标签:
计算框架:
MapReduce:主要用于离线计算
Storm:流式计算框架,更适合做实时计算
stack:内存计算框架,快速计算
MapReduce设计理念:
--何为分布式计算
--移动计算,而不是移动数据
4个步骤:
1.Splitting
2.Mapping:Map步骤有可能有多个Map task线程并发同时执行
3.Shuffing:合并和排序
4.Reducing
Hadoop计算框架Shuffler
在mapper和reducer中间的一个步骤
可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理
可以简化reducer过程
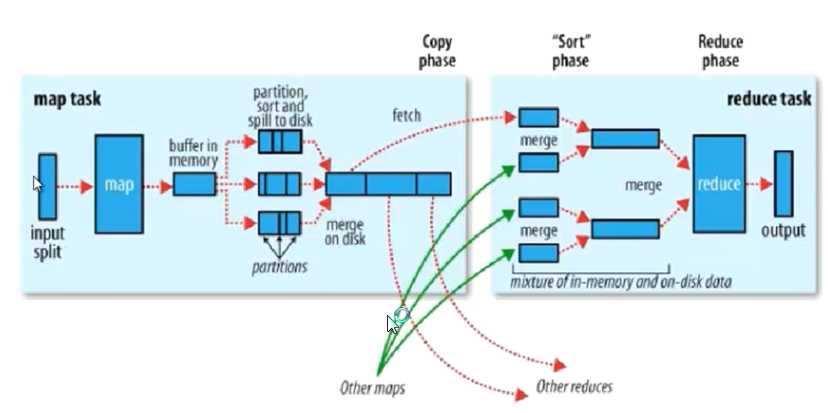
partition:分区
如果不进行分区,会有默认的分区 “哈希模运算”
1.获得 哈希值 -->得到一个整数(int) --> 模reduce的个数得到一个结果
分区 是为了把map的输出数据进行 负载均衡 或解决数据倾斜问题
map中不会出现数据倾斜问题,map的输入数据split(片段)事实上来源于dataNode的block块
默认的partition有可能产生数据倾斜问题
如果有 数据倾斜 问题,需要更改和优化partition
sort:排序
程序可以控制的地方
partition,sort(比较算法,默认按照字典排序(ASCII大小)),combiner

在spill to desk 时候出现 sort和combiner
Combiner 有可能不存在

MapReduce 的 Split 大小
-- max.split(100M)
-- min.split(10M)
-- block(64M)
-- max(min.split,min(max.split,block))
MapReduce 的架构
一主多从架构
主JobTracker:
负责调度分配每一个子任务task运行与TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点.每一个hadoop集群中只有一个JobTracker.一般它运行在Master节点上
从TaskTracker:
TaskTracker主动与JobTracker通信,接受作业,并负责执行每一个任务,为了减少网络带宽TaskTracker最好运行咋HDFS的DataNode上
搭建:
1.指定JobTracker所在的机器
conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.201:9001</value>
</property>
</configuration>
2.如果TaskTracker配置在DataNode上,默认不需要配置
3.同步配置文件
[root@bogon conf]# scp ./mapred-site.xml root@192.168.1.202:~/hadoop-1.2.1/conf/
[root@bogon conf]# scp ./mapred-site.xml root@192.168.1.203:~/hadoop-1.2.1/conf/
4.启动
[root@bogon bin]# ./start-all.sh
5.使用 jps 查看启动
192.168.1.201
[root@bogon bin]# jps 31470 Jps 8773 JobTracker 8593 NameNode [root@bogon bin]#
192.168.1.202
[root@localhost ~]# jps 27580 DataNode 27657 SecondaryNameNode 28849 Jps 27750 TaskTracker [root@localhost ~]#
192.168.1.203
[root@localhost ~]# jps 27019 TaskTracker 27989 Jps 26920 DataNode [root@localhost ~]#
使用 http://192.168.1.201:50030/ 查看
生成 eclipse 插件
hadoop-1.2.1\src\contrib\eclipse-plugin 在eclipse中编译成jar
将编译好的jar放入到eclipse的plugin中
eclipse版本不能太低也不能太高 使用4.4
标签:
原文地址:http://www.cnblogs.com/wq3435/p/5801360.html