标签:
本着周末逛贴吧看图片,发现电脑运行内存太小,网页加载太慢,一怒之下写个爬虫把图片都下载到本地慢慢看
得到结果如下:
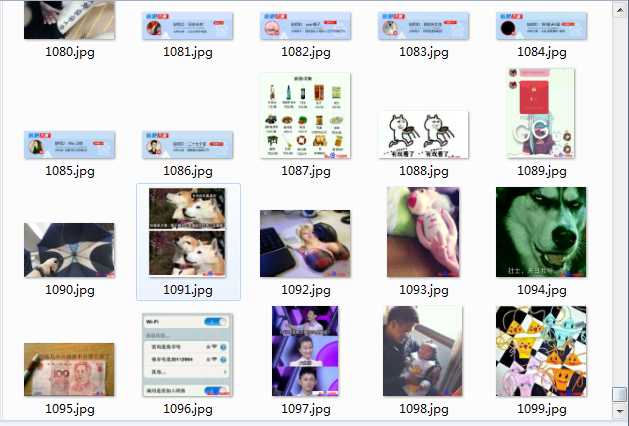
千张内涵图随意浏览
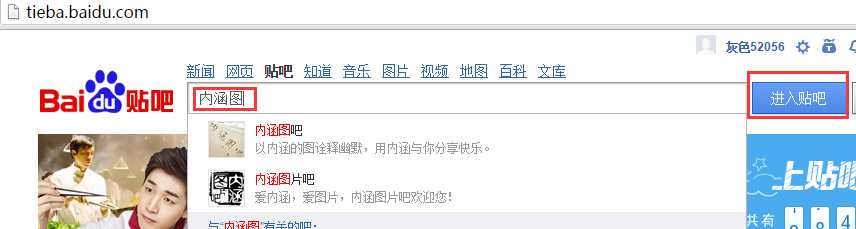
程序第一个选项:

对应的贴吧是:
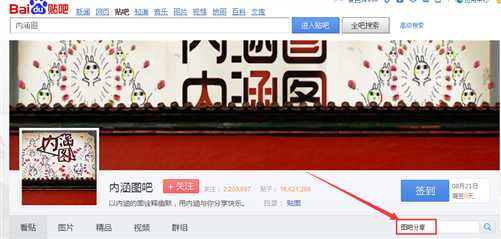
第二个选项:

对应的贴吧是
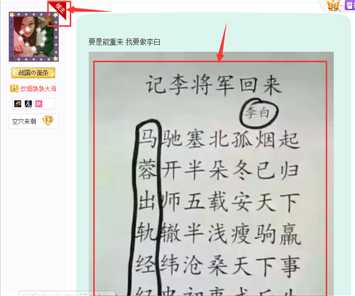
抓取的对象为楼主所发的图片:
好的,开搞:
下面是基于python3写的
通过观察,得到爬虫思路为:
思路
1、搜索什么贴吧kw
2、贴吧内的什么贴qw
3、进入贴吧href="/p/
4、图片<img src="
5、页数pn=
第一步思路是构造网址,观察看到贴吧网址为:
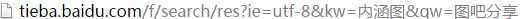
代码为
# 输入的文字转码 kw = input("请输入贴吧:") qw = input("请输入进入的贴:") qw = urllib.parse.quote(qw.encode(‘gbk‘)) kw = urllib.parse.quote(kw.encode(‘gbk‘)) # 抓取的页数 page = input("你要抓取的页数(每页10个贴):") # 构造一级网址 url_1 = "http://tieba.baidu.com/f/search/res?isnew=1&kw=" + str(kw) + "&qw=" + str(qw) + "%ED&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=" + str(page)
第二观察解析的网址
每个网址的子贴吧都包含href="/p/

就写个正则:
1 # 第一次网址匹配 2 def reg_1(html_1): 3 reg = r‘(href="/p/)(.+?)(pid)‘ 4 all = re.compile(reg); 5 alllist = re.findall(all, html_1) 6 return alllist
得到全部的搜索吧的网址了
那么就解析getHtml()
解析后观察发现楼主的图片都有<img src="
再写个正则:
1 # 第二次网址匹配 2 def reg_2(html_2): 3 reg = r‘(<img src=")(.+?g)(" width=)‘ 4 all = re.compile(reg); 5 alllist = re.findall(all, html_2) 6 return alllist
页数的正则也包含:共有....页
那么写个正则:
1 # 贴的页数匹配 2 def reg_page(html_page): 3 reg = r‘(共有.+?)(\d+)(.+?页)‘ 4 all = re.compile(reg); 5 alllist = re.findall(all, html_page) 6 return alllist
思路搞定
爬虫步骤为:
1、先进去得到每一张图片的网址
2、楼主的图片末尾有pic_type,其他人发的没有
3、得到全部图片保存之
4、最后再一起下载
将所有图片的网址保存到一个txt
保存完后再一起下载
这里可以开个线程池
太麻烦不搞了
就直接保存下载
1 # 将image网址写入txt 2 for x in range(0,len(infoarr_2)): 3 save_path = "../imageurl.txt" 4 file_path = open(save_path, ‘w‘) 5 txt = str(txt) + ‘\n‘ + str(infoarr_2[x]) 6 if txt: 7 file_path.write(txt) 8 file_path.close()
我保存在imageurl里面
数组是infoarr_2
注意每一次写入都会清空txt,所以我写成:
txt = str(txt) + ‘\n‘ + str(infoarr_2[x])
最后最后下载
1 file = open(‘../imageurl.txt‘, ‘r‘) 2 data = file.read().split(‘\n‘) 3 imaurl = [] 4 num = 0 5 for y in range(0, len(data)): 6 imaurl.append(data[y]) 7 for imgPath in imaurl: 8 try: 9 # 将图片写入ima文件夹 10 filess = open("../img/" + str(num) + ".jpg", ‘wb‘) 11 filess.write(urllib.request.urlopen(imgPath).read()) 12 filess.close() 13 14 print("正在下载" + imgPath) 15 num = num + 1 16 except Exception as err: 17 print(err) 18 pass
完美解决
看图去
软件已经打包到github
自行下载
https://github.com/TTyb/
标签:
原文地址:http://www.cnblogs.com/TTyb/p/5793059.html