标签:
开发反馈做复制的表每隔一段时间会延迟,最大延迟时间超过15分钟。
打开复制监视器,找到发布所对应的订阅,查看是否有错误。在"发布服务器到分发服务器的历史记录"栏发现下图所示信息: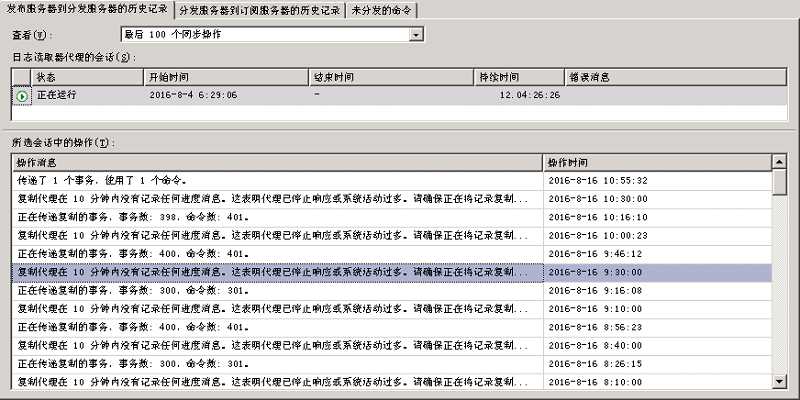
图中我们可以看出上下两条间隔大约15分钟,每条"正在传递复制的事务..."到下一条"复制代理在10分钟内没有记录任何进度消息..."之间,肯定命令没有传递到分发服务器。
至于"错误"消息出现多久后又开始正常传递复制的事务,这个单独从上图是很难界定的。上图最直观的反馈是,正常复制->日志代理异常->正常复制->日志代理异常,如此反复。证实开发所说的问题确实存在。
复制监视器实际上依赖于复制代理来定期报告状态信息。如果该报告未能在一个较长的时间内发送,复制监视器将报告问题。
错误消息只声明复制代理在10分钟内没有记录任何进度消息。这表明代理已停止或系统活动过多。错误消息建议手动检查记录仍然被复制以及网络是连通的。目标数据库检查发现记录没有被复制,检查网络没发现问题。
发布到分发对应的是日志读取器代理,查看相关作业,显示正在执行,历史记录空白。复制监视器中查看对应日志读取器代理状态显示正在运行。发布服务器查看正在执行的请求(dm_exec_requests),寥寥几行。
中间一段时间没有头绪,各种设想,各种置疑。后来请教大菠萝,他给了几个检查步骤:1确定日志读取器代理正在运行;2复制表数据情况,是否间隔性的发生数据变动;3看看ldf所在磁盘的性能(关注Avg. Disk sec/Write),是否有间隔性的性能问题;4看看锁等待;总之,看看有没有和15分钟相关的性能异常。
前面也怀疑存在某个周期性的操作影响到复制,但局限于发布服务器,并且异常间隔时间不固定,没能找出。
第二天,眼瞅着没啥进展。查看复制所有相关作业的历史记录,发现“分发清除:distribution”执行时间有点过长(20分钟左右)。查看作业属性,作业每10分钟执行一次。作业最近几次历史记录如下: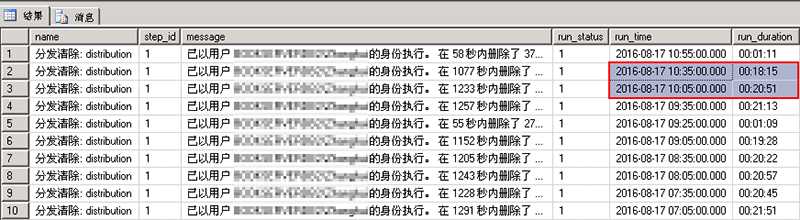
红框部分可以看到作业在2016-08-17 10:05:00.000开始执行,持续20分51秒;也就是从10点05分到10点26分作业一直在执行,而此期间复制命令一直没能传到分发服务器。可以查看分发库中MSrepl_transactions的记录,也可以从订阅端检查没有新数据过去。等作业执行完,它已跨越两次计划执行(15、25分)。2016-08-17 10:25:51.000起作业空闲,复制命令传送,直到下次作业执行(2016-08-17 10:35:00.000)。
2016-08-17 10:05:00.000~2016-08-17 10:25:51.000 分发清除作业执行,复制命令异常
2016-08-17 10:25:51.000~2016-08-17 10:35:00.000 复制命令正常传递
2016-08-17 10:35:00.000~2016-08-17 10:53:15.000 分发清除作业执行,复制命令异常
2016-08-17 10:53:15.000~2016-08-17 10:55:00.000 复制命令正常传递
单独从时间上来看,它和复制监视器中的信息完全吻合。基本上就是分发清除作业开始执行,复制命令异常,作业结束执行,复制命令正常。作业周期性执行,每次执行时长不定,最终我们看到的就是复制命令间隔性的延迟。
如何证明分发清除影响到日志读取器代理?分发清除为什么需要执行这么长时间,主要耗时在哪?
分发清除执行期间,我们查看分发服务器上的阻塞情况:
spid=86被spid=108阻塞,86和108对应的命令如下: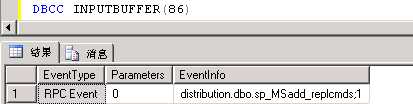

可以看到86是往分发库添加记录,108从分发库删除记录。我们查看它们的锁信息: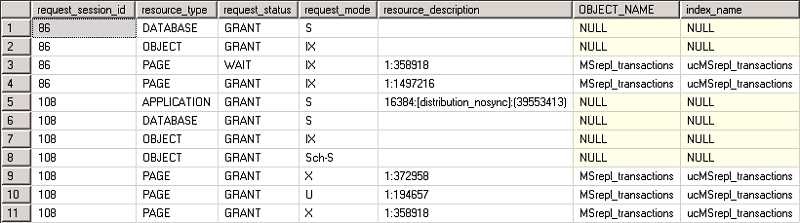
spid=108,对表MSrepl_transactions进行删除操作,在358918页上持有排它锁(X);spid=86,对表MSrepl_transactions进行写入操作,申请在358918页上的意向排它锁(IX);spid=86被spid=108阻塞。
分发清除作业主要耗时在哪个语句?下面是根据ApplicationName列筛选得到的跟踪文件,按照时长降序:
最大消耗在delete TOP(5000) MSrepl_transactions WITH (PAGLOCK) from MSrepl_transactions with (INDEX(ucMSrepl_transactions)) ...
逻辑读取次数(Reads)达到267791916,物理写入次数(Writes)仅有8,可见这个删除效率足够低!
什么原因导到如此低效的删除,表的记录索引情况如何: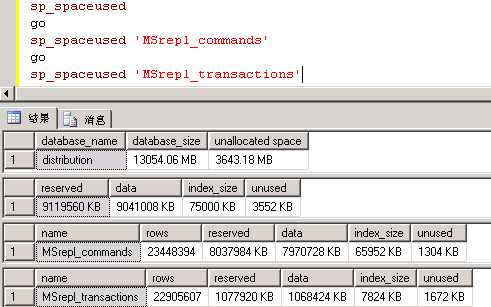
MSrepl_commands和MSrepl_transactions记录数均达到2000+W,几乎占了整个库的全部。这些命令分别对应哪些表呢?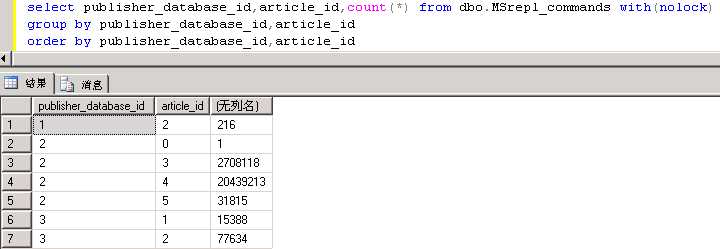
publisher_database_id=2,article_id=4对应的记录为20439213,对应就是复制异常的表。为什么有这么大的数据量?最小分发保持期(0小时),最大分发保持期(72小时)。检查各操作(insert、update、delete)命令数量如何?
上图从sys.dm_exec_cached_plans得到存储过程执行次数,可以看到约30个小时内sp_MSupd_dboAccountsinFo执行了800+万次(72小时约2000万)。也就是大量的命令是对AccountsinFo更新操作。
查看发布,allow_anonymous、immediate_sync属性设置为True。如果immediate_sync为true, snapshot 文件和replicated transaction将一直保留到data retention。然后才会被删除。这会导致distribution 数据库增长,复制性能下降。 所以推荐设置为false。需要注意的时,如果一个数据库有多个publication,只要其中有一个publication的immediate_sync为true,将会导致 这个数据库的所有publication的replicated transaction的保留期都延长至data retention。
最终的解决方案是,禁用allow_anonymous、immediate_sync属性。
总结
个人思路不清晰,考虑问题过于狭隘。感谢大菠萝。
参考
事务复制清除的故障分析https://blogs.msdn.microsoft.com/apgcdsd/2012/09/06/623/
Replication的犄角旮旯(四)--关于事务复制的监控http://www.cnblogs.com/diabloxl/p/3630410.html
SQL SERVER Transactional Replication中添加新表怎么不初始化整个快照http://www.cnblogs.com/kerrycode/p/4266646.html
复制代理JOBhttp://www.cnblogs.com/zerocc/p/3208621.html
distribution数据库过大问题http://www.cnblogs.com/datazhang/p/5106721.html
标签:
原文地址:http://www.cnblogs.com/Uest/p/5788645.html