入sbin目录下修改该目录下所有文件的权限:
接下来进入config目录下修改配置文件vim log4j.properties:
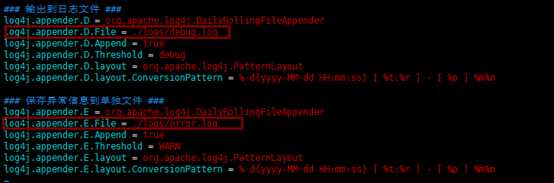
图中2处为你所需存放日志文件的路径。
接下来就可以进入sbin下启动kafka了:
启动完kafka之后我们就可以来创建一个对话:
bin/kafka-topics.sh --create --zookeeper 10.173.48.88:2181 --replication-factor 1 --partitions 1 --topic topic-test-name (IP不能是localhost)

启动consumer:
bin/kafka-console-consumer.sh --zookeeper hadoop-nn:2181 --topic topic-003

启动producer:

此时在producer端输入信息,在consumer中就可以看到:


标签:
原文地址:http://www.cnblogs.com/drake0301/p/5788979.html