标签:
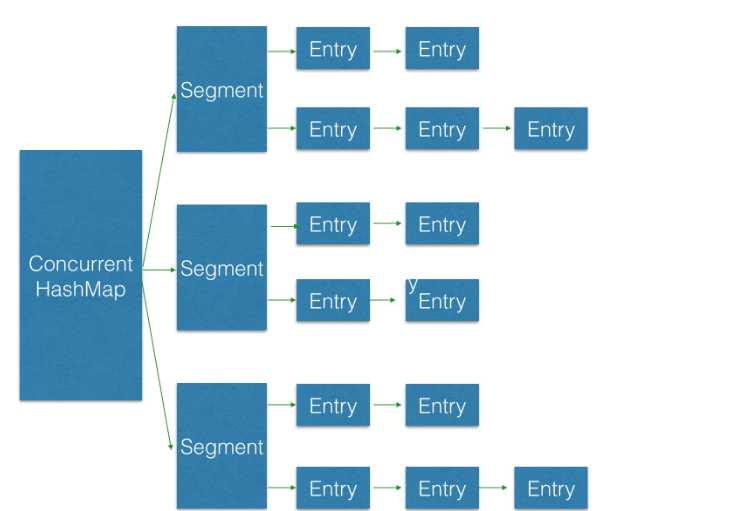
ConcurrentHashMap结构图如下:
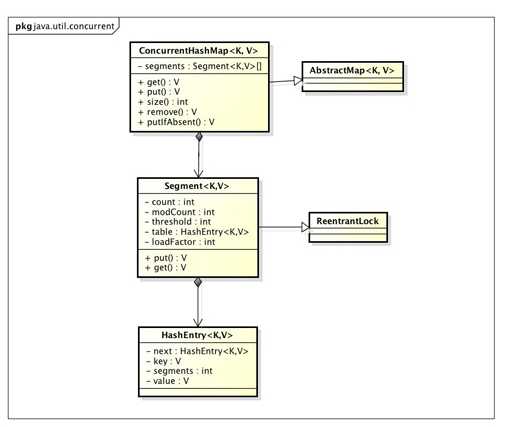
ConcurrentHashMap实现类图如下:
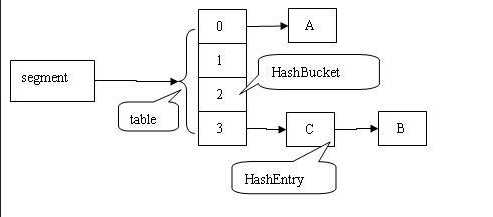
segment的结构图如下:
package concurrentMy.juc_collections.hashMap; import java.io.IOException; import java.io.ObjectInputStream; import java.io.Serializable; import java.util.AbstractCollection; import java.util.AbstractMap; import java.util.AbstractSet; import java.util.Collection; import java.util.ConcurrentModificationException; import java.util.Enumeration; import java.util.HashMap; import java.util.Hashtable; import java.util.Iterator; import java.util.Map; import java.util.NoSuchElementException; import java.util.Set; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap; /** * * (ConcurrentHashMap 原理理解) * * <p> * 修改历史: <br> * 修改日期 修改人员 版本 修改内容<br> * -------------------------------------------------<br> * 2016年8月5日 下午3:37:13 user 1.0 初始化创建<br> * </p> * * @author Peng.Li * @version 1.0 * @since JDK1.7 * * * * * * 0.HashMap是非线程安全的哈希表,常用于单线程程序中。 * * 1.HashTable容器在激烈的并发环境下面效率低的原因:强一致性 * (1)HashTable通过synchronized来保证线程安全的,当一个线程进行put到HashTable添加元素时,线程2不但不能put方法添加元素,也不能通过get获取元素。 * (2) 访问HashTable的线程都必须竞争同一把锁 * 2.ConcurrentHashMap效率高的原因:弱一致性 * (1)容器中有多把锁,每一把锁锁住的是容器中的一部分数据,当多个线程访问容器中的不同的数据段的时候,由于获取的是不同的锁, * 所以不存在竞争的问题,从而提高并发访问效率。 * (2)采用锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配置一把锁,当一个线程占有锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。 * (3)多线程对于同一个段数据的访问,是互斥的;但是对于不同片段的访问,却是可以同步进行的。 * 3.结构原理 * (1)ConcurrentHashMap是由Segment数组接口和HashEntry数组结构组成。 * Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap扮演锁的角色; * HashEntry用于存储键值对数据。 * (2) Segment的结构和HashMap类似,是一组数组和链表结构。一个Segment包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, * 每个Segment守护者一个HashEntry数组里面的元素,当对HashEntry的数组进行修改的时候,首先需要获得HashEntry数组对应的数据段的Segment锁。 * * (3) 读不加锁:定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值), * 在get操作里只需要读写 transient volatile HashEntry<K,V>[] table;所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则, * 对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。 * * (4) 从图中可以看到,ConcurrentHashMap内部分为很多个Segment,每一个Segment拥有一把锁,然后每个Segment(继承ReentrantLock)下面包含很多个HashEntry列表数组。对于一个key, 需要经过三次(为什么要hash三次下文会详细讲解)hash操作,才能最终定位这个元素的位置,这三次hash分别为: 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key); 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment; 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在哪个HashEntry。 * * Written by Doug Lea with assistance from members of JCP JSR-166 * Expert Group and released to the public domain, as explained at * http://creativecommons.org/publicdomain/zero/1.0/ */ import java.util.concurrent.locks.ReentrantLock; /** * A hash table supporting full concurrency of retrievals and * adjustable expected concurrency for updates. This class obeys the * same functional specification as {@link java.util.Hashtable}, and * includes versions of methods corresponding to each method of * <tt>Hashtable</tt>. However, even though all operations are * thread-safe, retrieval operations do <em>not</em> entail locking, * and there is <em>not</em> any support for locking the entire table * in a way that prevents all access. This class is fully * interoperable with <tt>Hashtable</tt> in programs that rely on its * thread safety but not on its synchronization details. * * <p> Retrieval operations (including <tt>get</tt>) generally do not * block, so may overlap with update operations (including * <tt>put</tt> and <tt>remove</tt>). Retrievals reflect the results * of the most recently <em>completed</em> update operations holding * upon their onset. For aggregate operations such as <tt>putAll</tt> * and <tt>clear</tt>, concurrent retrievals may reflect insertion or * removal of only some entries. Similarly, Iterators and * Enumerations return elements reflecting the state of the hash table * at some point at or since the creation of the iterator/enumeration. * They do <em>not</em> throw {@link ConcurrentModificationException}. * However, iterators are designed to be used by only one thread at a time. * * <p> The allowed concurrency among update operations is guided by * the optional <tt>concurrencyLevel</tt> constructor argument * (default <tt>16</tt>), which is used as a hint for internal sizing. The * table is internally partitioned to try to permit the indicated * number of concurrent updates without contention. Because placement * in hash tables is essentially random, the actual concurrency will * vary. Ideally, you should choose a value to accommodate as many * threads as will ever concurrently modify the table. Using a * significantly higher value than you need can waste space and time, * and a significantly lower value can lead to thread contention. But * overestimates and underestimates within an order of magnitude do * not usually have much noticeable impact. A value of one is * appropriate when it is known that only one thread will modify and * all others will only read. Also, resizing this or any other kind of * hash table is a relatively slow operation, so, when possible, it is * a good idea to provide estimates of expected table sizes in * constructors. * * <p>This class and its views and iterators implement all of the * <em>optional</em> methods of the {@link Map} and {@link Iterator} * interfaces. * * <p> Like {@link Hashtable} but unlike {@link HashMap}, this class * does <em>not</em> allow <tt>null</tt> to be used as a key or value. * * <p>This class is a member of the * <a href="{@docRoot}/../technotes/guides/collections/index.html"> * Java Collections Framework</a>. * * @since 1.5 * @author Doug Lea * @param <K> the type of keys maintained by this map * @param <V> the type of mapped values */ public class ConcurrentHashMapSourceCode<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable { private static final long serialVersionUID = 7249069246763182397L; /* * The basic strategy is to subdivide the table among Segments, * each of which itself is a concurrently readable hash table. To * reduce footprint, all but one segments are constructed only * when first needed (see ensureSegment). To maintain visibility * in the presence of lazy construction, accesses to segments as * well as elements of segment‘s table must use volatile access, * which is done via Unsafe within methods segmentAt etc * below. These provide the functionality of AtomicReferenceArrays * but reduce the levels of indirection. Additionally, * volatile-writes of table elements and entry "next" fields * within locked operations use the cheaper "lazySet" forms of * writes (via putOrderedObject) because these writes are always * followed by lock releases that maintain sequential consistency * of table updates. * * Historical note: The previous version of this class relied * heavily on "final" fields, which avoided some volatile reads at * the expense of a large initial footprint. Some remnants of * that design (including forced construction of segment 0) exist * to ensure serialization compatibility. */ /* ---------------- Constants -------------- */ /** * The default initial capacity for this table, * used when not otherwise specified in a constructor. */ static final int DEFAULT_INITIAL_CAPACITY = 16; /** * The default load factor for this table, used when not * otherwise specified in a constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f; /** * The default concurrency level for this table, used when not * otherwise specified in a constructor. */ static final int DEFAULT_CONCURRENCY_LEVEL = 16; /** * The maximum capacity, used if a higher value is implicitly * specified by either of the constructors with arguments. MUST * be a power of two <= 1<<30 to ensure that entries are indexable * using ints. */ static final int MAXIMUM_CAPACITY = 1 << 30; /** * The minimum capacity for per-segment tables. Must be a power * of two, at least two to avoid immediate resizing on next use * after lazy construction. */ static final int MIN_SEGMENT_TABLE_CAPACITY = 2; /** * The maximum number of segments to allow; used to bound * constructor arguments. Must be power of two less than 1 << 24. */ static final int MAX_SEGMENTS = 1 << 16; // slightly conservative /** * Number of unsynchronized retries in size and containsValue * methods before resorting to locking. This is used to avoid * unbounded(不受限制的) retries if tables undergo (经受)continuous(连续的) modification * which would make it impossible to obtain an accurate result. */ static final int RETRIES_BEFORE_LOCK = 2; /* ---------------- Fields -------------- */ /** * holds values which can‘t be initialized until after VM is booted. */ private static class Holder { /** * Enable alternative hashing of String keys? * * <p>Unlike the other hash map implementations we do not implement a * threshold for regulating whether alternative hashing is used for * String keys. Alternative hashing is either enabled for all instances * or disabled for all instances. */ static final boolean ALTERNATIVE_HASHING; static { // Use the "threshold" system property even though our threshold // behaviour is "ON" or "OFF". String altThreshold = java.security.AccessController.doPrivileged( new sun.security.action.GetPropertyAction( "jdk.map.althashing.threshold")); int threshold; try { threshold = (null != altThreshold) ? Integer.parseInt(altThreshold) : Integer.MAX_VALUE; // disable alternative hashing if -1 if (threshold == -1) { threshold = Integer.MAX_VALUE; } if (threshold < 0) { throw new IllegalArgumentException("value must be positive integer."); } } catch(IllegalArgumentException failed) { throw new Error("Illegal value for ‘jdk.map.althashing.threshold‘", failed); } ALTERNATIVE_HASHING = threshold <= MAXIMUM_CAPACITY; } } /** * A randomizing value associated with this instance that is applied to * hash code of keys to make hash collisions harder to find. */ private transient final int hashSeed = randomHashSeed(this); private static int randomHashSeed(ConcurrentHashMapSourceCode instance) { if (sun.misc.VM.isBooted() && Holder.ALTERNATIVE_HASHING) { return sun.misc.Hashing.randomHashSeed(instance); } return 0; } /** * Mask value for indexing into segments. The upper bits of a * key‘s hash code are used to choose the segment. */ final int segmentMask; /** * Shift value for indexing within segments. */ final int segmentShift; /** * The segments, each of which is a specialized hash table. */ final Segment<K,V>[] segments; transient Set<K> keySet; transient Set<Map.Entry<K,V>> entrySet; transient Collection<V> values; /** * ConcurrentHashMap list entry. Note that this is never exported * out as a user-visible Map.Entry. */ static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; HashEntry(int hash, K key, V value, HashEntry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } /** * Sets next field with volatile write semantics. (See above * about use of putOrderedObject.) */ final void setNext(HashEntry<K,V> n) { UNSAFE.putOrderedObject(this, nextOffset, n); } // Unsafe mechanics static final sun.misc.Unsafe UNSAFE; static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class k = HashEntry.class; nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } } /** * Gets the ith element of given table (if nonnull) with volatile * read semantics. Note: This is manually integrated into a few * performance-sensitive methods to reduce call overhead. */ @SuppressWarnings("unchecked") static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) { return (tab == null) ? null : (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)i << TSHIFT) + TBASE); } /** * Sets the ith element of given table, with volatile write * semantics. (See above about use of putOrderedObject.) */ static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i, HashEntry<K,V> e) { UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e); } /** * Applies a supplemental(补充的,追加的) hash function to a given hashCode, which * defends against (对抗) poor quality (质量差的) hash functions. This is critical(爱挑剔的) * because ConcurrentHashMap uses power-of-two length hash tables, * that otherwise encounter(遭遇) collisions(hash碰撞) for hashCodes that do not * differ in lower or upper bits. * * 用到了Wang/Jenkins算法变种,主要的目的为了减少hash冲突,使元素能够均匀的分布到不同的Segment上,从而提高容器的存取的效率。 * 假如哈希的质量差到极点,所有的元素都在同一个Segment中,不仅存取缓慢,分段锁也会失去意义。 * * System.out.println(Integer.parseInt("0001111", 2) & 15); System.out.println(Integer.parseInt("0011111", 2) & 15); System.out.println(Integer.parseInt("0111111", 2) & 15); System.out.println(Integer.parseInt("1111111", 2) & 15); 上面的结果全都是15,通过这个例子发现如果不进行再hash,hash冲突非常严重,因为只要低位一样,无论高位是什么,与15做&操作都为15。 发生冲突的几率还是很大的,但是如果我们先把上例中的二进制数字使用hash()函数先进行一次预hash,得到的结果是这样的: 0100|0111|0110|0111|1101|1010|0100|1110 1111|0111|0100|0011|0000|0001|1011|1000 0111|0111|0110|1001|0100|0110|0011|1110 1000|0011|0000|0000|1100|1000|0001|1010 可以看到每一位的数据都散开了,并且ConcurrentHashMap中是使用预hash值的高位参与运算的。比如之前说的先将hash值向右按位移动28位, 再与15做&运算,得到的结果都别为:4,15,7,8,没有冲突! */ public int hash(Object k) { int h = hashSeed; if ((0 != h) && (k instanceof String)) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // Spread bits to regularize(调整;使合法化) both segment and index locations(位置,地点), // using variant(不同的) of single-word Wang/Jenkins hash. h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); } /** * Segments are specialized versions of hash tables. This * subclasses from ReentrantLock opportunistically, just to * simplify some locking and avoid separate construction. */ static final class Segment<K,V> extends ReentrantLock implements Serializable { /* * Segments maintain a table of entry lists that are always * kept in a consistent state, so can be read (via volatile * reads of segments and tables) without locking. This * requires replicating nodes when necessary during table * resizing, so the old lists can be traversed by readers * still using old version of table. * * This class defines only mutative methods requiring locking. * Except as noted, the methods of this class perform the * per-segment versions of ConcurrentHashMap methods. (Other * methods are integrated directly into ConcurrentHashMap * methods.) These mutative methods use a form of controlled * spinning on contention via methods scanAndLock and * scanAndLockForPut. These intersperse tryLocks with * traversals to locate nodes. The main benefit is to absorb * cache misses (which are very common for hash tables) while * obtaining locks so that traversal is faster once * acquired. We do not actually use the found nodes since they * must be re-acquired under lock anyway to ensure sequential * consistency of updates (and in any case may be undetectably * stale), but they will normally be much faster to re-locate. * Also, scanAndLockForPut speculatively creates a fresh node * to use in put if no node is found. */ private static final long serialVersionUID = 2249069246763182397L; /** * The maximum number of times to tryLock in a prescan before * possibly blocking on acquire in preparation for a locked * segment operation. On multiprocessors, using a bounded * number of retries maintains cache acquired while locating * nodes. */ static final int MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; /** * The per-segment table. Elements are accessed via * entryAt/setEntryAt providing volatile semantics. */ transient volatile HashEntry<K,V>[] table; /** * The number of elements. Accessed only either within locks * or among other volatile reads that maintain visibility. */ transient int count; /** * The total number of mutative operations in this segment. * Even though this may overflows 32 bits, it provides * sufficient accuracy for stability checks in CHM isEmpty() * and size() methods. Accessed only either within locks or * among other volatile reads that maintain visibility. */ transient int modCount; /** * The table is rehashed when its size exceeds this threshold. * (The value of this field is always <tt>(int)(capacity * * loadFactor)</tt>.) */ transient int threshold; /** * The load factor for the hash table. Even though this value * is same for all segments, it is replicated to avoid needing * links to outer object. * @serial */ final float loadFactor; Segment(float lf, int threshold, HashEntry<K,V>[] tab) { this.loadFactor = lf; this.threshold = threshold; this.table = tab; } final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; } /** * Doubles size of table and repacks entries, also adding the * given node to new table */ @SuppressWarnings("unchecked") private void rehash(HashEntry<K,V> node) { /* * Reclassify nodes in each list to new table. Because we * are using power-of-two expansion, the elements from * each bin must either stay at same index, or move with a * power of two offset. We eliminate unnecessary node * creation by catching cases where old nodes can be * reused because their next fields won‘t change. * Statistically, at the default threshold, only about * one-sixth of them need cloning when a table * doubles. The nodes they replace will be garbage * collectable as soon as they are no longer referenced by * any reader thread that may be in the midst of * concurrently traversing table. Entry accesses use plain * array indexing because they are followed by volatile * table write. */ HashEntry<K,V>[] oldTable = table; int oldCapacity = oldTable.length; int newCapacity = oldCapacity << 1; threshold = (int)(newCapacity * loadFactor); HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity]; int sizeMask = newCapacity - 1; for (int i = 0; i < oldCapacity ; i++) { HashEntry<K,V> e = oldTable[i]; if (e != null) { HashEntry<K,V> next = e.next; int idx = e.hash & sizeMask; if (next == null) // Single node on list newTable[idx] = e; else { // Reuse consecutive sequence at same slot HashEntry<K,V> lastRun = e; int lastIdx = idx; for (HashEntry<K,V> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; // Clone remaining nodes for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = new HashEntry<K,V>(h, p.key, v, n); } } } } int nodeIndex = node.hash & sizeMask; // add the new node node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; } /** * Scans for a node containing given key while trying to * acquire lock, creating and returning one if not found. Upon * return, guarantees that lock is held. UNlike in most * methods, calls to method equals are not screened: Since * traversal speed doesn‘t matter, we might as well help warm * up the associated code and accesses as well. * * @return a new node if key not found, else null */ private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { HashEntry<K,V> first = entryForHash(this, hash); HashEntry<K,V> e = first; HashEntry<K,V> node = null; int retries = -1; // negative while locating node while (!tryLock()) { HashEntry<K,V> f; // to recheck first below if (retries < 0) { if (e == null) { if (node == null) // speculatively create node node = new HashEntry<K,V>(hash, key, value, null); retries = 0; } else if (key.equals(e.key)) retries = 0; else e = e.next; } else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; // re-traverse if entry changed retries = -1; } } return node; } /** * Scans for a node containing the given key while trying to * acquire lock for a remove or replace operation. Upon * return, guarantees that lock is held. Note that we must * lock even if the key is not found, to ensure sequential * consistency of updates. */ private void scanAndLock(Object key, int hash) { // similar to but simpler than scanAndLockForPut HashEntry<K,V> first = entryForHash(this, hash); HashEntry<K,V> e = first; int retries = -1; while (!tryLock()) { HashEntry<K,V> f; if (retries < 0) { if (e == null || key.equals(e.key)) retries = 0; else e = e.next; } else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; retries = -1; } } } /** * Remove; match on key only if value null, else match both. */ final V remove(Object key, int hash, Object value) { if (!tryLock()) scanAndLock(key, hash); V oldValue = null; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> e = entryAt(tab, index); HashEntry<K,V> pred = null; while (e != null) { K k; HashEntry<K,V> next = e.next; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { V v = e.value; if (value == null || value == v || value.equals(v)) { if (pred == null) setEntryAt(tab, index, next); else pred.setNext(next); ++modCount; --count; oldValue = v; } break; } pred = e; e = next; } } finally { unlock(); } return oldValue; } final boolean replace(K key, int hash, V oldValue, V newValue) { if (!tryLock()) scanAndLock(key, hash); boolean replaced = false; try { HashEntry<K,V> e; for (e = entryForHash(this, hash); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { if (oldValue.equals(e.value)) { e.value = newValue; ++modCount; replaced = true; } break; } } } finally { unlock(); } return replaced; } final V replace(K key, int hash, V value) { if (!tryLock()) scanAndLock(key, hash); V oldValue = null; try { HashEntry<K,V> e; for (e = entryForHash(this, hash); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; e.value = value; ++modCount; break; } } } finally { unlock(); } return oldValue; } final void clear() { lock(); try { HashEntry<K,V>[] tab = table; for (int i = 0; i < tab.length ; i++) setEntryAt(tab, i, null); ++modCount; count = 0; } finally { unlock(); } } } // Accessing segments /** * Gets the jth element of given segment array (if nonnull) with * volatile element access semantics via Unsafe. (The null check * can trigger harmlessly only during deserialization.) Note: * because each element of segments array is set only once (using * fully ordered writes), some performance-sensitive methods rely * on this method only as a recheck upon null reads. */ @SuppressWarnings("unchecked") static final <K,V> Segment<K,V> segmentAt(Segment<K,V>[] ss, int j) { long u = (j << SSHIFT) + SBASE; return ss == null ? null : (Segment<K,V>) UNSAFE.getObjectVolatile(ss, u); } /** * Returns the segment for the given index, creating it and * recording in segment table (via CAS) if not already present. * * @param k the index * @return the segment */ @SuppressWarnings("unchecked") private Segment<K,V> ensureSegment(int k) { final Segment<K,V>[] ss = this.segments; long u = (k << SSHIFT) + SBASE; // raw offset Segment<K,V> seg; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { Segment<K,V> proto = ss[0]; // use segment 0 as prototype int cap = proto.table.length; float lf = proto.loadFactor; int threshold = (int)(cap * lf); HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; } // Hash-based segment and entry accesses /** * Get the segment for the given hash */ @SuppressWarnings("unchecked") private Segment<K,V> segmentForHash(int h) { long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u); } /** * Gets the table entry for the given segment and hash */ @SuppressWarnings("unchecked") static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) { HashEntry<K,V>[] tab; return (seg == null || (tab = seg.table) == null) ? null : (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); } /* ---------------- Public operations -------------- */ /** * Creates a new, empty map with the specified initial * capacity, load factor and concurrency level. * * @param initialCapacity the initial capacity. The implementation * performs internal sizing to accommodate this many elements. * @param loadFactor the load factor threshold, used to control resizing. * Resizing may be performed when the average number of elements per * bin exceeds this threshold. * @param concurrencyLevel the estimated number of concurrently * updating threads. The implementation performs internal sizing * to try to accommodate this many threads. * @throws IllegalArgumentException if the initial capacity is * negative or the load factor or concurrencyLevel are * nonpositive. * * 实现原理: * ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候, * 其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图: * * 1.initialCapacity 表示新建的这个ConcurrentHashMap的初始容量,也就是上线结构图中的Entry数量。 * 默认值为static final int DEFAULT_INITIAL_CAPACITY = 16; * * 2.loadFactor表示负载因子,就是当ConcurrentHashMap中的元素个数大于loadFactor * 最大容量时候就需要rehash和扩容。 * 默认值为static final float DEFAULT_LOAD_FACTOR = 0.75f; * * 3.concurrencyLevel表示并发级别,这个值用来确定segment的个数,segment的个数大于等于concurrencyLevel的第一个2的n次方的数。 * 比如,如果concurrencyLevel为12,13,14,15,16,则Segment的数目为16(2的4次方)。 * * 4.理想情况下ConcurrentHashMap真正的访问量能够达到concurrencyLevel,因为有concurrencyLevel个Segment, * 假如有concurrencyLevel个线程要访问Map,并且需要访问的数据都恰好分别落在不同的segment中,则这些线程能够无竞 * 争的自由访问(因为不需要竞争同一把锁)达到同时访问的效果。这也是这个concurrencyLevel参数为什么起名为“并发级别”的原因。 * * */ @SuppressWarnings("unchecked") public ConcurrentHashMapSourceCode(int initialCapacity, float loadFactor, int concurrencyLevel) { //1.验证参数的合法性,如果不合法,直接抛出异常 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); //2.concurrencyLevel也就是Segment的个数不能超过最大Segment的个数,最大个数MAX_SEGMENTS默认值为 2 << 16,如果超过这个值,设置这个值。 if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments //比如concurrencyLevel=16默认值,则ssize也会等于16(2的4次方,sshift=4),如果concurrencyLevel=18,则ssize=32(也就是2的5次方,sshift=5), //3.这段代码的使用循环找到>=concurrencyLevel的第一个2的n次方的数ssize,这个数ssize就是Segment数组的大小;并记录一共向左按位移动的次数sshift。 int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { //sshift记录ssize向左移动的次数 ++sshift; //ssize就是Segment数组的大小 ssize <<= 1; } //segmentShift 默认的情况下为28 this.segmentShift = 32 - sshift; //segmentMask 默认情况下为15,segmentMask的各个二进制位都为1,目的是之后可以通过key的hash值与这个值做&运算确定Segment的索引。 this.segmentMask = ssize - 1; //4 检查给的容量值是否大于允许的最大容量,如果大于MAXIMUM_CAPACITY,就设置为该值。initialCapacity默认值也为16。static final int MAXIMUM_CAPACITY = 1 << 30; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //5 计算每个Segment平均应该放置多少元素,这个值c是向上取整的值。比如初始容量initialCapacity=15,Segment数组的大小为16,Segment的个数为4,则每个Segment平均需要放置4个元素。 int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; //6 创建一个Segment的实例,将其当做Segment数组的第一个元素。 // create segments and segments[0],cap * loadFactor = 1.5,cap=2 Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); // ssize默认=16,表示Segment数组的大小 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; } /** * Creates a new, empty map with the specified initial capacity * and load factor and with the default concurrencyLevel (16). * * @param initialCapacity The implementation performs internal * sizing to accommodate this many elements. * @param loadFactor the load factor threshold, used to control resizing. * Resizing may be performed when the average number of elements per * bin exceeds this threshold. * @throws IllegalArgumentException if the initial capacity of * elements is negative or the load factor is nonpositive * * @since 1.6 */ public ConcurrentHashMapSourceCode(int initialCapacity, float loadFactor) { this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL); } /** * Creates a new, empty map with the specified initial capacity, * and with default load factor (0.75) and concurrencyLevel (16). * * @param initialCapacity the initial capacity. The implementation * performs internal sizing to accommodate this many elements. * @throws IllegalArgumentException if the initial capacity of * elements is negative. */ public ConcurrentHashMapSourceCode(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); } /** * Creates a new, empty map with a default initial capacity (16), * load factor (0.75) and concurrencyLevel (16). */ public ConcurrentHashMapSourceCode() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); } /** * Creates a new map with the same mappings as the given map. * The map is created with a capacity of 1.5 times the number * of mappings in the given map or 16 (whichever is greater), * and a default load factor (0.75) and concurrencyLevel (16). * * @param m the map */ public ConcurrentHashMapSourceCode(Map<? extends K, ? extends V> m) { this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); putAll(m); } /** * Returns <tt>true</tt> if this map contains no key-value mappings. * * @return <tt>true</tt> if this map contains no key-value mappings */ public boolean isEmpty() { /* * Sum per-segment modCounts to avoid mis-reporting when * elements are concurrently added and removed in one segment * while checking another, in which case the table was never * actually empty at any point. (The sum ensures accuracy up * through at least 1<<31 per-segment modifications before * recheck.) Methods size() and containsValue() use similar * constructions for stability checks. */ long sum = 0L; final Segment<K,V>[] segments = this.segments; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { if (seg.count != 0) return false; sum += seg.modCount; } } if (sum != 0L) { // recheck unless no modifications for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { if (seg.count != 0) return false; sum -= seg.modCount; } } if (sum != 0L) return false; } return true; } /** * Returns the number of key-value mappings in this map. If the * map contains more than <tt>Integer.MAX_VALUE</tt> elements, returns * <tt>Integer.MAX_VALUE</tt>. * * @return the number of key-value mappings in this map * *1. size 操作和put与get的区别在于,size操作需要遍历所有的segment才能算出整个map的大小,而put和get操作只需要关心一个segment; *2. 假设我们当前遍历的Segment为SA,那么在遍历SA过程中,其他的Segment比如SB可能会被修改,那么这一次计算出来的size值并不是Map的当前真正大小。 * 所以一个比较简单的办法是就是计算Map大小的时候所有的segment都lock住,不能更新数据(put 和 remove,计算完之后unlock; * *3. 作者Doug Lea 想出一个更好的idea:先给3次机会(retries初始化为-1,一直重试到RETRIES_BEFORE_LOCK值为2 ,不锁定lock所有Segment; * 遍历所有的segment,累加各个segment的大小得到整个Map的大小。 * *4.如果某相邻的2次计算获取的所有Segment的所有更新次数(每个Segment都有一个变量modCount变量,这个变量在Segment的Entry被修改的时候会加1 * 通过这个值可以得到每个Segment的更新操作的次数)是一样的,说明在计算的过程中没有更新操作,直接结束循环,返回当前的size; * * 5. 如果重试3次计算的结果中,Map的更新次数和前一次不一致,则之后的计算先对所有的Segment加锁,遍历所有segment计算map的大小,最后当重试计算>3次后再解锁所有的 * segment。 * * 6.例子: * * 假如一个Map有4个segment,标记S1,S2,S3,S4,现在我们要获取Map的Size; * 计算过程是这样的: * 第一次计算不对segment S1,S2,S3,S4加锁,遍历所有的segment,假设这次每个segment的大小变成了1,2,3,4;更新次数分别为2,2,3,1;则这次计算可以得到Map的总大小为1+2+3+4=10,总更新次数modCount=2+2+3+1=8; * 第二次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设这次每个segment的大小变成了2,2,3,4;更新次数变为了3,2,3,1; 则Map的size=2+2+3+4=11;modCount=9 * 那么第一次和第二次计算得到的更新次数不一致,第一次是8,第二次是9;则可以判定这段时间Map的数据被更新;因此必须进行第3次重试计算; * 第三次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设每个Segment的更新次数还是为3,2,3,1;则因为第2次计算和第3次计算的得到的Map的modCount次数是一致的,则说明这段时间内第2次和第3次这段时间内Map的数据没有被更新 * 此时可以返回第3次计算的Map大小;最坏的情况:第3次计算得到的计算结果和第2次不一致,则只能先对所有的Segment加锁再计算,最后解锁。 */ public int size() { // Try a few times to get accurate count. On failure due to // continuous async changes in table, resort to locking. final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits long sum; // sum of modCounts long last = 0L; // previous sum int retries = -1; // first iteration isn‘t retry try { for (;;) { // 如果重试次数为3次,锁定segment if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { //遍历所有的Segment Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { //累加修改的次数 sum += seg.modCount; //c代表segment的 int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } //如果和前一次计算的Map的size一致,结束循环,返回最终的size值 if (sum == last) break; last = sum; } } finally { // 如果重试次数>3次则,释放segment锁 if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; } /** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code key.equals(k)}, * then this method returns {@code v}; otherwise it returns * {@code null}. (There can be at most one such mapping.) * * @throws NullPointerException if the specified key is null */ public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; //1 和put操作一样,先通过key进行两次hash确定取哪个segment中的数据 int h = hash(key); //2 使用UNSAFE方法获取对应的Segment,然后再进行一次&运算得到HashEntry链表的位置,然后从链表头开始遍历整个链表。 //(由于hash会碰撞,所以用一个链表保存),如果找到对应的key,则返回对应的value值,如果链表遍历完都没有找到对应的key, // 则说明map中不包含该key,返回null long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; } /** * Tests if the specified object is a key in this table. * * @param key possible key * @return <tt>true</tt> if and only if the specified object * is a key in this table, as determined by the * <tt>equals</tt> method; <tt>false</tt> otherwise. * @throws NullPointerException if the specified key is null */ @SuppressWarnings("unchecked") public boolean containsKey(Object key) { Segment<K,V> s; // same as get() except no need for volatile value read HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return true; } } return false; } /** * Returns <tt>true</tt> if this map maps one or more keys to the * specified value. Note: This method requires a full internal * traversal of the hash table, and so is much slower than * method <tt>containsKey</tt>. * * @param value value whose presence in this map is to be tested * @return <tt>true</tt> if this map maps one or more keys to the * specified value * @throws NullPointerException if the specified value is null */ public boolean containsValue(Object value) { // Same idea as size() if (value == null) throw new NullPointerException(); final Segment<K,V>[] segments = this.segments; boolean found = false; long last = 0; int retries = -1; try { outer: for (;;) { //重试3次,计算size后才给所有segment加锁,计算Map的size if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } long hashSum = 0L; int sum = 0; for (int j = 0; j < segments.length; ++j) { HashEntry<K,V>[] tab; //遍历所有的Segment Segment<K,V> seg = segmentAt(segments, j); if (seg != null && (tab = seg.table) != null) { //遍历每个Segment里面的HashEntry for (int i = 0 ; i < tab.length; i++) { HashEntry<K,V> e; for (e = entryAt(tab, i); e != null; e = e.next) { //获取value值,并且与入参value进行比较 V v = e.value; //相同返回,found=true,退出循环 if (v != null && value.equals(v)) { found = true; break outer; } } } //累加各个segment的更新次数 sum += seg.modCount; } } //前一次计算的更新次数modCount和当前计算的segment的更新次数进行比较,相同,退出循环,返回found = true if (retries > 0 && sum == last) break; last = sum; } } finally { //重试计算次数>3次后,释放segment锁 if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return found; } /** * Legacy method testing if some key maps into the specified value * in this table. This method is identical in functionality to * {@link #containsValue}, and exists solely to ensure * full compatibility with class {@link java.util.Hashtable}, * which supported this method prior to introduction of the * Java Collections framework. * @param value a value to search for * @return <tt>true</tt> if and only if some key maps to the * <tt>value</tt> argument in this table as * determined by the <tt>equals</tt> method; * <tt>false</tt> otherwise * @throws NullPointerException if the specified value is null */ public boolean contains(Object value) { return containsValue(value); } /** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * * <p> The value can be retrieved by calling the <tt>get</tt> method * with a key that is equal to the original key. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt> * @throws NullPointerException if the specified key or value is null */ @SuppressWarnings("unchecked") public V put(K key, V value) { Segment<K,V> s; //1.value值不能为空 if (value == null) throw new NullPointerException(); //2.key通过一次hash运算得到一个hash值。(这个hash运算下文详说) int hash = hash(key); //3.将得到的hash值向右按位移动segmentShift位,然后再与segmentMask做&运算得到Segment的索引 //在初始化的时候,segmentShift的值等于32-sshift,例如concurrencyLevel等于16,则sshift等于4,那么segmentShift为28。 //hash值是一个32位的整数,将其向右移动28就变成这个样子:0000 0000 0000 0000 0000 0000 0000 XXXX,然后再用这个值与segmentMask //做&运算,也就是说取最后四位的值。这个值确定Segment的索引。 int j = (hash >>> segmentShift) & segmentMask; //4.使用UNSAFE的方式从Segment数组中获取该索引对应的Segment对象 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); //5.向这个Segment对象中put值,这个put操作也是一样的步骤 return s.put(key, hash, value, false); } /** * {@inheritDoc} * * @return the previous value associated with the specified key, * or <tt>null</tt> if there was no mapping for the key * @throws NullPointerException if the specified key or value is null */ @SuppressWarnings("unchecked") public V putIfAbsent(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject (segments, (j << SSHIFT) + SBASE)) == null) s = ensureSegment(j); return s.put(key, hash, value, true); } /** * Copies all of the mappings from the specified map to this one. * These mappings replace any mappings that this map had for any of the * keys currently in the specified map. * * @param m mappings to be stored in this map */ public void putAll(Map<? extends K, ? extends V> m) { for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) put(e.getKey(), e.getValue()); } /** * Removes the key (and its corresponding value) from this map. * This method does nothing if the key is not in the map. * * @param key the key that needs to be removed * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt> * @throws NullPointerException if the specified key is null */ public V remove(Object key) { int hash = hash(key); Segment<K,V> s = segmentForHash(hash); return s == null ? null : s.remove(key, hash, null); } /** * {@inheritDoc} * * @throws NullPointerException if the specified key is null */ public boolean remove(Object key, Object value) { int hash = hash(key); Segment<K,V> s; return value != null && (s = segmentForHash(hash)) != null && s.remove(key, hash, value) != null; } /** * {@inheritDoc} * * @throws NullPointerException if any of the arguments are null */ public boolean replace(K key, V oldValue, V newValue) { int hash = hash(key); if (oldValue == null || newValue == null) throw new NullPointerException(); Segment<K,V> s = segmentForHash(hash); return s != null && s.replace(key, hash, oldValue, newValue); } /** * {@inheritDoc} * * @return the previous value associated with the specified key, * or <tt>null</tt> if there was no mapping for the key * @throws NullPointerException if the specified key or value is null */ public V replace(K key, V value) { int hash = hash(key); if (value == null) throw new NullPointerException(); Segment<K,V> s = segmentForHash(hash); return s == null ? null : s.replace(key, hash, value); } /** * Removes all of the mappings from this map. */ public void clear() { final Segment<K,V>[] segments = this.segments; for (int j = 0; j < segments.length; ++j) { Segment<K,V> s = segmentAt(segments, j); if (s != null) s.clear(); } } /** * Returns a {@link Set} view of the keys contained in this map. * The set is backed by the map, so changes to the map are * reflected in the set, and vice-versa. The set supports element * removal, which removes the corresponding mapping from this map, * via the <tt>Iterator.remove</tt>, <tt>Set.remove</tt>, * <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt> * operations. It does not support the <tt>add</tt> or * <tt>addAll</tt> operations. * * <p>The view‘s <tt>iterator</tt> is a "weakly consistent" iterator * that will never throw {@link ConcurrentModificationException}, * and guarantees to traverse elements as they existed upon * construction of the iterator, and may (but is not guaranteed to) * reflect any modifications subsequent to construction. */ public Set<K> keySet() { Set<K> ks = keySet; return (ks != null) ? ks : (keySet = new KeySet()); } /** * Returns a {@link Collection} view of the values contained in this map. * The collection is backed by the map, so changes to the map are * reflected in the collection, and vice-versa. The collection * supports element removal, which removes the corresponding * mapping from this map, via the <tt>Iterator.remove</tt>, * <tt>Collection.remove</tt>, <tt>removeAll</tt>, * <tt>retainAll</tt>, and <tt>clear</tt> operations. It does not * support the <tt>add</tt> or <tt>addAll</tt> operations. * * <p>The view‘s <tt>iterator</tt> is a "weakly consistent" iterator * that will never throw {@link ConcurrentModificationException}, * and guarantees to traverse elements as they existed upon * construction of the iterator, and may (but is not guaranteed to) * reflect any modifications subsequent to construction. */ public Collection<V> values() { Collection<V> vs = values; return (vs != null) ? vs : (values = new Values()); } /** * Returns a {@link Set} view of the mappings contained in this map. * The set is backed by the map, so changes to the map are * reflected in the set, and vice-versa. The set supports element * removal, which removes the corresponding mapping from the map, * via the <tt>Iterator.remove</tt>, <tt>Set.remove</tt>, * <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt> * operations. It does not support the <tt>add</tt> or * <tt>addAll</tt> operations. * * <p>The view‘s <tt>iterator</tt> is a "weakly consistent" iterator * that will never throw {@link ConcurrentModificationException}, * and guarantees to traverse elements as they existed upon * construction of the iterator, and may (but is not guaranteed to) * reflect any modifications subsequent to construction. */ public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es = entrySet; return (es != null) ? es : (entrySet = new EntrySet()); } /** * Returns an enumeration of the keys in this table. * * @return an enumeration of the keys in this table * @see #keySet() */ public Enumeration<K> keys() { return new KeyIterator(); } /** * Returns an enumeration of the values in this table. * * @return an enumeration of the values in this table * @see #values() */ public Enumeration<V> elements() { return new ValueIterator(); } /* ---------------- Iterator Support -------------- */ abstract class HashIterator { int nextSegmentIndex; int nextTableIndex; HashEntry<K,V>[] currentTable; HashEntry<K, V> nextEntry; HashEntry<K, V> lastReturned; HashIterator() { nextSegmentIndex = segments.length - 1; nextTableIndex = -1; advance(); } /** * Set nextEntry to first node of next non-empty table * (in backwards order, to simplify checks). */ final void advance() { for (;;) { if (nextTableIndex >= 0) { if ((nextEntry = entryAt(currentTable, nextTableIndex--)) != null) break; } else if (nextSegmentIndex >= 0) { Segment<K,V> seg = segmentAt(segments, nextSegmentIndex--); if (seg != null && (currentTable = seg.table) != null) nextTableIndex = currentTable.length - 1; } else break; } } final HashEntry<K,V> nextEntry() { HashEntry<K,V> e = nextEntry; if (e == null) throw new NoSuchElementException(); lastReturned = e; // cannot assign until after null check if ((nextEntry = e.next) == null) advance(); return e; } public final boolean hasNext() { return nextEntry != null; } public final boolean hasMoreElements() { return nextEntry != null; } public final void remove() { if (lastReturned == null) throw new IllegalStateException(); ConcurrentHashMapSourceCode.this.remove(lastReturned.key); lastReturned = null; } } final class KeyIterator extends HashIterator implements Iterator<K>, Enumeration<K> { public final K next() { return super.nextEntry().key; } public final K nextElement() { return super.nextEntry().key; } } final class ValueIterator extends HashIterator implements Iterator<V>, Enumeration<V> { public final V next() { return super.nextEntry().value; } public final V nextElement() { return super.nextEntry().value; } } /** * Custom Entry class used by EntryIterator.next(), that relays * setValue changes to the underlying map. */ final class WriteThroughEntry extends AbstractMap.SimpleEntry<K,V> { WriteThroughEntry(K k, V v) { super(k,v); } /** * Set our entry‘s value and write through to the map. The * value to return is somewhat arbitrary here. Since a * WriteThroughEntry does not necessarily track asynchronous * changes, the most recent "previous" value could be * different from what we return (or could even have been * removed in which case the put will re-establish). We do not * and cannot guarantee more. */ public V setValue(V value) { if (value == null) throw new NullPointerException(); V v = super.setValue(value); ConcurrentHashMapSourceCode.this.put(getKey(), value); return v; } } final class EntryIterator extends HashIterator implements Iterator<Entry<K,V>> { public Map.Entry<K,V> next() { HashEntry<K,V> e = super.nextEntry(); return new WriteThroughEntry(e.key, e.value); } } final class KeySet extends AbstractSet<K> { public Iterator<K> iterator() { return new KeyIterator(); } public int size() { return ConcurrentHashMapSourceCode.this.size(); } public boolean isEmpty() { return ConcurrentHashMapSourceCode.this.isEmpty(); } public boolean contains(Object o) { return ConcurrentHashMapSourceCode.this.containsKey(o); } public boolean remove(Object o) { return ConcurrentHashMapSourceCode.this.remove(o) != null; } public void clear() { ConcurrentHashMapSourceCode.this.clear(); } } final class Values extends AbstractCollection<V> { public Iterator<V> iterator() { return new ValueIterator(); } public int size() { return ConcurrentHashMapSourceCode.this.size(); } public boolean isEmpty() { return ConcurrentHashMapSourceCode.this.isEmpty(); } public boolean contains(Object o) { return ConcurrentHashMapSourceCode.this.containsValue(o); } public void clear() { ConcurrentHashMapSourceCode.this.clear(); } } final class EntrySet extends AbstractSet<Map.Entry<K,V>> { public Iterator<Map.Entry<K,V>> iterator() { return new EntryIterator(); } public boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>)o; V v = ConcurrentHashMapSourceCode.this.get(e.getKey()); return v != null && v.equals(e.getValue()); } public boolean remove(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>)o; return ConcurrentHashMapSourceCode.this.remove(e.getKey(), e.getValue()); } public int size() { return ConcurrentHashMapSourceCode.this.size(); } public boolean isEmpty() { return ConcurrentHashMapSourceCode.this.isEmpty(); } public void clear() { ConcurrentHashMapSourceCode.this.clear(); } } /* ---------------- Serialization Support -------------- */ /** * Save the state of the <tt>ConcurrentHashMap</tt> instance to a * stream (i.e., serialize it). * @param s the stream * @serialData * the key (Object) and value (Object) * for each key-value mapping, followed by a null pair. * The key-value mappings are emitted in no particular order. */ private void writeObject(java.io.ObjectOutputStream s) throws IOException { // force all segments for serialization compatibility for (int k = 0; k < segments.length; ++k) ensureSegment(k); s.defaultWriteObject(); final Segment<K,V>[] segments = this.segments; for (int k = 0; k < segments.length; ++k) { Segment<K,V> seg = segmentAt(segments, k); seg.lock(); try { HashEntry<K,V>[] tab = seg.table; for (int i = 0; i < tab.length; ++i) { HashEntry<K,V> e; for (e = entryAt(tab, i); e != null; e = e.next) { s.writeObject(e.key); s.writeObject(e.value); } } } finally { seg.unlock(); } } s.writeObject(null); s.writeObject(null); } /** * Reconstitute the <tt>ConcurrentHashMap</tt> instance from a * stream (i.e., deserialize it). * @param s the stream */ @SuppressWarnings("unchecked") private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException { // Don‘t call defaultReadObject() ObjectInputStream.GetField oisFields = s.readFields(); final Segment<K,V>[] oisSegments = (Segment<K,V>[])oisFields.get("segments", null); final int ssize = oisSegments.length; if (ssize < 1 || ssize > MAX_SEGMENTS || (ssize & (ssize-1)) != 0 ) // ssize not power of two throw new java.io.InvalidObjectException("Bad number of segments:" + ssize); int sshift = 0, ssizeTmp = ssize; while (ssizeTmp > 1) { ++sshift; ssizeTmp >>>= 1; } UNSAFE.putIntVolatile(this, SEGSHIFT_OFFSET, 32 - sshift); UNSAFE.putIntVolatile(this, SEGMASK_OFFSET, ssize - 1); UNSAFE.putObjectVolatile(this, SEGMENTS_OFFSET, oisSegments); // set hashMask UNSAFE.putIntVolatile(this, HASHSEED_OFFSET, randomHashSeed(this)); // Re-initialize segments to be minimally sized, and let grow. int cap = MIN_SEGMENT_TABLE_CAPACITY; final Segment<K,V>[] segments = this.segments; for (int k = 0; k < segments.length; ++k) { Segment<K,V> seg = segments[k]; if (seg != null) { seg.threshold = (int)(cap * seg.loadFactor); seg.table = (HashEntry<K,V>[]) new HashEntry[cap]; } } // Read the keys and values, and put the mappings in the table for (;;) { K key = (K) s.readObject(); V value = (V) s.readObject(); if (key == null) break; put(key, value); } } // Unsafe mechanics private static final sun.misc.Unsafe UNSAFE; private static final long SBASE; private static final int SSHIFT; private static final long TBASE; private static final int TSHIFT; private static final long HASHSEED_OFFSET; private static final long SEGSHIFT_OFFSET; private static final long SEGMASK_OFFSET; private static final long SEGMENTS_OFFSET; static { int ss, ts; try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class tc = HashEntry[].class; Class sc = Segment[].class; TBASE = UNSAFE.arrayBaseOffset(tc); SBASE = UNSAFE.arrayBaseOffset(sc); ts = UNSAFE.arrayIndexScale(tc); ss = UNSAFE.arrayIndexScale(sc); HASHSEED_OFFSET = UNSAFE.objectFieldOffset( ConcurrentHashMap.class.getDeclaredField("hashSeed")); SEGSHIFT_OFFSET = UNSAFE.objectFieldOffset( ConcurrentHashMap.class.getDeclaredField("segmentShift")); SEGMASK_OFFSET = UNSAFE.objectFieldOffset( ConcurrentHashMap.class.getDeclaredField("segmentMask")); SEGMENTS_OFFSET = UNSAFE.objectFieldOffset( ConcurrentHashMap.class.getDeclaredField("segments")); } catch (Exception e) { throw new Error(e); } if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0) throw new Error("data type scale not a power of two"); SSHIFT = 31 - Integer.numberOfLeadingZeros(ss); TSHIFT = 31 - Integer.numberOfLeadingZeros(ts); } }
参考文章:
1.https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/
2.http://www.infoq.com/cn/articles/ConcurrentHashMap
3.http://qifuguang.me/
标签:
原文地址:http://www.cnblogs.com/200911/p/5800493.html