标签:
一、hdfs的设计目标
1.1、硬件错误是常态而不是异常。Hadoop的设计理念之一就是它可以运行在廉价的普通PC机上,因而硬件故障是常态。在硬件故障时,可通过容错机制保证数据的正确性、完整性,从而保证系统的正常运行。
1.2、大文件存储。hdfs存储的文件大小一般在GB~TB的级别。
1.3、流式数据访问。由于hadoop处理的都是大文件,因此流式数据访问方式更适合。流式数据访问是指一次性地读取一大块文件后再做处理,其特点是吞吐率高,延迟高;与之相反的是随机数据访问,特点是随机性地读取数据,延迟低。
1.4、一次写入、多次读取。用户需要对文件实行一次写、多次读的访问模式。文件一旦上传到hdfs,便不能再做修改,如需修改,需删除文件重新上传。在上传完数据之后,便在该数据集上进行长时间的数据分析,也避免了数据一致性的问题。
二、hdfs的缺点
2.1、高延迟。
2.2、不适合存储大量小文件。
三、hdfs的基本架构图
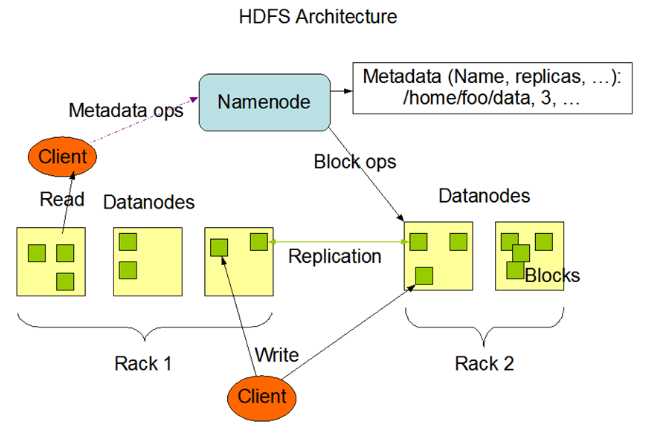
3.1、几个重要概念
(1)NameNode。NameNode负责管理整个dfs文件系统的元数据,即,存储所有的文件目录、每个文件的具体信息(即:每个文件被分了多少块、每块文件的大小及存放位置)等。
(2)DataNode。DataNode负责存放具体数据内容。
(3)其他。Block是数据块,通常以64MB为单位,具有多个冗余副本。Rack表示机柜,一个数据块的多个副本被分散在多个机柜中,以便机柜宕机时,可及时复原数据。
3.2、读数据流程
client在向hdfs读数据时,首先向NameNode发出请求,获取文件的每个数据块的存放位置,然后client再去指定的DataNode读取数据,最后通知NameNode关闭文件。
3.3、写数据流程
client在向hdfs写数据时,首先告知NameNode创建文件,NameNode经过一系列的检查,反馈给client一个DataNode列表进行写数据操作。然后,client再去找特定的DataNode进行写数据,最后关闭文件。
client在写入某一块特定的数据时,要同时备份多份数据块,假设要备份3份,则写数据的流程如下:
client只向第一个DataNode写数据,随后的备份操作由DataNode传递下去,这样做的目的是减小client的读写压力,当备份完最后一块数据时,由最后一块数据所在DataNode向前一个DataNode发送ack确认包,此操作一直传递到client那里,这样,一份数据块的备份操作结束。

四、hadoop2.6中的hdfs的常用命令
hdfs官方命令查询:http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-common/FileSystemShell.html#mkdir
4.1、ls——查看文件列表
hadoop fs -ls /
列出hdfs文件系统根目录下的目录和文件。
hadoop fs -ls -R /
列出hdfs文件系统所有的目录和文件。
hadoop fs -ls /input
列出hdfs文件系统中input目录中的目录和文件。
4.2、put——上传文件到hadoop
hdfs dfs -put localfile /input/file1
将本地文件localfile拷贝到hadoop文件系统的input目录下的file1。
hdfs dfs -put localfile1 localfile2 /input
将本地文件localfile1、localfile2拷贝到hadoop文件系统的input目录下。
4.3、get——下载文件到本地
hdfs dfs -get /input/file localfile
将hfds文件系统input目录下的file文件拷贝到本地localfile文件中。
4.4、mkdir——创建目录
hadoop fs -mkdir /input
在hdfs文件系统的根目录下创建input文件夹。该方式只能一级一级地创建目录,父目录必须存在。
hadoop fs -mkdir -p /dir1/dir2
递归创建目录,如果父目录不存在就创建该父目录。
4.5、rm——删除文件、文件夹
hdfs dfs -rm /input/file1
删除文件。
hdfs dfs -rm -R /input
或: hdfs dfs -rm -r /input
删除文件夹。
4.6、cp——复制文件
hdfs dfs -cp /input/file1 /input/file2
重命名文件,file1、file2都会存在。
hdfs dfs -cp /input/file1 /another/file2
不同目录下拷贝文件。
hdfs dfs -cp /input/file1 /input/file2 /another
拷贝多个文件到another目录下。
4.7、mv——移动文件
hdfs dfs -mv /input/file1 /another/file2
不同目录下移动文件。
hdfs dfs -mv /input/file1 /input/file2 /another
移动多个文件到another目录下。
4.8、cat——打印文件内容
hdfs dfs -cat /input/file1
打印/input/file1文件的内容。
4.9、查看hdfs系统状态
hdfs dfsadmin -report
查看hdfs文件系统的基本信息:存储空间使用情况、datanode节点信息等。
标签:
原文地址:http://www.cnblogs.com/yuan2016/p/5789436.html