标签:
一、定义:
模块:用来从逻辑上组织py代码(变量、函数、类、逻辑:实现一个功能),本质就是
.py结尾的python文件(文件名:test.py,对应的模块名:test)
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
自定义模块 和开源模块的使用参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
二、导入方法:
import module_name
import module1_name, module2_name
from module_alex import *
from module_alex import m1,m2,m3
from module_alex import logger as logger_alex 定义个变量
三、import本质(路径搜索和搜索路劲)
导入模块的本质就是把python文件解释一遍(import test test= ‘test.py all code‘)
import module_name ----> module_name.py--->module_name.py的路径-->sys.path
导入包的本质就是执行该包下的__init__.py文件
四、导入优化
form module_test import test
五、模块的分类
a:标准库
time与datetime
strftime("格式",struct_time)--->"格式化的字符串"
strtime盘("格式化的字符串","格式")--->struct_time
b:开源模块
c:自定义模块
random模块

#!/usr/bin/env python #_*_encoding: utf-8_*_ import random print (random.random()) #0.6445010863311293 #random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 print (random.randint(1,7)) #4 #random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。 # 其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b print (random.randrange(1,10)) #5 #random.randrange的函数原型为:random.randrange([start], stop[, step]), # 从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2), # 结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数。 # random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。 print(random.choice(‘liukuni‘)) #i #random.choice从序列中获取一个随机元素。 # 其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。 # 这里要说明一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。 # list, tuple, 字符串都属于sequence。有关sequence可以查看python手册数据模型这一章。 # 下面是使用choice的一些例子: print(random.choice("学习Python"))#学 print(random.choice(["JGood","is","a","handsome","boy"])) #List print(random.choice(("Tuple","List","Dict"))) #List print(random.sample([1,2,3,4,5],3)) #[1, 2, 5] #random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
#!/usr/bin/env python # encoding: utf-8 import random import string #随机整数: print( random.randint(0,99)) #70 #随机选取0到100间的偶数: print(random.randrange(0, 101, 2)) #4 #随机浮点数: print( random.random()) #0.2746445568079129 print(random.uniform(1, 10)) #9.887001463194844 #随机字符: print(random.choice(‘abcdefg&#%^*f‘)) #f #多个字符中选取特定数量的字符: print(random.sample(‘abcdefghij‘,3)) #[‘f‘, ‘h‘, ‘d‘] #随机选取字符串: print( random.choice ( [‘apple‘, ‘pear‘, ‘peach‘, ‘orange‘, ‘lemon‘] )) #apple #洗牌# items = [1,2,3,4,5,6,7] print(items) #[1, 2, 3, 4, 5, 6, 7] random.shuffle(items) print(items) #[1, 4, 7, 2, 5, 3, 6]
例一:随机生成位验证码
import random checkcode=‘‘ for i in range(4): current = random.randrange(1,5) if current == i: tmp = chr(random.randint(65,90)) else: tmp = chr(random.randint(0,9)) checkcode+=str(tmp) print(checkcode)
六、time & datetime
1 #_*_coding:utf-8_*_ 2 __author__ = ‘liudong‘ 3 4 import time 5 6 7 # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来 8 # print(time.altzone) #返回与utc时间的时间差,以秒计算\ 9 # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016", 10 # print(time.localtime()) #返回本地时间 的struct time对象格式 11 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式 12 13 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016", 14 #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上 15 16 17 18 # 日期字符串 转成 时间戳 19 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式 20 # print(string_2_struct) 21 # # 22 # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳 23 # print(struct_2_stamp) 24 25 26 27 #将时间戳转为字符串格式 28 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式 29 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式 30 31 32 33 34 35 #时间加减 36 import datetime 37 38 # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 39 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 40 # print(datetime.datetime.now() ) 41 # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 42 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 43 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 44 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 45 46 47 # 48 # c_time = datetime.datetime.now() 49 # print(c_time.replace(minute=3,hour=2)) #时间替换
七、OS 模块
提供对操作系统进行调用的接口os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
八、SYS模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write(‘please:‘) val = sys.stdin.readline()[:-1]
九、shutil模块
直接参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
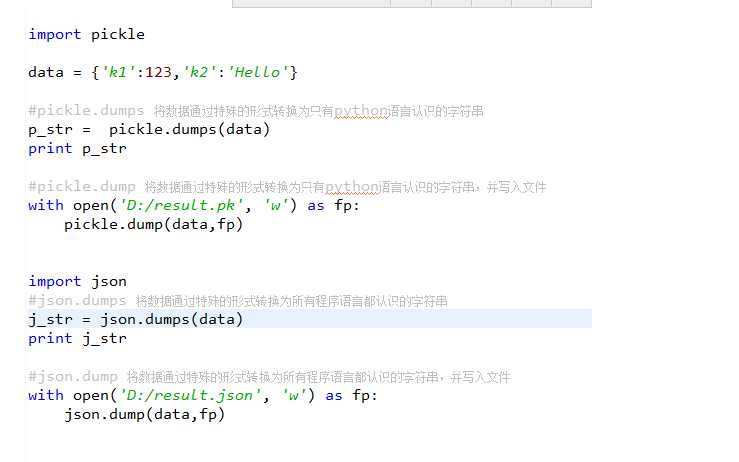
十、json & pickle模块
用于序列化的两个模块
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
十一、re模块
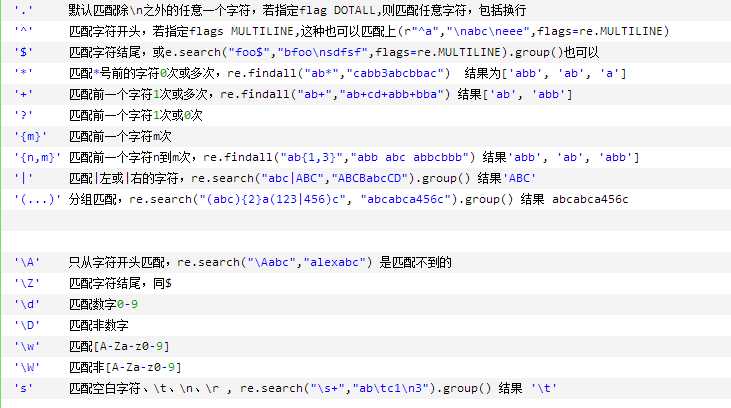
常用的正则表达式符号:
‘.‘ 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 ‘^‘ 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) ‘$‘ 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 ‘*‘ 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为[‘abb‘, ‘ab‘, ‘a‘] ‘+‘ 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果[‘ab‘, ‘abb‘] ‘?‘ 匹配前一个字符1次或0次 ‘{m}‘ 匹配前一个字符m次 ‘{n,m}‘ 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果‘abb‘, ‘ab‘, ‘abb‘] ‘|‘ 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果‘ABC‘ ‘(...)‘ 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c ‘\A‘ 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的 ‘\Z‘ 匹配字符结尾,同$ ‘\d‘ 匹配数字0-9 ‘\D‘ 匹配非数字 ‘\w‘ 匹配[A-Za-z0-9] ‘\W‘ 匹配非[A-Za-z0-9] ‘s‘ 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 ‘\t‘
‘(?P<name>...)‘ <分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{‘province‘: ‘3714‘, ‘city‘: ‘81‘, ‘birthday‘: ‘1993‘}
例:
1、re.search("(?P<id>[0-9]+)(?P<name>[a-zA-Z]+)","abcd1234daf@34").groupdict()
效果:{‘id‘: ‘1234‘, ‘name‘: ‘def‘}
2、re.sub("[0-9]+","|", "abc12de3f45GH")
效果:‘abc|de|f|GH’
四种匹配方法:match search findall aplit
压缩:shutil.make_archive("shutil_archive_test","zip","压缩路径")
标签:
原文地址:http://www.cnblogs.com/liuyansheng/p/5800812.html
