标签:

|
namespaceID=1232737062 cTime=0 storageType=NAME_NODE layoutVersion=-18 |



|
namespaceID=1232737062 storageID=DS-1640411682-127.0.1.1-50010-1254997319480 cTime=0 storageType=DATA_NODE layoutVersion=-18 |

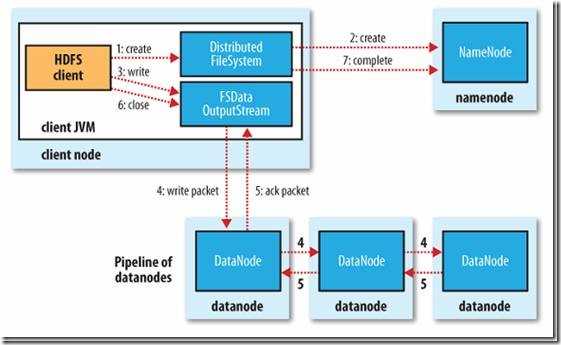
转:http://www.cnblogs.com/forfuture1978/archive/2010/03/14/1685351.html
标签:
原文地址:http://www.cnblogs.com/andy6/p/5800541.html