标签:
下图是大概步骤:

下面是详细步骤,但我的代码跟上面有点不一样,但都是一个道理:
第一个程序测试 wordcount
先创建目录
hadoop fs -mkdir /wc
hadoop fs -mkdir /wc/input
把要统计的文件放入目录
hadoop fs -put /opt/modules/hadoop-1.2.1 /conf/*.xml /wc/input
运行程序
hadoop jar hadoop-examples-1.2.1.jar wordcount /wc/input /wc/output
然后可看到运行情况。
然后可通过浏览器查看相关信息
http://hadoop-master.dragon.org:50030的Running Jobs(运行完后看
Completed Jobs)
http://hadoop-master.dragon.org:50070的Browse the filesystem查看文件信息,当然也可通过命令查看,
如hadoop fs -text /wc/output/part-r-00000
下图是图解:
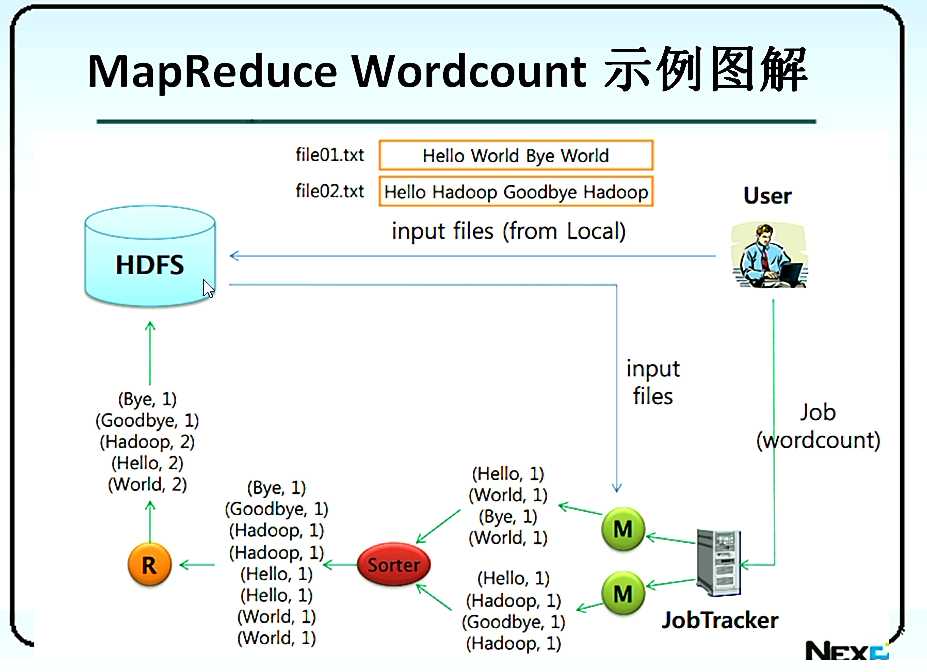
简单说下原理,就是把多个文件分别统计,然后排序并合在一起,然后再统计。
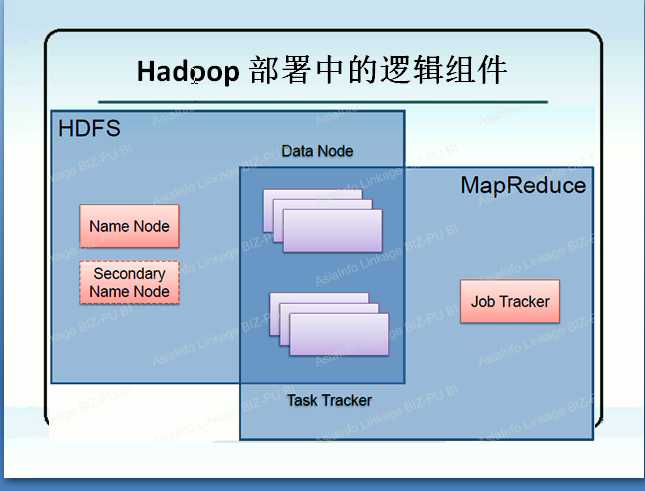
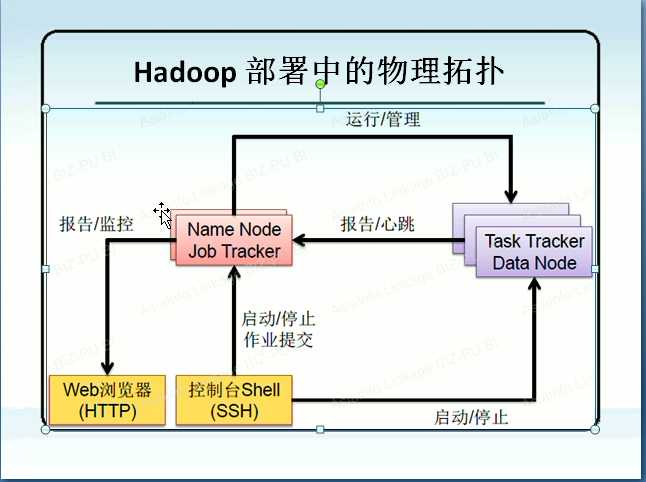
附:
标签:
原文地址:http://www.cnblogs.com/wanghuaijun/p/5800336.html