标签:
加载方式三种
1. Eager Loading
2. Lazy Loading
3.Explicit Loading
使用EF在与关系型数据库的交互中不可避免地需要加载数据,如何加载数据变得至关重要。你可以设想在一个包含数十万条数据的表中,你如何通过EF来加载数据呢?一次性将所有数据载入服务器内存或者在循环中一遍又一遍地分步加载数据?使用什么样的数据加载方式需要具体问题具体分析,我们不能在这里笼统地下决定说哪种方式好哪种方式不好。但有一点是需要遵循的,那就是如何提高数据加载的效率。EF提供了几种不同的数据加载方式,我们可以根据不同的需要灵活使用它们。
先简单说一下如何创建环境。如果你对这些步骤了如指掌,请直接跳过。
1. 在Visual Studio中创建一个示例工程。最简单的莫过于ConsoleApplication
2. 在工程中添加ADO.NET Entity Data Model。如下图所示,
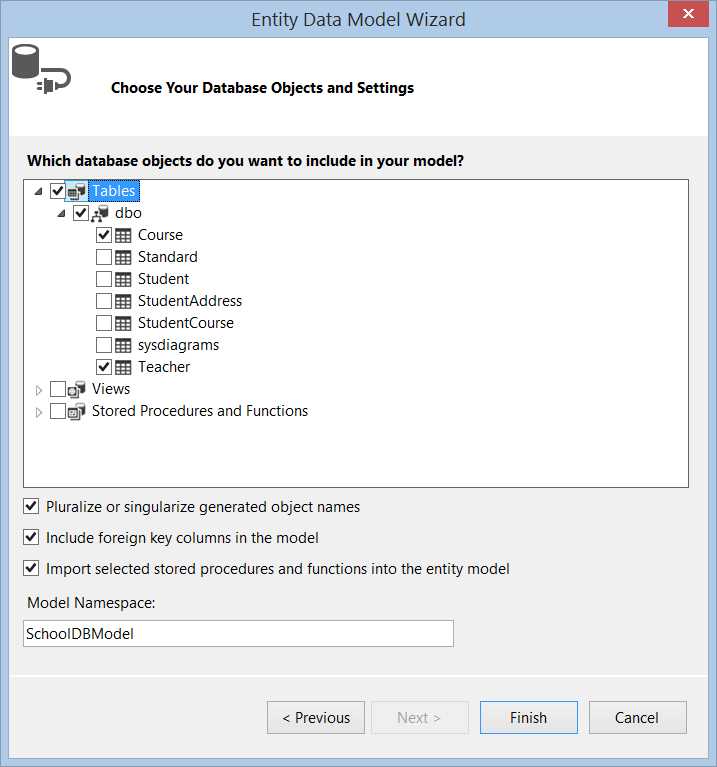
选择其中的两个表作为示例,表Teacher和表Course,关系如下,
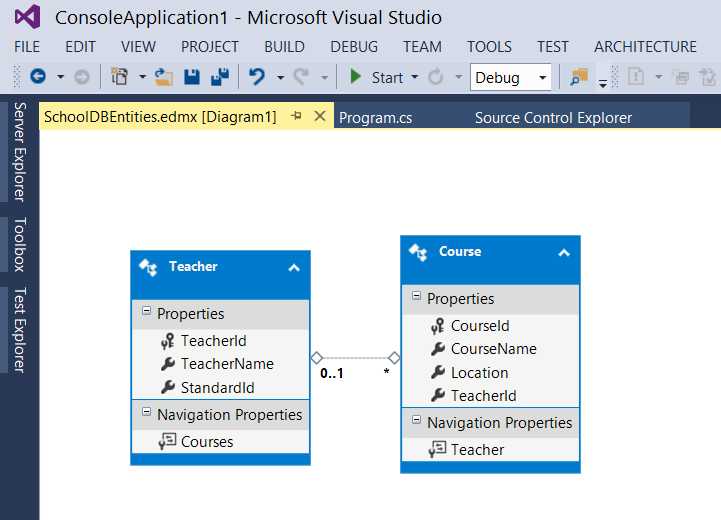
添加edmx之后,Visual Studio为自动帮我们生成/添加所有需要的文件和内容,然后我们就可以开始在代码中操作数据库了。来看看在EF中几种不同的数据加载方式。
惰性加载(Lazy Loading)
默认情况下,EF会使用惰性加载方式加载数据,即ctx.Configuration.LazyLoadingEnabled = true; 在下面的代码中,外层循环会执行一次查询,并将返回的结果存放在变量q中。而内层循环会在每一次循环过程中独立进行查询,所以,如果数据库表Teacher中有100条记录而Course有1000条记录,那么整个过程将产生1001次查询。

using (var ctx = new SchoolDBEntities())
{
var q = from t in ctx.Teachers
select t;
foreach (var teacher in q)
{
Console.WriteLine("Teacher : {0}", teacher.TeacherName);
Console.WriteLine("Respective Courses...");
foreach (var course in teacher.Courses)
{
Console.WriteLine("Course name : {0}", course.CourseName);
}
Console.WriteLine();
Console.ReadKey();
}
}
下面是程序执行的结果以及在SQL Server Profiler中的跟踪记录。可以清楚地看到,对表Teacher只进行了一次查询,由于该表只有8条记录,于是在内层循环中又分别产生了8次对表Course的查询。
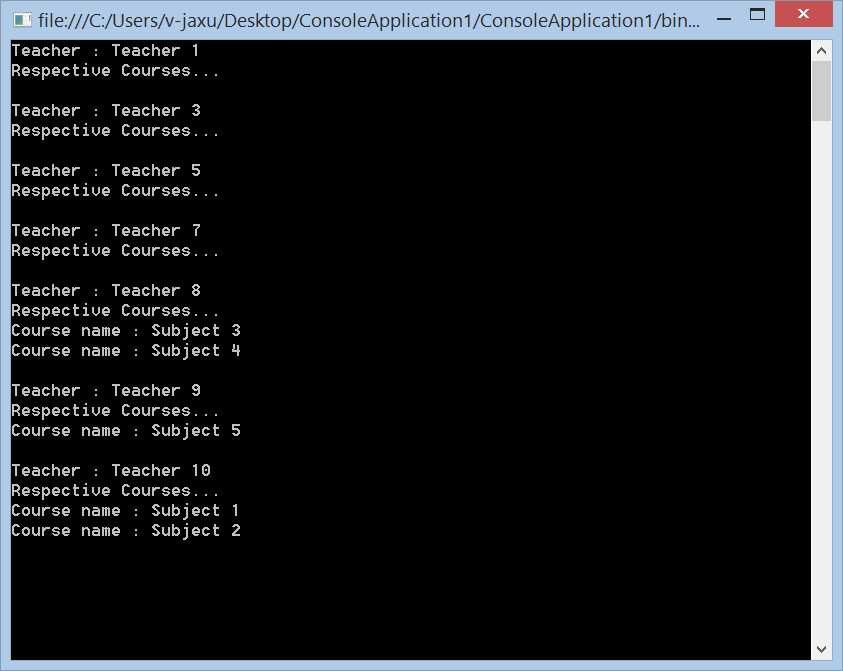
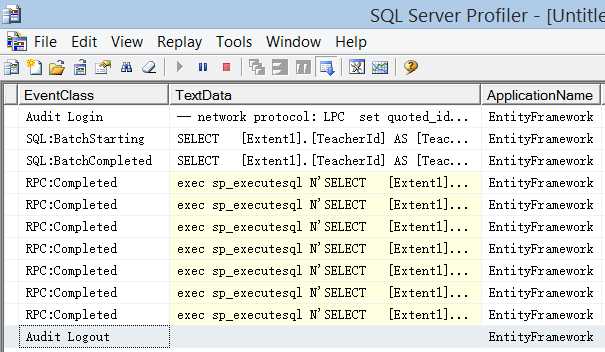
在某些场合下,这种情况是可以接受的。你完全可以根据需要来控制内层循环何时显示加载数据,或者根本不加载数据。但是,在分层结构的应用程序中,上述代码结构并不适用,因为内层循环需要依赖于外层的Context,也就是说它们是在同一个数据库上下文中完成的,如果尝试将内层循环的代码移到外面或者其它类中,则它将获取不到任何数据。
显式加载(Explicit Loading)
如果你想人为控制惰性加载的行为,可以尝试使用下面的代码。首先需要手动关闭EF的惰性加载,通过代码ctx.Configuration.LazyLoadingEnabled = false;来完成。
using (var ctx = new SchoolDBEntities())
{
ctx.Configuration.LazyLoadingEnabled = false;
var q = from t in ctx.Teachers
select t;
foreach (var teacher in q)
{
Console.WriteLine("Teacher : {0}", teacher.TeacherName);
Console.WriteLine("Respective Courses...");
// Conditionally load the child data
if (true)
{
ctx.Entry(teacher).Collection(c => c.Courses).Load();
}
foreach (var course in teacher.Courses)
{
Console.WriteLine("Course name : {0}", course.CourseName);
}
Console.WriteLine();
Console.ReadKey();
}
}
注意内层循环只有在上面高亮显示部分的代码执行之后才会获取到数据,否则返回结果为0。通过添加判断条件,我们可以对数据加载方式进行控制,从而有效地减少程序与数据库交互的次数。大多数情况下,我们从数据库获取到的数据并不都是有用的,如果每次只有很少一部分数据有用,那么我们为什么不过滤掉那些无用的数据从而尽量较少数据交互的次数呢?
预先加载(Eager Loading)
如果你想让所有数据一次性全部加载到内存中,那么你需要使用.Include(Entity)方法。看下面的代码,
using (var ctx = new SchoolDBEntities())
{
var q = from t in ctx.Teachers.Include("Courses")
select t;
foreach (var teacher in q)
{
Console.WriteLine("Teacher : {0}", teacher.TeacherName);
Console.WriteLine("Respective Courses...");
foreach (var course in teacher.Courses)
{
Console.WriteLine("Course name : {0}", course.CourseName);
}
Console.WriteLine();
Console.ReadKey();
}
}
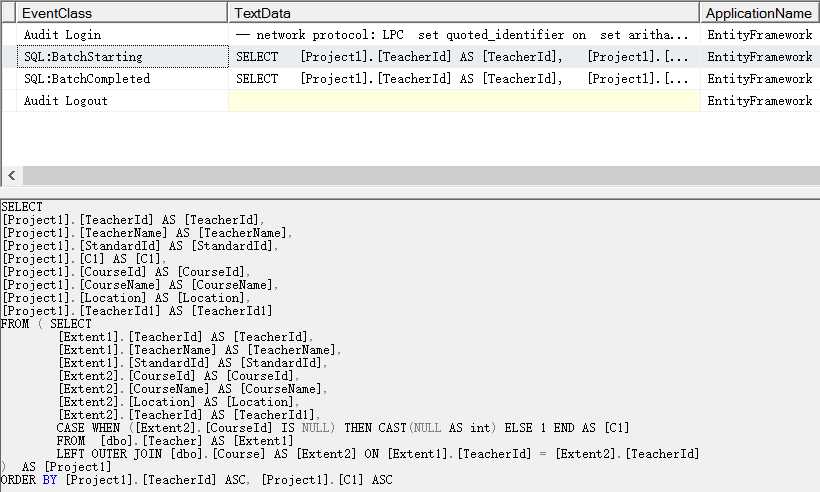
如果你查看SQl Server Profiler中的跟踪信息,你会发现只有一次数据交互过程,即程序只通过一次查询便获取到了所有需要的数据。在分层结构中,该方法是最容易的,我们可以将数据库底层获取到的结果返回给上层,它不具有任何依赖项。同时,它也可以减少程序与数据库的交互次数。不过仍然有缺点,那就是如果数据量较大,一次性将所有数据载入内存往往并不是最明智的选择。.Include(Entity)方法允许级联使用,你可以预先加载具有多层级结构的数据。
就像前面所说,选择什么样的数据加载方式需要因时而异,每一种数据加载方式都有它存在的意义,但目的只有一个,那就是以最少的代价获取到需要的数据。
数据库表与实体Entity的映射
实现方式有两种,最终是通过外键的方式实现一对一 一对多 多对多的关联
实体直接导航关联或外键,导航实现实体关系清晰,由EF Code First自动生成关联外键 DataAnnonation FluentAPI更底层
1.DataAnnonation
2.FluentAPI
如果你对EF里实体间的各种关系还不是很熟悉,可以看看我的思路,能帮你更快的理解。
I.实体间一对一的关系
添加一个PersonPhoto类,表示用户照片类
/// <summary>
/// 用户照片类
/// </summary>
public class PersonPhoto
{
[Key]
public int PersonId { get; set; }
public byte[] Photo { get; set; }
public string Caption { get; set; } //标题
public Person PhotoOf { get; set; }
}
当然,也需要给Person类添加PersonPhoto的导航属性,表示和PersonPhoto一对一的关系:
public PersonPhoto Photo { get; set; }
直接运行程序会报一个错:
Unable to determine the principal end of an association between the types ‘Model.Per-sonPhoto’ and ‘Model.Person’. The principal end of this association must be explicitly configured using either the relationship fluent API or data annotations.
思考:为何第一节的Destination和Lodging类直接在类里加上导航属性就可以生成主外键关系,现在的这个不行呢? 解答:之前文章里的Destination和Lodging是一对多关系,既然是一对多,EF自然就知道设置Destination类的DestinationId为主键,同时设置Lodging类里的DestinationId为外键;但是现在的这个Person类和PersonPhoto类是一对一的关系,如果不手动指定,那么EF肯定不知道设置哪个为主键哪个为外键了,这个其实不难理解。按照逻辑Person类的PersonId肯定是主键了,直接标注[ForeignKey("PhotoOf")]即可,这是Data Annotation方式配置,自然也可以Fluent API一下,博主个人更喜欢这个方式。
在演示Fluent API如何配置Person类和PersonPhoto的一对一关系之前,先系统的学习下EF里实体关系配置的方法。EF里的实体关系配置分为Has和With系列的方法:Optional 可选的、Required 必须的、Many 多个。举例:
A.HasRequired(a => a.B).WithOptional(b => b.A);
这里的a=>a.B是lambda表示写法,就是找到A类里的导航属性B。命名a不固定,可以随意,q=>q.B也是可以的。但是B是A类的属性,故习惯用小写a。
Has方法:
With方法:
摘自这里这是较为好的理解方式。上面一句配置意思就是A类包含B类一个不为null的实例,B类包含A类一个实例,也可以不包含。最标准的一对一配置。ok,现在试着写下上面Person类和PersonPhoto类的一对一的关系如何配置:
this.HasRequired(p => p.PhotoOf).WithOptional(p => p.Photo);
再跑下程序,数据库就生成了,是一对一的关系。Person表可以没有对应的PersonPhoto表数据,但是PersonPhoto表每一条数据都必须对应一条Person表数据。意思就是人可以没有照片,但是有的照片必须属于某个人。关系配置是这样的效果,其实可以随便改,也可以配置成每个人都必须有对应的照片。把上面的WithOptional改成WithRequired,对应到数据库里就是null变成了not null。
思考:这里并没有像之前一样添加一个实体类就同时添加到BreakAwayContext类中,但是为何照样能在数据库中生成PersonPhotos表? 解答: 添加到BreakAwayContext类中是让数据库上下文能跟踪到这个类,方便进行CRUD(增查改删)。 这里不把 PersonPhoto 类添加到 BreakAwayContext 类中是因为程序中一般并不会去单独增删改查 PersonPhoto 类,对 PersonPhoto 类的操作都是先找Person类,然后通过一对一的关系找到 PersonPhoto 类,这个比较符合实际情况。数据库中能生成 PersonPhotos 就更好理解了,因为有这个实体类嘛。 思考:如果只需要加入主表类到BreakAwayContext类中,那么其他什么一对多,多对多的关系是不是都只要加主表类到 BreakAwayContext 类中呢? 解答:还是需要根据实际情况考虑,上面的PersonPhoto类已经解释过了,实际情况中不太可能单独操作 PersonPhoto 类。一对多关系里Logding住宿类是从表类,Destination是其主表。这个想想也知道必须要让数据库上下文跟踪到 Lodging住宿类 ,因为太可能直接操作Lodging了。比如前台添加一个搜索住宿的功能,那是不是需要直接操作此从表了呢?肯定需要了。所以还是需要根据实际情况考虑。这里仅是个人观点,如有瑕疵,恳请指正。
II.实体间一对多的关系
之前的文章里,景点类Destination和住宿类Lodging是一对多的关系,这个很好理解:一个景点那有多个住宿的地方,而一个住宿的地方只属于一个景点。当然也可以没有,一个景点那一个住宿的地方就没有,一个住宿的地方不属于任何景点,这个也是可以的。之前的程序实现的就是互相不属于,全部可空。现在来配置下住宿的地方必须属于某个景点:
Data Annotations 直接在住宿类Lodging的导航属性上添加[Required]标注即可:
[Required]
public Destination Destination { get; set; }
Fluent API
this.HasMany(d => d.Lodgings).WithRequired(l => l.Destination).Map(l => l.MapKey("DestinationId"));
这行是在DestinationMap类里写的,对应到上面的描述,前者就是Destination,后者是Lodging。整句的意思就是:Destination类包含多个(HasMany)Lodging类实例的集合,Lodging类包含前者一个不为null(WithRequired)的实例。.MapKey是指定外键名的。此处如果住宿类不必须属于某个景点,那么直接把WithRequired换成WithOptional即可。查询的时候前者使用Inner join,后者使用Left join。不懂Inner、Left和Cross Join区别的点这里
上面是以Destination为前者的,当然也可以以Lodging为前者,去LodgingMap里写下如下配置,其实是一个意思:
this.HasRequired(d => d.Destination).WithMany(l => l.Lodgings).Map(l => l.MapKey("DestinationId"));
重跑下程序,生成的数据库Lodging表的外键已经设置成为了不可空,并外键名是指定的“DestinationId”:

官方给出的一对多的解释是这样的,其实还没我解释的通俗易懂,发个图你们感受下吧:

ok,上面说了一对多的关系,是标准的一对多关系,两个表里分别有导航属性。但是如果有列不遵循这个规则呢? 继续添加一个新类InternetSpecial,记录一些跟平常住宿价格不一样的类,节假日等。这个类不仅有导航属性Accommodation,还有主键列AccommodationId:
/// <summary>
/// 住宿特殊价格类(节假日等)
/// </summary>
public class InternetSpecial
{
public int InternetSpecialId { get; set; }
public int Nights { get; set; } //几晚
public decimal CostUSD { get; set; } //价钱
public DateTime FromDate { get; set; }
public DateTime ToDate { get; set; }
public int AccommodationId { get; set; }
public Lodging Accommodation { get; set; }
}
同时给住宿类Lodging添加一个 InternetSpecial 类的导航属性:
public List<InternetSpecial> InternetSpecials { get; set; }
配置好了跑下程序,生成的数据库表:

由表可见,不仅有AccommodationId列,还有个外键列Accommodation_LodgingId,明显这个是因为没有设置外键的原因,EF不知道要给哪个属性当外键。现在分别使用Data Annotation和Fluent API设置试试
Data Annotation:
[ForeignKey("Accommodation")]
public int AccommodationId { get; set; }
或者这样:
[ForeignKey("AccommodationId")]
public Lodging Accommodation { get; set; }
Fluent API:
this.HasRequired(s => s.Accommodation)
.WithMany(l => l.InternetSpecials)
.HasForeignKey(s => s.AccommodationId); //外键
//如果实体类没定义AccommodationId,那么可以使用Map方法直接指定外键名:.Map(s => s.MapKey("AccommodationId"))
这个就不详细解释了,如果还看不懂,看看文章开头我分析的Has和With系列方法。配置好重新跑下程序,外键就是AccommodationId了,没有多余的Accommodation_LodgingId列了。
III.实体间多对多的关系
添加一个活动类Activity,跟旅行类Trip是多对多的关系。这个也不难理解:一个旅行有多个活动,一个活动可以属于多个旅行。
/// <summary>
/// 活动类
/// </summary>
public class Activity
{
public int ActivityId { get; set; }
//[Required, MaxLength(50)]
public string Name { get; set; }
public List<Trip> Trips { get; set; } //和Trip类是多对多关系
}
跟之前的一样在BreakAwayContext类里添加Activity类,让数据库上下文知道Activity类:
public DbSet<CodeFirst.Model.Activity> Activitys { get; set; }
同时在Trip旅行类里添加上导航属性,形成跟Activity活动类的多对多关系
public List<Activity> Activitys { get; set; }
ok,已经可以了,跑下程序得到如下数据库:

可以看出,EF里的多对多关系是由第三张表来连接两个表的。ActivityTrips表连接了Activityes表和Trips表。表名列名都是默认命名,都可以自己配置。文章的开头已经说了那么多了,多对多肯定是用HasMany和WithMany方法,在ActivityMap类里写下如下Fluent API:
this.HasMany(a => a.Trips).WithMany(t => t.Activitys).Map(m =>
{
m.ToTable("TripActivities"); //中间关系表表名
m.MapLeftKey("ActivityId"); //设置Activity表在中间表主键名
m.MapRightKey("TripIdentifier"); //设置Trip表在中间表主键名
});
同样也可以在TripMap里配置,顺序不一样罢了:
this.HasMany(t => t.Activities).WithMany(a => a.Trips).Map(m =>
{
m.ToTable("TripActivities"); //中间关系表表名
m.MapLeftKey("TripIdentifier"); //设置Activity表在中间表的主键名
m.MapRightKey("ActivityId"); //设置Trip表在中间表的主键名
});
两种配置任选其一就可以了,重新跑下程序就可以了。都配置好了在程序里如何读取这个对多对的数据呢,简单写一句:
var tripWithActivities = context.Trips.Include("Activities").FirstOrDefault();
很明显,用到了Include贪婪加载把相关的外键表数据(如果有)也拿到了内存中:

是不是也需要考虑性能的问题呢?如果只需要修改主表的某个列,那贪婪加载出相关联的从表数据做什么?会发送很多冗余的sql到数据库。当然如果要根据主表找从表数据的话,这么加载也是好事,超级方便。EF小组的原话是:Entity Framework took care of the joins to get across the join table without you having to be aware of its presence. In the same way, any time you do inserts, updates, or deletes within this many-to-many relationship, Entity Framework will work out the proper SQL for the join without you having to worry about it in your code. 意思就是如果你配置好了主外键关系,EF会帮你生成合适的连表查询(join)sql,不会你再多费心。关于一对多、多对多的EF查询和效率问题,后续会有专门系列文章讲解。
IV.级联删除
EF配置的外键关系除了配置为Optional(可选的,也就是可空),其他默认都是级联删除的,意思就是删除主表的某个数据,相关联的从表数据都自动删除:

为了演示添加一个方法:
//级联删除(服务端延迟加载)
private static void DeleteDestinaInMemoryAndDbCascade()
{
int destinationId;
using (var context = new CodeFirst.DataAccess.BreakAwayContext())
{
var destination = new CodeFirst.Model.Destination
{
Name = "Sample Destination",
Lodgings = new List<CodeFirst.Model.Lodging>
{
new CodeFirst.Model.Lodging {Name="Lodging One"},
new CodeFirst.Model.Lodging {Name="Lodging Two"}
}
};
context.Destinations.Add(destination); //添加测试数据
context.SaveChanges();
destinationId = destination.DestinationId; //记住主键id
}
using (var context = new CodeFirst.DataAccess.BreakAwayContext())
{
//这里用了贪婪加载,把主键和相关的外键记录都加载到内存中了
var destination = context.Destinations.Include("Lodgings").Single(d => d.DestinationId == destinationId);
var aLodging = destination.Lodgings.FirstOrDefault();
context.Destinations.Remove(destination);
context.SaveChanges();
}
}
很简单,添加了一条主键数据Sample Destination,同时添加了以此主键为基础的两条外键数据:Lodging One和Lodging Two,即:添加了一个旅游景点,又添加了此旅游景点下的两个住宿的地方。之后延迟加载出主表数据和相关联的两条从表数据并删除,使用sql profiler能监测到如下sql:

第一条是删除主表的数据,后两条是删除相关联从表数据的sql。这种级联删除稍显麻烦,同时加载了相关联从表的数据到内存中再发送删除命令到数据库。其实只需要加载要删除的主表记录到内存中就可以了,因为数据库已经打开了级联删除,只需要发送删除主表数据的指令到数据库,数据库会自动删除相关联的从表记录。可以监控到如下sql:

exec sp_executesql N‘SELECT
[Project2].[DestinationId] AS [DestinationId],
[Project2].[Name] AS [Name],
[Project2].[Country] AS [Country],
[Project2].[Description] AS [Description],
[Project2].[image] AS [image],
[Project2].[C1] AS [C1],
[Project2].[LodgingId] AS [LodgingId],
[Project2].[Name1] AS [Name1],
[Project2].[Owner] AS [Owner],
[Project2].[IsResort] AS [IsResort],
[Project2].[MilesFromNearestAirport] AS [MilesFromNearestAirport],
[Project2].[PrimaryContact_PersonId] AS [PrimaryContact_PersonId],
[Project2].[SecondaryContact_PersonId] AS [SecondaryContact_PersonId],
[Project2].[DestinationId1] AS [DestinationId1]
FROM ( SELECT
[Limit1].[DestinationId] AS [DestinationId],
[Limit1].[Name] AS [Name],
[Limit1].[Country] AS [Country],
[Limit1].[Description] AS [Description],
[Limit1].[image] AS [image],
[Extent2].[LodgingId] AS [LodgingId],
[Extent2].[Name] AS [Name1],
[Extent2].[Owner] AS [Owner],
[Extent2].[IsResort] AS [IsResort],
[Extent2].[MilesFromNearestAirport] AS [MilesFromNearestAirport],
[Extent2].[PrimaryContact_PersonId] AS [PrimaryContact_PersonId],
[Extent2].[SecondaryContact_PersonId] AS [SecondaryContact_PersonId],
[Extent2].[DestinationId] AS [DestinationId1],
CASE WHEN ([Extent2].[LodgingId] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1]
FROM (SELECT TOP (2)
[Extent1].[DestinationId] AS [DestinationId],
[Extent1].[Name] AS [Name],
[Extent1].[Country] AS [Country],
[Extent1].[Description] AS [Description],
[Extent1].[image] AS [image]
FROM [dbo].[Destinations] AS [Extent1]
WHERE [Extent1].[DestinationId] = @p__linq__0 ) AS [Limit1]
LEFT OUTER JOIN [dbo].[Lodgings] AS [Extent2] ON [Limit1].[DestinationId] = [Extent2].[DestinationId]
) AS [Project2]
ORDER BY [Project2].[DestinationId] ASC, [Project2].[C1] ASC‘,N‘@p__linq__0 int‘,@p__linq__0=3
直接复制到数据库执行查询,发现它会返回一条主表数据和两条相关联的从表数据。除非必须查出外键记录才使用Include贪婪加载,否则千万不要,EF中跟手写ado不一样,很容易生成很冗余的sql。这里其实只需要主键的记录就可以了,修改下方法:
//级联删除(仅加载主键记录)
private static void DeleteDestinationInMemeryAndDbCascade()
{
int destinationId;
using (var context = new CodeFirst.DataAccess.BreakAwayContext())
{
var destination = new CodeFirst.Model.Destination
{
Name = "Sample Destination",
Lodgings = new List<CodeFirst.Model.Lodging>
{
new CodeFirst.Model.Lodging {Name="Lodging One"},
new CodeFirst.Model.Lodging {Name="Lodging Two"}
}
};
context.Destinations.Add(destination);
context.SaveChanges();
destinationId = destination.DestinationId;
}
using (var context = new CodeFirst.DataAccess.BreakAwayContext())
{
var destination = context.Destinations
.Single(d => d.DestinationId == destinationId); //只取一条主键记录
context.Destinations.Remove(destination); //然后移除主键记录,外键记录又数据库级联删除
context.SaveChanges();
}
}
监控的sql干干净净,只会查出主表数据。
exec sp_executesql N‘SELECT TOP (2)
[Extent1].[DestinationId] AS [DestinationId],
[Extent1].[Name] AS [Name],
[Extent1].[Country] AS [Country],
[Extent1].[Description] AS [Description],
[Extent1].[image] AS [image]
FROM [dbo].[Destinations] AS [Extent1]
WHERE [Extent1].[DestinationId] = @p__linq__0‘,N‘@p__linq__0 int‘,@p__linq__0=1
补充:这里只查一条记录却使用SELECT TOP (2)... 是保证能查到记录。
删除sql更干净,只删除主表数据,相关联的从表数据删除由数据库级联删除完成:
exec sp_executesql N‘delete [dbo].[Destinations]
where ([DestinationId] = @0)‘,N‘@0 int‘,@0=1
级联删除虽然方便,但是并不常用。试想我们在博客园写了很多随笔,为不同随笔加了不同的标签好区分和管理。某一天突然发现之前定的某个标签并不合理,但是这个标签已经在很多随笔里用了,如果此时删除标签,数据库级联的把标注此标签的随笔都删了,这个肯定不合适。应该是标签删了,之前贴过此标签的文章没了这个标签,这个才符合逻辑。
数据库里可以可视化的设置不级联删除,Fluent API配置此外键关系时可以设置不级联删除:
this.HasMany(d => d.Lodgings).WithRequired(l => l.Destination)
.Map(l => l.MapKey("DestinationId")) //一对多并指定外键名
.WillCascadeOnDelete(false); // 关闭级联删除
再跑下程序,去看下数据库本外键自然就没了级联删除。
园友郭明锋提供了一个很好的建议:考虑到EF中的级联删除并不常用,所以可以在全局里关掉所有主外键关系的级联删除,如果需要可以打开某个主外键的级联删除。
标签:
原文地址:http://www.cnblogs.com/liangxiaofeng/p/5809568.html